


CyberRisks in DevOps
Are you aware of cyber risks in DevOps and how they can impact your business?
Turn on the DevOps Backup Masterclass Podcast to join our host Gregory Zagraba and explore the biggest cyber threats to DevOps environments, including GitHub, GitLab, Bitbucket, and Jira with an ultimate review of the Top 2023 risks. In order not to leave you in the crosshairs of hackers, human errors, and malicious insiders, he will also get in-depth insights on data protection, backup, Disaster Recovery, and security. In short – he will 💪 empower you with a best practices checklist for cyber resilience and security compliance.
You can read the complete transcript below or watch it on our YouTube channel…
and of course, listen through the Spotify App – don’t forget to subscribe!
TRANSCRIPT – EPISODE 01
Hello, everybody. Good evening. Good morning for those of you who are located in the States. Good evening or good afternoon to you guys in Europe and on the East Coast, if I’m not messing it up. I’m so happy to see you all today.
My name is Greg Zagraba. I’m a pre-sales engineer here at GitProtect, and I’ll have the pleasure today of talking to you a little bit about the DevOps data and security in the DevOps space. We are already a few minutes past the starting time, so I think that without further ado, we can get started.
I wanted to start with a little bit of anecdote, and as a good tech guy, I think it is as good to start a technical presentation as a little bit of Latin. Si vis pacem, para bellum, which can be translated into English – If you want peace, prepare for war. A little bit of story, my sister is a lawyer, and she was always telling me that in terms of preparing any contractual documentation, you should always have this mindset that you are signing the agreement, signing the contract, not for time of peace with the other party, but for the time of war. And
I think that a similar approach should be also taken when thinking about cybersecurity in DevOps. We are very often thinking, okay, we have all those things that we need to prepare. We have this compliance. We have audits. We have those procedures that we are following, and we are thinking, huh, do we really need that? Do we really need to push all of this? Maybe it’s too far. Maybe it’s too much. We are just a small company. No major hacker is going to be interested in us, and so on.
But while thinking about it, we are only thinking about our experience of peace and of the fact that nothing happened so far. We are not thinking about experience of, okay, what will happen if we have a war? What will happen if we have an outage? What will happen if we have a data leak? What will happen if a ransomware attack hit our company? So first thing first, I know that everything that I’ll say today can probably be countered with saying, yeah, but it doesn’t happen [that often in general]. But even though the chances are relatively small, they are not zero. And that’s why we have the whole cybersecurity. We are getting prepared for war.
I wanted to ask you a question, what do you guys think will any service provider, in the DevOps space that you’re working with right now, do in case of war? In case of you losing access to some of your data or all of your data? In case of you experiencing an outage? In case of you experiencing the ransomware attack? The answer is nothing. And you can say that, yes, this is a little bit of over-exaggeration. And that is correct, because they try to do something. But their policies and their terms of service are protecting them from doing anything or obligation to do anything. Like if they do it, they’ll do it because they are nice. But they are not going to do it because they have to. And this whole concept is called nicely shared responsibility model. And I love how it is named because when we are saying about sharing something, we think that, OK, we’re sharing something with our friends, with our close ones. But sharing responsibility is not really that nice. Because, sharing responsibility basically means that while service providers are taking responsibility for their platforms in terms of hosting, in terms of application, and systems running properly. Everything that you put on the system or everything that you allow to appear in the system, like Marketplace app, is your own responsibility. What your users are doing in your platform is your responsibility. Your data is your responsibility. Whether you are staying compliant in your data management in their platform is your responsibility. So we [provider] are openly saying it in terms of service, you are responsible for all of this. We only keep what constitutes our business. But what you do in our platform, we don’t care about it. We don’t care about it that much. And we won’t help you in most of the cases when you have some issue. That’s why first thing first about getting into DevOps space, because very often I hear, OK, but I’m using my cloud vendor, Atlassian convinced me to go cloud. I’m using GitLab cloud. I’m using GitHub cloud because we are taking care of the security aspect. We are taking care of the hosting. I don’t have my own server. I’m not even using my own data center. They do this stuff for me – But even though we [provider] do this stuff for you, we are not taking responsibility of you.
And that’s why the whole discussion about cyber risk in DevOps is first of all, staying aware that it’s your role to maintain it. And luckily, there is a movement of educating people about it. We more often talk about DevSecOps instead of just DevOps to add this security part as part of our DevOps procedures.
And if you want, if you if I would like to you to get something out of our position, just one thing is to start thinking about security in your DevOps process and about your data security in general. And today I’m going to share with you what are the top risks that you should be aware of in terms of in terms of your DevOps data security. So what things can happen? And then I’m going to tell you what are some remedies to those risks.
DevOps threats examined
So if you have some sort of incident, if the war does happen, what you are able to do with that. So first of all, let’s talk a little bit about DevOps data loss risk. So what can cause you to to experience data loss of some way? So what can disrupt your work in the DevOps space? Executive summary is not a rocket science.
Those are things that you’ve probably heard about external threats such as malicious actors and ransomware attacks, human error and accidental deletion, service outages and downtime. So those are all the things that we are familiar with. But what are the some specific cases that we should look into?
The first one and my favorite is a little bit of game. Can you guys guess, what are those numbers? What those numbers mean, what they stand for? I can only tell you that they are related to data security DevOps in some way, especially to the scope of the last year.

Those numbers are numbers of security incidents that specific DevOps service providers experienced in 2023. Which basically means that they had security incident two times per week on average, which probably can be scary.
Obviously, the scale of those incidents differs. And I’ve just highlighted a couple of those. Those incidents are sometimes starting from something that can seem quite minor, like

Note that, even if they have all those nice certificates, and even if they are doing a great job at remaining compliant, they can still have a huge number of incidents happening.
Scale of those can be very different. But as you can see, for example, in case of GitLab, they reached the CVSS score of 10 in one of their incidents, meaning that it was the heaviest one possible. What it tells us? It tells us that what we should do is that we should start asking ourselves, OK, we operate with this platform, but what are we going to do if our vendor is going to mess up? What are we going to do if GitLab has an outage, if GitHub has an outage, if Atlassian has an outage? And we’ve already seen in history outages lasting up to two weeks.
They haven’t affected everybody, but they have affected some of the people. So it shows us pretty clearly that our trust for those [providers] should be limited. So many of you will say to me right now, OK, Greg, so if I can’t trust my cloud service provider, I should switch to my on-prem installation. I should go over to Jira Data Center. I should go for GitHub self-manage, for GitLab self-manage. And yes, many companies do so, but your system administrator will always tell you that they cannot give you 100% warranty that everything’s going to work 24/7 all the time.
Again, risk of failure is relatively low, but it can still happen. We still hear about disk failures happening in our servers. We still hear about the network issues that cause data transfer disruption. We hear about bugs and glitches in the software that you’re using to maintain your databases, and data corruption is still a common thing. Does it happen every day? No, it doesn’t, but the chances are not zero. And as we established at the very beginning, we need to be prepared for the worst possible scenario.
So even the fact that you have your own infrastructure and you’re hosting everything on it, it doesn’t mean that your infrastructure is not something that can fail. And if it fails, your risk of losing your DevOps data and risk of losing continuity of work in your software development department, is still there.
The next thing, and this is our most common threat that occurs, is human error. Because we can say, okay, even if we work with the best cloud vendor there is, or even if we have top-notch infrastructure, which is the safest possible, there is still a possibility that somebody personally will mess up along the way. I cannot say how many times I’ve seen somebody deleting something by accident. Jira is the king here because people tend to delete attachments by accident all the time.
If you are making some bulk changes to the platform by bulk export or bulk import, there is a risk of messing up the data. We can have conflicting pull requests that cause some data inconsistency or data corruption. There is multiple things that can happen.
I wanted to share one scenario that one of the customers I’ve been working with experienced some time ago. I’m not going to mention the customer by name, but it was a pretty interesting story because it showed how little is needed to lose access to your whole source code, or how careless people can be. Basically, what our company has done, or what company of one of our customers has done to be specific, they hired a subcontractor to work on software development.
They have been working on a mobile app, and to speed up the process of development, they hired an external contractor to work on it. Contractor was super nice and super helpful, or at least it seemed that way. They offered that, hey guys, we are going to help you with automatic deployment of your application with every upgrade. We’ll establish AWS account for you, and we’ll establish automations to connect your GitHub with your AWS to make automated deployment. For this, we need appropriate permissions in the GitHub account. What our careless GitHub admin has done, they thought, oh, I’m not sure what permissions specifically they need. I’m just going to make them admin. I’m not going to make them admin, I’m going to make them owner. They will have access to everything, and they’ll set up what I need.
A few weeks later, there is a dispute between subcontractor and the company that hired him on the quality of work, which can happen always. I’m sure that more than one time, you’ve been subcontracting something, and you had some dispute with your subcontractor. Sometimes, as a part of this dispute, we say, okay, you know what? I’m not going to talk with you. We are not going to argue. I’m withholding the payment until you fix what I want you to fix. Typically, in such a case, subcontractor either has to fix what we are asking them for, or subcontractor takes us to court.
There are only two options here. However, our subcontractor had a third option, unfortunately, because he got mad and he abused his admin privileges and cut off everyone else from GitHub. Suddenly, the company lost access to their whole source code. All the GitHub, all the source code has been lost. To mention, that subcontractor also had access to AWS, so app deployment has been lost as well. All the money that companies spend on software development has been now gone.
I can mention that there is a good ending to this story. I’ll tell later how it was achieved. But if we were to end here today, the company would have a massive issue. I can tell you that I know that the company owner has been berated by investors for his carelessness in dealing with subcontractors.
As you can see, even if you think that you’re a responsible company owner, mistakes can happen. Sometimes, even somebody with tons of experience, and trust me, the guy that was running this company, the guy that was managing GitHub on this company wasn’t a junior. Issues like this can happen for everybody.
Then the next thing, ransomware, which is to some degree connected with accidental deletion and with human errors, because many, many times, we are the people that leave opening for ransomware attacks. But sometimes opening is in the platform – Service provider makes an opening because of the error in their software or vulnerability in their software. Many, many times, companies say, okay, but we are too small to be target of ransomware attack. If you’re a power plant, or if you are a Fortune 500 company, then yes, for sure, ransomware can touch me.
However, Malwarebytes report from 2017 told us that 35% of small and medium businesses worldwide have been victims of ransomware attack, and 90% of attacks ended up with over one hour long downtimes. Obviously, those attacks hitting small and medium businesses, they are not truly targeted attacks. Typically, they are exploiting vulnerability which exists in a certain platform. Such incidents did happen last year. They happened in GitLab. They happened in Atlassian. I’m 100% confident, unfortunately, that they will happen this year as well. We need to be aware that ransomware is not only something that applies to big guys. It can apply to everybody.
So as you can see, we have different verticals of those risks. And even if we say that, okay, the risk of those happening is not that big, the risk is small. And here I have one example coming from the big guys league, that has caused a lot of discussion in the industry – the incident that Mercedes-Benz faced on the verge of 2023-2024. So in September last year, researchers from Red Hand Lab discovered that various mishandled GitHub token in public repository that belongs to Mercedes employee, and that mishandled token gave access to internal GitHub enterprise server of the whole Mercedes-Benz. This token was also generated with a little bit of carelessness in setting up rights and privileges, because it gave unrestricted and unmonitored access to entire source code that was sitting there.
And information about the leak has reached Mercedes-Benz in January 2024, four months after the token has been discovered. So for over four months, somebody could have used this token, first of all, to leak the source code of Mercedes-Benz from their IoT systems that they use in their cars, for example. Or, and we don’t really know up to this day if it was leaked or not, because the token was unmonitored.
The malicious actor could have deleted the source code. Luckily, they didn’t do that, but it was possible. So it shows us nicely that, again, minor mistake, mishandled personal access token, can cause us to have major leakage of our code. And it opened companies such as Mercedes-Benz, who I’m sure has a wall full of security certificates. You’re losing a huge part of our source code by somebody maliciously deleting all the source code using such vulnerability.
So we’re coming here to a conclusion about how (not) to eliminate data loss. And there is one thing that I always say, there is no possibility of preventing data loss with 100% certainty in what we’re doing. The reason for that is pretty simple, because even if we prepare for certain scenario, even if we protect from everything that can happen in ransomware, even if we went with the safest cloud service provider there is, and we are auditing this cloud service provider every six months, or if we are maintaining top-notch infrastructure where we are hosting our data, including our DevOps data, there is something that can happen that can cause us to lose our data. And human errors are a great example of that, because humans are so unpredictable, and there’s always a chance of somebody finding some opening to either delete something on purpose, or delete something by accident, or cause a data outage in some way. Because sometimes a small mistake can cause a massive effect. Like in 2017, when GitLab had this outage that lasted over two weeks, it happened because of human error. Somebody made data dump on a database carelessly, and they haven’t realize that they crashed the whole GitLab architecture.
So we come to this conclusion that, okay, we need to protect our data, because we need to be prepared for the times of war. There’s tons of risks, more than we can discuss during our meeting today. And at the end of the day, there’s still nothing that we can do to prevent data loss with 100% warranty.
That’s why I’m a huge fan of having a backup. Because even if you lose access to your data, to your infrastructure, something gets deleted by accident, you get cut off of your data for the malicious actor, either as a result of ransomware attack, or as a result of your subcontractor being angry at you. In any of those scenarios, even if you are completely cut off from your data, even if you lost your data, majority of it, part of it, all of it, if you have properly implemented backup strategy, this data can always come back.
DevOps myths that put your data at risk
I don’t need to backup my git…
And because we neglect security in DevOps, typically, we also neglect backups in DevOps as well. And here, I’d like to move forward to discussion about the backups of your DevOps data. Backups of your repositories, backups of your metadata, like pull requests, issues, projects, etc. And whether you are running a backup at your company or not.
Because very often, what I hear from companies is that I don’t need to backup my kit. Like, yes, we are working with a software, we are either software development company, we have software product, we have software component in our product, if you are working, let’s say, in electronics, or we are financial institution that uses software to very day-to-day operations. – You have some software or software development or software maintenance team. But later on, somebody says, I don’t need to backup my git. Why is that? Because, you know, my repositories are decentralized. There are repositories on, there is a copy of repositories on the laptop of every of my developer. I’ve never lost, actually, any data. So what is the risk of me losing the data? Or, you know, from time to time, my developers, when they have free time, they are tasked with running a copy using a script.
I can create my own script…
This is something that one of the customers actually told me that, you know, for the time being, my developers have the task that if they have some free time, they are supposed to run a backup script. And I asked him, okay, so how often your developers have free time? He wasn’t able to answer me this question. And with the scripts, there’s also a tricky part because even if you say that, okay, I’m backing up my repos with my own script, I’m using Git clone to copy it – you can do it, but you don’t really want to. There was a study made on the script backups done of GitHub specifically. And the results showed us that the copy was on average six months old, meaning that if you would have outage today, ransomware attack today, last six months of your work would be probably gone if you rely on scripts.
And you can convince me that you’re not this type of person and you are doing your backups with scripts weekly. But even if you’re really doing it, and I’m happy to challenge you on this, there is still a chance that week worth of your developers team work and effort is gone. And the question is, how much week worth of development in your company costs? Does it cost $1,000, $2,000? I think with current salaries in the IT industry, it can be much more.
And obviously the Git copy that you are doing with a script, it consists of the source code typically, but it doesn’t cover all of the metadata. All the issues, all the pull requests, all the projects, all the deployment keys, many of those copies don’t even include LFS. Not to mention things like settings of your repositories.
In GitHub, we have things like branch protection rules, automations, dependable settings, which are quite important. They’re a huge chunk of your work. If I would ask one of you today to recreate your GitHub actions configuration from scratch, you wouldn’t be happy person.
Yet your backups typically don’t cover this part. The second thing people are saying, hey, I’m keeping my repos on my developer’s computers. Yes, you are, but not all of them. Probably not always the latest version. And how long would it take you to reach out to everybody, gather all the copies from them, compare them and end up with a version that you’re confident is that the latest version? Would it take you a day, two days, maybe more? What if somebody’s on holidays? What if we have holiday season? Lots of attacks actually happens during the holiday season, during the Easter and during the Christmas. So what are you going to do then? And at the end of the day, running backup with a script or gathering the data manually from developer’s computers is manual effort that costs you extra time, that costs you extra effort.It’s not productive time because this is probably something that can be automated in your company.
Service Provider protects my data with their backup…
Okay, but somebody will say, huh, why do I even backup my repositories? Why do I even use Git clone on script? I’m sitting with my cloud vendor and they for sure run backup over a whole infrastructure. And okay, there is a shared responsibility model. They say that they’re not going to, they’re not taking responsibility of my data. That’s fair. But they still need to make backup even for the internal needs. Meaning that if I ask them really nice, really nicely, they are going to help me restore my data. I’ll write on the support. I explain the situation. I’ll tell it was ransomware attack that I had no impact on and they need to help me. Unfortunately, if you look into their policy, probably they are saying there that we’re not going to do it.
This screenshot here is something that Atlassian send back to one of our customers after they reach out to them, asking, hey guys, can you help us using your own backups?
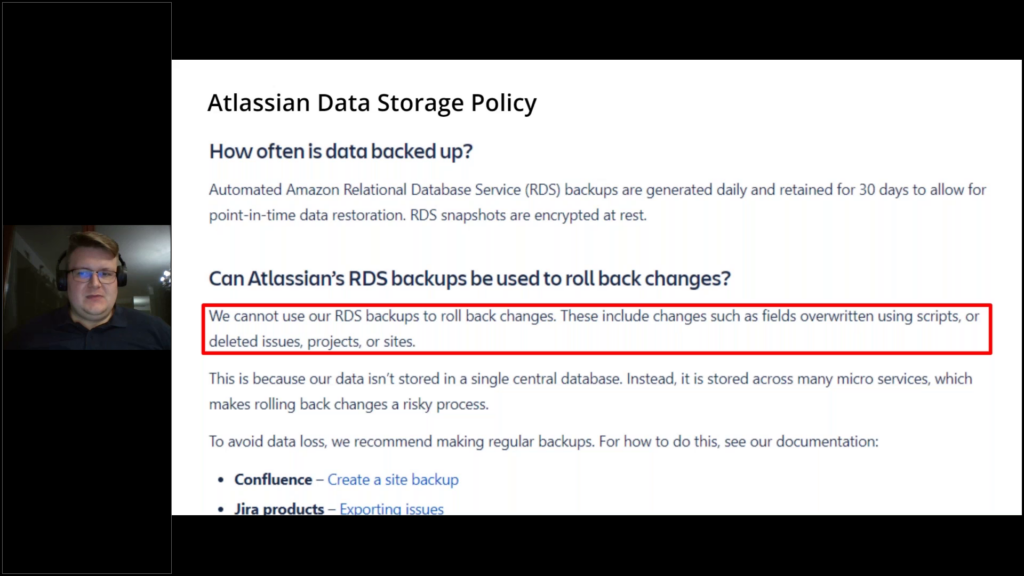
That was after the customer due to human error, due to mistake with bulk import of the data. Wiped all the attachments from their Jira account. And they asked them nicely, hey guys, can you help us? We’ve made a mistake, you know, our fault, but please help us. And Atlassian was like, yeah, we are running the backups, but we are not using backups to roll back changes.
Those are snapshots and we are not able to extract only your data from it. And we have no incentive in helping you. Which means that yes, even though those backups are in place, you can’t really trust them.
Because vendor is saying, we are not have no responsibility to help you. We are open about it, but we are never reading terms and conditions. I admit, I’m not doing it myself too often.
Backup script is not equal restore capability
So sometimes people are saying, okay, but you know, at the end of the day, I probably can create some tool internally to run those backups. Like I can take my DevOps guys and tell them, guys, we, you know, I’ve been on this webinar, guy told me, we need to start backing up our DevOps. We need to start backing up our Bitfucket. We need to start backing up our Jira. We need to start backing up our GitHub. Yeah, we need to do it. You need to write some program that will pull the data for the API and create the backup, create the copy. And you talk to those guys with it. And let’s say that those guys are hardworking, honest people. They sit down, they do it. You create those copies. You pull the data out of the platform. You make the copy. You put it in your S3 bucket. You put it in your Glacier on AWS. And one day the situation comes in when you actually have an outage. Or let’s say you had data loss. Somebody deleted very important project from your GitHub. And then you say, luckily, I have my backup in place. I’m safe. I’ve been on this webinar six months ago. They told me to make backups. We’ve made the backups. I’m safe.
But what people are forgetting about is restore. Backup is only as good as your restore strategy. And this is pretty funny because this is actually what failed in 2017 GitLab outage. They made data dump. They lost their major database. They had backup of it. But the restore strategy failed. This backup wasn’t tested. It didn’t work as intended.
So having backup is only 30% of the success. Having a restore strategy in place is crucial. And restore strategy is something where you need to actually consider multiple factors and multiple scenarios.
You need to be able to restore data to your own account. You need to be able to restore data to some other platform in case the platform that using has an outage. You need to be able to come back in time and restore a copy from three months ago. You need to be able to restore only specific object that you’re after, et cetera. And there is tons of scenarios. And the question is, without providing you the slide, how many of you would be able to name all of those? Probably not everyone.
I’m tempted to say that most of you wouldn’t be able because only people that are aware of all the scenarios that can happen, or at least most of them, are people who are specialized in backup. So maybe your Sys Admin knows. Fingers crossed.
But people in DevOps, sorry guys to break it to you, but you typically don’t know it. But we’re here to help. That’s why we provide solution for the automated backup and disaster recovery of DevOps infrastructure.
Main pillars of a backup strategy
But we’ll get to that in the moment. Now I wanted to speak with you about pillars of your backup strategy. So let’s say, fingers crossed, I convince you to have a backup of your DevOps data. I convince you to backup your GitHub, your GitLab, your Jira, whatever you are working with. But what do you really need to do while setting up the backup? What do you need to think about?
Backup needs and data coverage
First of all, you need to think about data you backup. And the good backup is backup with the widest possible coverage. Ask yourself, what are the tools that we are working with? Okay, we utilize GitHub, we utilize Jira. Is it only this? Actually, we know there is this one team working in support. They do some stuff, they write some implications in Bitbucket. So Bitbucket too. Is this only that? We have legacy deployment on-prem as well. Okay, are you using it? From time to time. Okay, so it’s also part of it. So you need to think about the whole spectrum of your DevOps tools that you’re using and backup all of them. Because if you keep them for the time being, it means that you keep them for a reason.
You might need them one day. So if you might need them one day, you need backup of them as well. The second thing is asking yourself, what data out of those systems we should backup? And there are obvious things like, okay, we need to backup our source code or from Jira, we need to backup our tickets. But when we need to start prioritizing which projects from GitHub are most important, which projects from Jira are the most important, which metadata are the most needed for us to keep our work. So let’s say that today, we are cutting you off from GitHub and you need to start using GitHub from scratch with completely empty account. But you can recover part of your data, which data you want inside of your GitHub. Oh man, I need my pull requests. Without those, I have no history of what was happening. I need issues. I need history of tasks and communications. I need my deployment piece, et cetera, et cetera. And it’s actually quite good exercise to have this workshop internally with your software team leaders to discuss, okay, guys, let’s have this hypothetical scenario – you’ve lost access to our GitHub,
- What information or which products do you need to continue working, like the outage never happened, or to get back to work as soon as possible?
Because at the end of the day, recovery is typically about getting back to work as soon as possible with as much data as possible, not necessarily everything.
Storing data and storage location
Later on, we come to the point of storage of your data. So, okay, you’ve made your backup. Where are you going to keep them? Probably keeping it in the same infrastructure when you’re hosting is not a good idea. So probably it will be good to have some external storage. Should it be cloud? Should it be on-prem? Should it be both? You need to think about it. Maybe it should be more than one storage. Maybe I should have one storage and replicate the content of this storage every couple of days to another storage.
So even if I keep my data in my S3 bit buckets, even if AWS has an outage, I have my backups kept in some other location. Maybe it’s worth to keep one server somewhere on-prem as well. So you need to think about where we are keeping the data.
It should be more than one location, spoiler alert, and also in what format you’re keeping the data is important. One of these disadvantages of making backup with a script is the fact that those data are typically not encrypted in any way. You should also consider how are we going to encrypt our backup data and maybe we should put them in some file system that chunks them.
So even if somebody puts their hands on our data, they’re not able to recover anything from it without our encryption key and without specialized software for doing that. Maybe what should you consider also is making sure that your storage is immutable. Immutable storage is a type of storage in which you can write data into once, you can read only from it, but you cannot make changes to the storage later on.
Meaning that even if some malicious actor like this angry subcontractor put hands on your storage, they are not able to wipe it. So again, multiple scenarios to think about.
Disaster recovery
Next thing is our disaster recovery scenario, something that we’ve touched upon. And there is again multiple scenarios that you need to consider. So what can possibly happen to our DevOps infrastructure and how we will recover from it. And what makes reliable disaster recovery solution? So what scenarios you should take into consideration?
First of all, being prepared for the outage, being prepared for GitHub, GitLab going down. You should be able to make cross-restore to another platform. So if GitHub has an outage, after 48 hours of outage, you can say, okay guys, for the time being, we are switching to GitLab because it [outage] lasts for 48 hours already. We have no confidence that it will come back in the next 24. For the time being, we are restoring our data back to GitLab to continue working there.
Or very common scenario, you have outage of cloud and you’re restoring data into your on-prem instance. We have GitHub self-managed instance. We are not doing anything with it on a daily basis. But in case of outage, we are restoring our cloud data into it so we can continue working there.
Another thing, priority for us is getting back to work as soon as possible. Our boss is telling us, guys, every hour costs us 20 grand. We cannot wait any longer for our platform to come back live. Okay, then you want to be able to granularly restore most important data, but without overwriting anything that’s already in place. Let’s say you’ve lost 80% of your data from your GitHub account. You say, okay, we want to have restore and we want to restore most of our data. But we don’t want to just bring back the whole instance with a script because our last script backup was done a week ago and we’ll lose a week worth of data.
We want to be able to restore the things that we need to continue working and we want to continue working with only those things without disrupting the rest because maybe in this instance, there is something that we want to keep using. I have actually pretty interesting story about such a scenario. One of the companies I’m, let’s say, friends with has been using Jira for their operations and during the update of their Jira, that was Jira Server, they had an outage that resulted in data loss and that happened in the afternoon and as a result of it, they lost the whole day worth of data because they wanted to restore from their backup that they’ve done in the morning.
The data loss happened in the afternoon. The data loss happened only on part of the legacy data, but they were only able to restore from the backup that was covering the whole instance, meaning that they lost the whole day worth of data from Jira. So everything that people done during the day, it went to trash because they used outdated backup.
Another thing, if you lost access to your account, so my favorite scenario with our angry subcontractor, then first of all… If you have backup of your GitHub instance, like this customer did, you are able to make a restore and even if you lost your original account. You want to be able to restore to the completely different new account – and that’s what we’ve done with this customer actually. During the call, customer created with us free GitHub account and they restored data into it from their backup and they could have continued working without losing their source code. So that was a great example of how backup can be beneficial in cases like we have malicious actors or we realize too late that certain data has been lost. For example, I had a customer changed permissions of one of the users in their GitHub and they realized they haven’t been backing up their deployment keys for over two weeks and normally, if you are limited to using only your latest copy in restore, you are not able to retrieve those deployment keys because you haven’t been protecting them for the last two weeks.
However, with point-in-time restore, you’re able to come back to copy you’ve done months ago or three weeks ago and restore this specific data that you’re looking for from it. So again, multiple different scenarios that your backup strategy should consider and last but not least, having overview of your backups because many, many of the people, when they work with backup, even if they have great disaster recovery strategy in place, they make a backup, they put it nicely encrypted, protected in super secure storage and they have replication of the storage, but they never look into this backup until it’s needed. You should be able, first of all, to access your backups from anywhere in the world because sometimes your boss might call you on holidays and tell you that, hey, we have an outage, I need your help, stop.
Testing
You should be able to monitor your backups. You should be able to see if we pulled all the data we need from GitHub. Is our backup up to standard? Is our backup working? Do I have somebody else in the office who is able to assist me with restoring the data while I’m on holidays and my boss is calling me half scared, half angry? So those are all those things that we need to consider for the backup. You need to have overview of your backups, access to them at all the time and you need to be sure that they are working.
The huge thing that many people are also forgetting about is testing your backup. So, hey, you’ve done your backup, you’re happy with it, you have no outages, but hey, maybe once a month, maybe once a quarter if you’re busy, create empty sandbox account, try restoring data into it from one of your backups and make sure it’s up to standard.
Make sure that the restore time is something acceptable for you. Make sure that you’re restoring enough data and you’re happy with the restored data. There’s nothing missing, there’s nothing lacking, there’s no data corrupted, you have everything you need.
Recovery Time Objective and Recovery Point Objective
And here we come to the question, okay, so what makes a good backup? Because I told you about all those pillars, but one could say that those things are quite subjective or there is many of them, or there’s many different factors to consider. Luckily, there are two metrics that tell us how good your backup is or to be more specific, how good your backup is for you. Those metrics are Recovery Time Objective and Recovery Point Objective.
Recovery Time Objective in a fancy way to describe a maximum acceptable downtime for a system. In practice, it means time during which you need to successfully restore your DevOps organization. You need to restore your data so you can continue working. And question might be, okay, so what RTO should we have? My answer is, you should have one millisecond. You should be able to restore your data in an instant. It’s not possible, but in a perfect scenario, you should be able to restore it in an instant.
In the real world, however, what you need to do is first of all, test how long does it take you to restore data from your backup. And then ask your business stakeholders, ask your project managers, team leads, software engineering leads, hey guys, we’ve tested that we are able to recover all the data within eight hours or twelve hours, (depending on the size of organization that you’re working with, data, infrastructure, et cetera). And they will tell you, okay, eight hours is not perfect, but we can live with that. Or they can tell you, no, eight hours is way too long. It costs the whole business day. That’s unacceptable. So then you can negotiate with them okay, so maybe out of all this data, there is something that is super important or something that is really necessary for us to continue working. And maybe we can restore those mission critical data first in a shorter period of time. And then we restore the rest. But to be able to negotiate with them, you also need to be able to make granular restore.
So here we get to covering all those different disaster recovery scenarios. And here we’re also touching about the second metric, which is Recovery Point Objective, a maximum amount of data loss that organization can tolerate. Or to put it in simpler words, how many hours worth of data we can lose yet remain operational? Like if we lose one hour’s worth of data, does it affect our business? If we lose six hours’ worth of data, does it affect our business? If we lose one week’s worth of our data, does it affect our business? And again, here again, this should be one millisecond, but it’s not achievable.
Because RPO typically tells you how often you should run a backup. But in practice, you’re not able to run backup every millisecond. And probably you’re not even able to run a backup every hour because backup duration itself very often is longer than an hour for large organizations.
But you should negotiate and establish this with your stakeholders. Guys, if we lose one day worth of data, is it acceptable for us? Yeah, we can take overtime. We can push ourselves to the limit. We can catch up with it. Or they can say, you know, eight hours is a lot. Can we cut it down to four? And then you start negotiating again.
Okay, so maybe we should be making backups more often. But those backups that run more often should be only of mission-critical data. So we start looking into our DevOps infrastructure and we start separating things that matter from things that are fillers.
Very often, I’m talking to companies that have around 1,000 repositories in their infrastructure. And typically out of 1,000 repositories, 200 to 300 of the repositories that actually matter. And the rest is something that they consider archived.
Okay, so would it be okay if we backup archives on a weekly basis and the rest we backup daily or twice per day? Yeah, sure, why not? And then suddenly doing daily backup or the backup twice per day of 200 repos is something realistic. And daily backup of 1,000 repos is possible, but it’s much easier if we do it for 200 repos. But to achieve this all and to be able to negotiate with your stakeholders, you need solution flexibly enough.
And when somebody tells me, okay, I can do it with a script, but with a script, can you restore only part of the data? Can you restore only mission-critical data and then the rest? No, I’m only able to restore the whole org, too bad. Are you able to backup those critical data every few hours? No, I would have to have junior on standby running script every few hours, too bad. So you need to have solution flexible enough to meet those.
Summary
So if after our meeting today, you tell yourself, okay, I think I want to have backup in place. Start asking yourself,
- is it flexible enough?
- Does it allow me for granular restore of the data?
- Am I able to set up my own frequency of backups so I can do more frequent backups of the data that matter?
- Am I able to test my backup, make test restore to some sandbox account to make sure that it’s working properly?
- Am I able to pick only mission-critical data in smaller backup and run those backups more often?
- Am I able to make point-in-time restore and come back three weeks in time to point when I know that this deployment key was there, but now it’s not there?
- Am I able to work with multiple storages? So even if my S3 bucket goes to how I’m able to restore data from something else.
- Am I able to monitor my backups and make sure that it’s working properly, to have some actual real-time notification like, hey, there is this project or this data that we haven’t protected, look into it.
And how all of this can be achieved? I don’t want to make a sales pitch here, but what I want you to do is to encourage you to educate further because what I’ve done today, I only scratched the surface of the whole topic of DevOps data security and DevOps backup. I’m from a company called GitProtect.io and if you found this topic interesting, I encourage you to go to our website, GitProtect.io and there are two important things you’ll find there. First of all, if you like drama stories, go to our blog. We have articles for summary of security incidents of different platforms in 2023 for GitHub, GitLab, Atlassian. So you can read about all those incidents I mentioned today. And secondly, we have backup best practices that you can download from our website where you can find information on how to set up a good enough backup for your Bitbucket, for your GitLab, for your Jira, for your GitHub, etc.
And obviously, if you want to know more on this topic, or would like to have a guide through this whole process of making your DevOps infrastructure stable, feel free to reach out to me or either approach me on LinkedIn or go to our website, GitProtect.io. There is a contact form and there is a huge chance that I’ll be the guy that you’ll be talking to. So let’s stay in touch. I’m looking forward to meeting all of you and keeping your repos safe.
Have a great evening. Have a great rest of the day. Good luck and goodbye.


