


GitProtect’s Report Highlights Cost Of Weak DevOps Pipelines
Imagine launching the year’s most anticipated game—only to have your screen freeze at the climax. Or waiting for your favorite show’s finale, only to encounter a technical error. In the world of DevOps, where time and reliability are everything, outages on platforms like Azure DevOps, GitLab, GitHub, and Jira don’t just cause frustration — they can paralyze the entire software development process.
In this post, we prove that even the most powerful tools have their weak moments and how to manage disruptions that can cost time, money, and nerves. Explore the key findings below or dive into the full version of The CISO’s Guide to DevOps Threats.
Key findings:
- GitHub faced 124 slowdowns, totaling around 800 hours, equivalent to over 100 working days
- Jira with over 266 working days of disrupted performance across different impact levels
- GitLab sees a 21% rise in reported incidents
- Azure DevOps disruptions affected nearly 28% of the standard working year
- Lessons for DevOps platform users
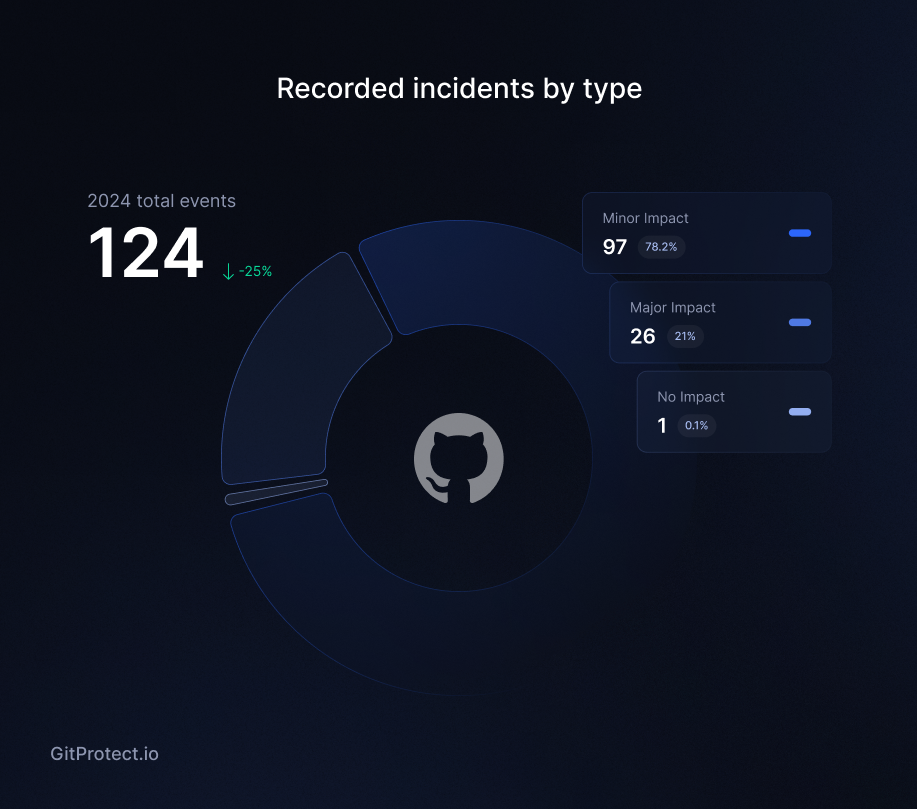
GitHub faced 124 slowdowns, totaling around 800 hours, equivalent to over 100 working days
GitHub serves as a critical backbone for version control, collaboration, and continuous integration and delivery (CI/CD) for over 100 million users worldwide. Any disruptions create global ripple effects, impacting numerous DevOps workflows, CI/CD pipelines, release schedules, and overall team productivity. With such a vast user base, even seemingly minor incidents have the potential to affect millions. Understanding the frequency and severity of these incidents is essential to grasp the operational risks faced by businesses relying on GitHub’s platform.
When GitHub stumbles, global DevOps feels it, and that impact is hard to ignore. While incidents decreased 25% (165 in 2023 → 124 in 2024), users still endured around 800 hours of degraded performance, including:
- 26 major incidents, adding up to over 134 hours of disruptions, equivalent to more than 3 working weeks.
- 97 cases of degraded performance totaling 669 hours, equivalent to 80+ working days or nearly 4 months of impacted productivity.
The third quarter proved particularly challenging, emerging as the year’s peak instability period with 42 recorded incidents of different impacts.
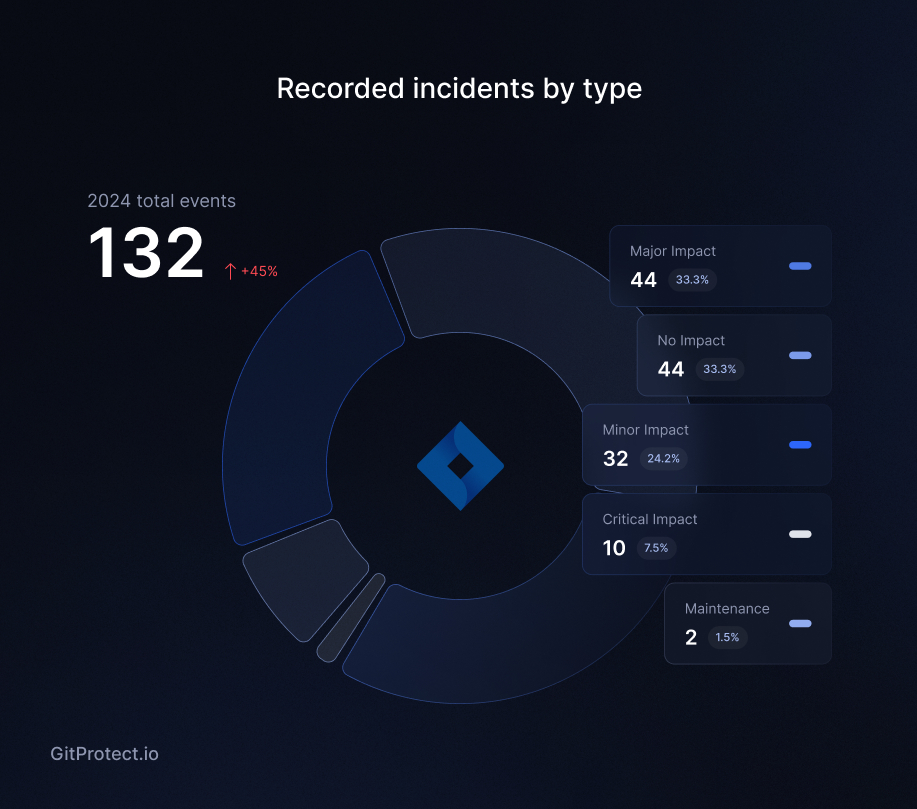
Jira with over 266 working days of disrupted performance across different impact levels
Project tracking and code collaboration tools like Jira and Bitbucket have become the backbone of modern DevOps, but 2024 revealed cracks in their resilience. The growing number of reported incidents, cumulative hours of disruption, and year-over-year increase in failure rates all point to mounting instability across these essential tools.
According to The CISO’s Guide to DevOps Threats, Jira experienced a 44% year-over-year increase in reported incidents, rising from 75 in 2023 to 132 in 2024. Collectively, these incidents—regardless of their severity—amount to over 2,131 hours of downtime, which translates to:
- Approximately 266 working days (based on 8-hour workdays), representing about 73% of the working days in a calendar year.
- About 89 calendar days (24-hour periods), equating to roughly 24% of the entire year.
- When including weekends, 2,131 hours amounts to nearly 13 weeks out of the year’s 52 weeks.
The trend presents concerning news for Jira users: incident numbers show a clear upward trajectory. Compared to 2022 figures, 2024 saw a staggering 63% jump, from just 59 reported cases to 132.
The third quarter proved particularly disruptive, with Jira users experiencing more than 7 hours of critical outages—nearly equivalent to a full workday. This duration would allow a Jira administrator to complete an entire Agile sprint planning session, including backlog grooming, story point estimation, and stakeholder alignment.
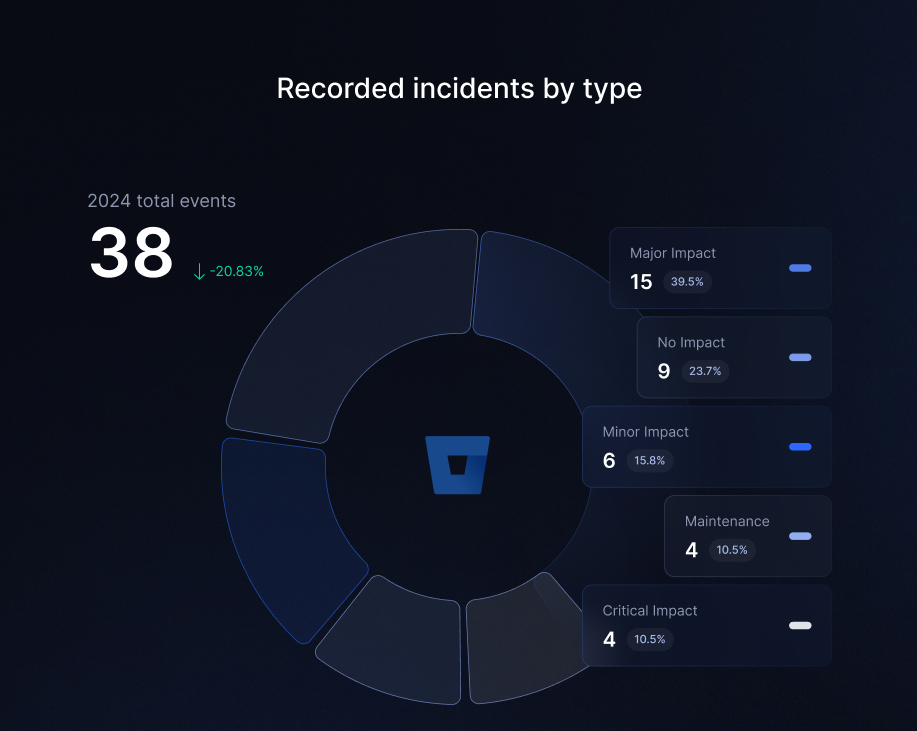
These challenges extended beyond Jira. Bitbucket reported 38 incidents, totaling 110+ hours of disruption of different impacts. To put this in perspective, that’s sufficient time to binge-watch both Breaking Bad (≈49 h) and Better Call Saul (≈61 h) end to end.
And when we factor in maintenance windows, the total rises to nearly 200 hours of disrupted performance — a stark reminder of how much downtime can quietly accumulate over time.
Of that total, over 70 hours were classified as critical or major disruptions — roughly the time it takes to watch the entire Game of Thrones series from start to finish.
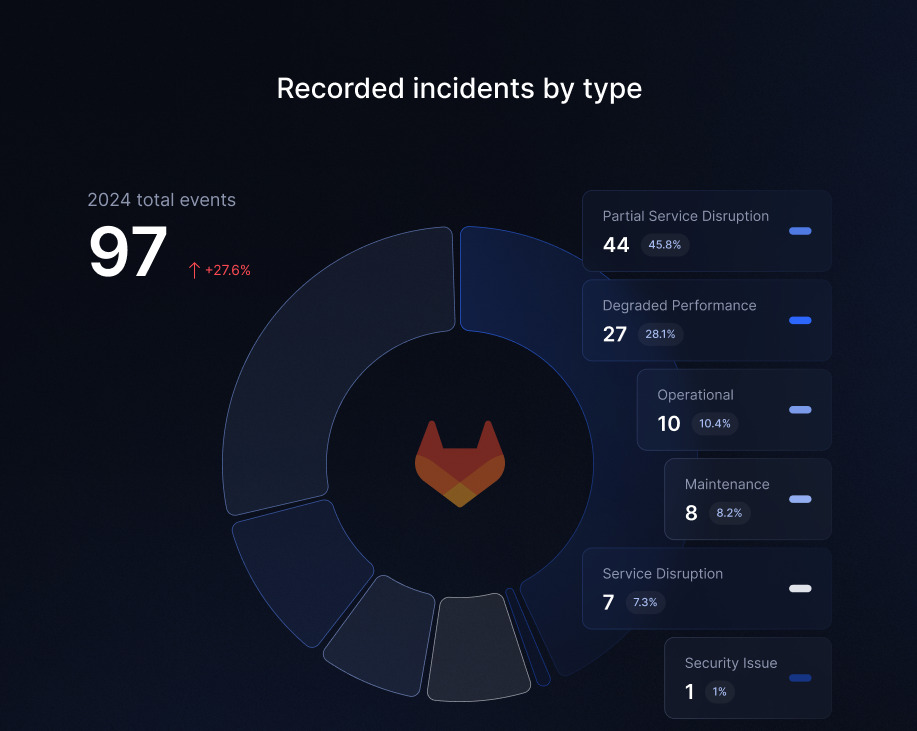
GitLab sees a 21% rise in reported incidents
As DevOps adoption accelerates across industries, platforms like GitLab face mounting pressure to maintain both availability and security at scale. At the same time, GitLab’s incident data tells a clear story: more service outages and more security patches. This mirrors industry-wide DevOps challenges where complexity, automation, and security risks combine to threaten platform stability.
Year-over-year comparisons reveal a 21% increase in incidents between 2023 and 2024, 76 vs. 97 incidents.
Additionally, the platform addressed 153 vulnerabilities while accumulating 798 hours of total service disruption, equivalent to 99 full working days. Notably, just 44 incidents accounted for over 585 hours of partial outages. September proved particularly demanding, with GitLab resolving 21 critical vulnerabilities during this month alone.
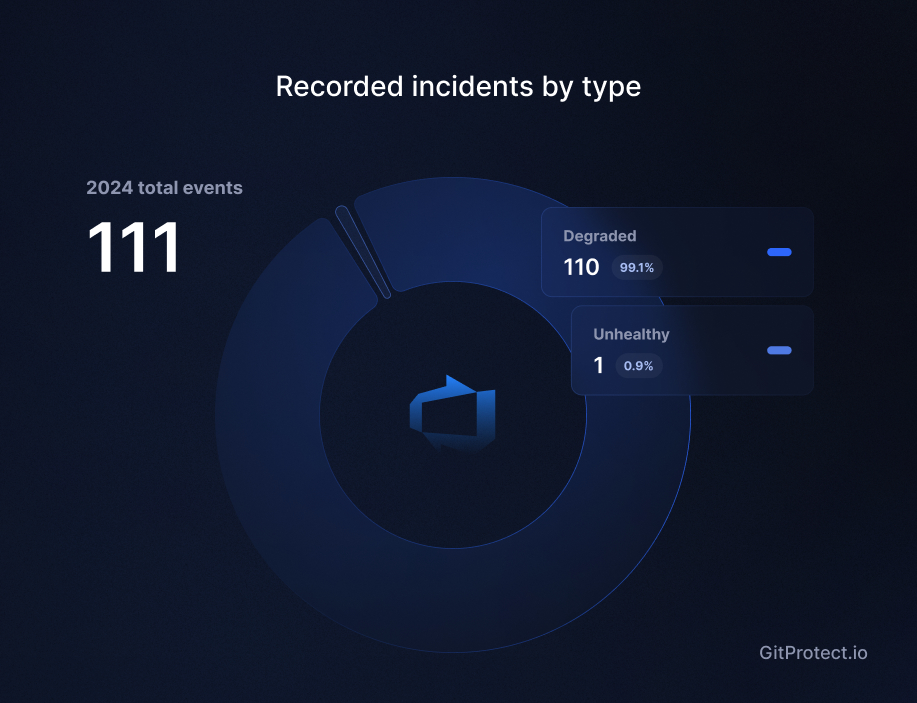
Azure DevOps disruptions affected nearly 28% of the standard working year
As enterprise DevOps pipelines scale in complexity, even providers with massive infrastructure footprints like Microsoft are not exempt from operational strain. Azure DevOps incidents demonstrate that industry leaders aren’t immune to disruptions, with growing numbers of incidents impacting service availability and performance.
The platform recorded 111 incidents affecting services for 826 hours. This translates to:
- 103 standard 8-hour workdays
- Approximately 28% of a typical working year
To contextualize this downtime, developers could have participated in 8 to 10 complete hackathons during these disruption periods.
Lessons for DevOps platform users
Disruptions are not a matter of if, but when. Even the most robust and trusted platforms—GitHub, GitLab, Azure DevOps, Jira—can experience service interruptions that ripple across entire environments. To effectively mitigate these risks, organizations must embrace a proactive, resilience-oriented approach to data protection.
- No platform is immune — plan for failure, not just uptime.
- Backup and disaster recovery are not optional — they’re foundational to business continuity.
- Monitor more than uptime — track performance degradation, API responsiveness, and integration health.
- Time loss compounds — automate repetitive tasks and recovery procedures wherever possible.
- Don’t assume resilience — simulate failures and routinely test recovery processes.
Dive deeper into critical cybersecurity trends with the full version of The CISO’s Guide to DevOps Threats.
What’s there for you:
💡 Analysis of recent attacks on industry leaders,
🔎 North Korea’s growing role in cyber breaches,
📌 Weaponizing DevOps tools,
… and more.



