

Best Practices for Securing Git LFS on GitHub, GitLab, Bitbucket, and Azure DevOps
Git Large File Storage (Git LFS) is an open-source Git extension that handles versioning for large files. It optimizes git repositories by storing data separately from the repository’s core structure, making it much easier for developers to manage binary assets. However, such an efficiency requires proper security and configuration to function optimally.
Utilizing best practices, like access control, encrypted connections, and regular repository maintenance, firmly secures the Git LFS performance. This is especially true when considering platforms like GitHub, GitLab, Bitbucket, and Azure DevOps.
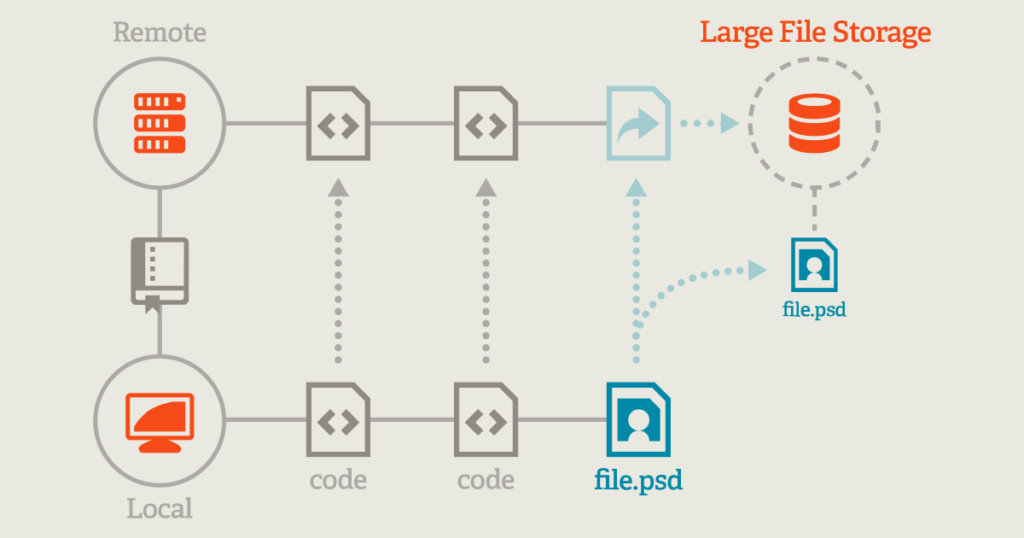
Source: git-lfs.com
What is Git LFS’s purpose?
In short, Git LFS simplifies large file storage using text pointers instead of directly storing (and thus bloating) large files in the Git repository. These pointer files reference the LFS object – the actual binary files – stored in a different location.
Key concepts of using Git Large File Storage (LFS)
Git LFS replaces large files
With Git LFS, the system intercepts large files specified in the configuration and replaces them with pointer files. The actual data is stored externally. However, the repository itself remains light and quick to clone. It is managed through a .gitattributes file that defines all file types to be tracked by Git LFS.
Git LFS objects
These are the large files stored separately. Securing such LFS objects requires specific measures, like encryption and access control, to ensure their safety.
Git LFS objects are large files stored outside the Git repository, typically on a separate server. These objects are critical to the integrity of your project and require special attention when it comes to security.
Two primary measures are crucial to protecting these LFS objects – encryption and access control.
All LFS objects require transfer over encrypted channels, such as HTTPS or SSH, to prevent interception during transmission.
Next to it, encryption at rest is needed on the storage server to safeguard data from unauthorized access.
Role-based access control (RBAC) is vital to limiting who can access or modify these large files. It involves setting strict permissions on both the Git repository and the storage location of LFS objects to ensure that only authorized users can interact with sensitive files.
The .gitattributes configuration file
The .gitattributes file is essential for configuring Git LFS. It allows you to control various aspects of how Git handles specific data (files). Using it, you can customize how files are tracked, diffed (compared), and formatted based on their file extensions or paths within the project.
All these elements are beneficial in cases where a repository contains binary files, text files with a specific format, or when team members are working across different operating systems.
In turn, the .gitattributes significantly simplify project management, especially when working in a team across various platforms and using diverse tools. This way, the file plays a critical role in safeguarding Git LFS with:
- controlled file tracking
- sensitive file exposure prevention
- enforced compliance
- mitigating repository size bloat.
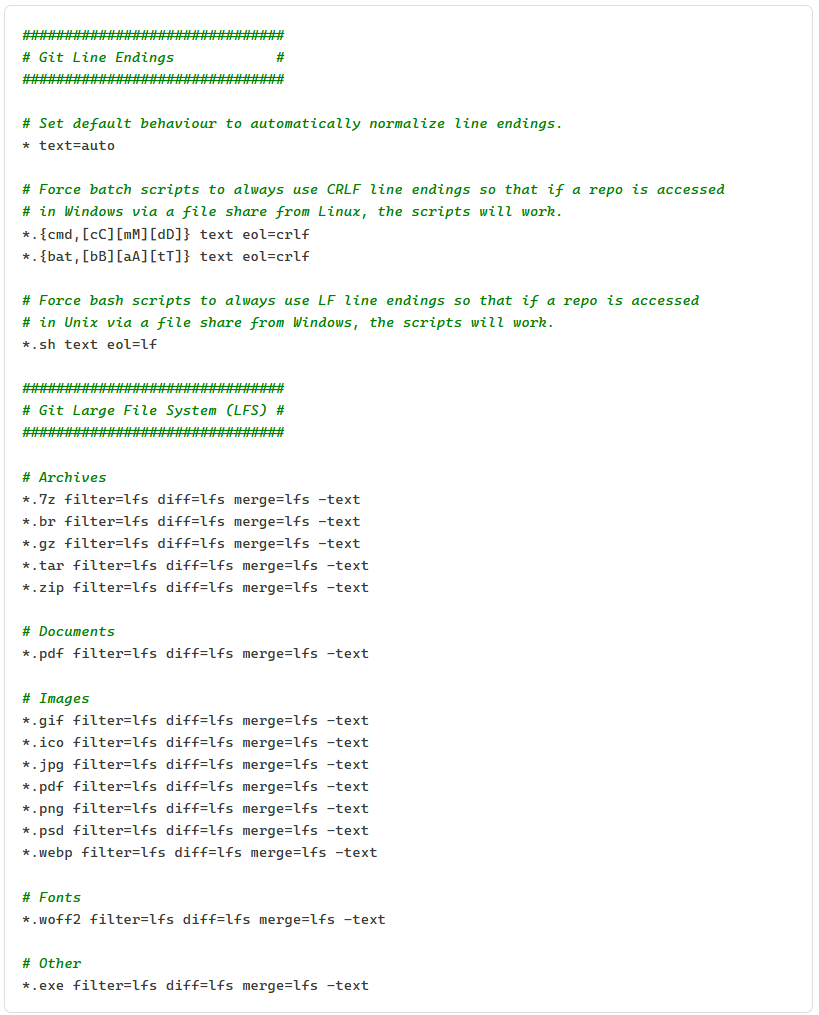
An example of the .gitattributes file contents. Source: M.R. Saeed.
How to configure Git LFS and use it
First, install Git LFS by running the command:
run git lfs installIt initializes the setup in your environment, thus tracking large files. To precise what kind of file types you want to track, use the git lfs track line:
git lfs track "*.xyz"If you want the opposite approach, utilize the Git lfs untrack command.
General best practices for Git Large File Storage (LFS) security
Although Git LFS is a simple yet powerful tool, a few rules should be followed to preserve the solution’s safety and benefits.
Limit what you track
The idea is to use Git LFS only for genuinely large data, like:
- binary files
- video files
- images
- audio samples.
Tracking other files, such as source code or text files (less than 10 MB), with Git LFS can create unnecessary overhead and affect overall performance.
git lfs untrack "*.rb"
git lfs track "*.mp4"Prune unused LFS files (repository size management)
Inefficient handling of large file storage often leads to a bloated repository. To avoid problems, you should prune unwanted or unused LFS objects regularly. It will keep your repository size optimized.
git lfs pruneMismanaging large file storage can result in bloated repositories, which slow down git operations such as clone and pull.
Encryption
Encrypted connections, like HTTP or SS, are essential for transferring Git LFS data. They not only increase information protection but also minimize the risk of interception.
Swift access control
To prevent unauthorized access to large binary files, you must restrict authorized users’ permission to push or pull Git LFS files. Improper access control exposes sensitive data for obvious reasons.
That’s why you should use platform-specific tools such as role-based access control (RBAC) to limit permissions and enforce proper governance over your git repositories.
Migrating to Git LFS (converting existing repositories)
If you manage an existing repository containing large binary files, you can migrate it to Git LFS for better performance. That means increasing the speed of Git operations, such as cloning or fetching.
The process involves using the git lfs track command, which you know from earlier examples:
git lfs track "*.mov"Nonetheless, simple file tracking (with Git LFS) does not affect past commits. To fully migrate an existing repo, the repository’s git history may need to be rewritten to replace all instances of the large binary files with pointer files. This way, the repo won’t be bloated with old logs.
For this purpose, you can use tools for:
- cleaning up large files from Git history [ BFG Repo-Cleaner]
bfg --convert-to-git-lfs "*.mp4" --no-blob-protection- fine-grained control over history rewriting (more advanced and flexible than BFG) [Git Filter Repo ]
git filter-repo --path *.mp4 --to-git-lfsBest practices for protecting Git LFS on a specific Git platform
Each platform – GitHub, GitLab, Bitbucket, and Azure DevOps – supports Git LFS but has its own approach to securing large files. Let’s briefly examine the specific security measures to consider for each system.
Best practices for Git LFS security on GitHub
GitHub provides a straightforward Git LFS integration. Users can install Git LFS and configure using .gitattributes to specify which file types should be tracked.
However, for security measures on GitHub, it’s essential to:
- enable GitHub Advanced Security for auditing access to LFS objects
- restrict repository access via GitHub’s granular permission management tools
- enforce the HTTP or SHH use for encrypted data transfers to protect Git LFS files during the transit.
Best practices for Git LFS protection on GitLab
Git LFS is natively supported on GitLab, and the platform allows detailed control over who can access and modify Git LFS objects.
Among security best practices on GitLab, you should include:
- role-based access control (RBAC) to limit allowance for push or pull LFS files
- two-factor authentication (2FA) for all users accessing repositories with sensitive large binary files
- encrypted connections for all operations by enforcing HTTPS and SSH access, mainly when operating on large binary files.
In addition, GitLab provides audit logs for repository actions. It helps admins track who accesses Git LFS objects.
Best practices for Git LFS safety on Bitbucket
Bitbucket uses built-in security features for Git LFS, although LFS objects require additional focus. That means:
- implementing branch permissions to restrict access to key branches where large binary files are managed using Git LFS
- using SSH key management for encrypting all Git LFS client interactions
- reviewing (regularly) Bitbucket’s audit logs to track actions on repos.
Best practices for Git Large File Storage safeguarding in Azure DevOps
Regarding Git LFS, Azure DevOps integrates very well through its robust security controls. Azure also has unique compliance and governance tools that can be leveraged to secure Git LFS environments.
In turn, you can:
- use Azure Active Directory (ADD) to enhance identity management and secure access control to Git LFS objects
- improve conditional access policies to further limit access to sensitive large files by enforcing multi-factor authentication and other
- secure LFS objects (encrypt data at rest) using Azure’s built-in encryption services.
The solution also provides powerful auditing features. It allows administrators to track all accesses and modifications of large files stored with Git LFS.
Additional activities supporting Git Large File Storage security best practices
It’s worth underlining some other strategies that directly contribute to improving the security of each Git LFS file: managing large files, cloning and pulling, as well as troubleshooting common issues.
Managing large files in the Git repository
Configuring the system through a .gitattributes file is a good practice for tracking (only) file types that benefit from being stored outside the repo, such as binary assets, images, and video files.
Such an approach reduces attack surfaces and enhances control over file types. Small text files remain within the Git system and are subject to the platform’s core version control security policies. It allows you to keep access or storage mechanisms uncomplicated.
Cloning and pulling with Git Large File Storage
When you git clone a repo, the client downloads the pointer files first and then retrieves the Git LFS objects. To optimize the process, you need to use:
- shallow clones to limit the number of commits fetched (git clone –depth)
- git lfs pull command with filters to avoid downloading large files that are unnecessary.
Troubleshooting common Git LFS issues
Common issues regarding large file storage include LFS object storage errors and repository size bloat.
In the first case, the LFS server should be accessible, and users should have the correct access rights.
To avoid bloat, prune the LSF cache regularly, removing unused objects to maintain optimal performance.
Yet another option is to check the audit logs available in each platform to investigate behavior or unauthorized access to Git LFS objects.
Take care of your back (up)
When discussing LFS, backup must also be considered. It’s vital to support best practices for securing LFS and its integrity. Well-performed backup policies help mitigate accidental data deletion, ransomware, and corruption risks. At the same time, you can:
- ensure compliance
- facilitate disaster recovery
- maintain workflow continuity and more.
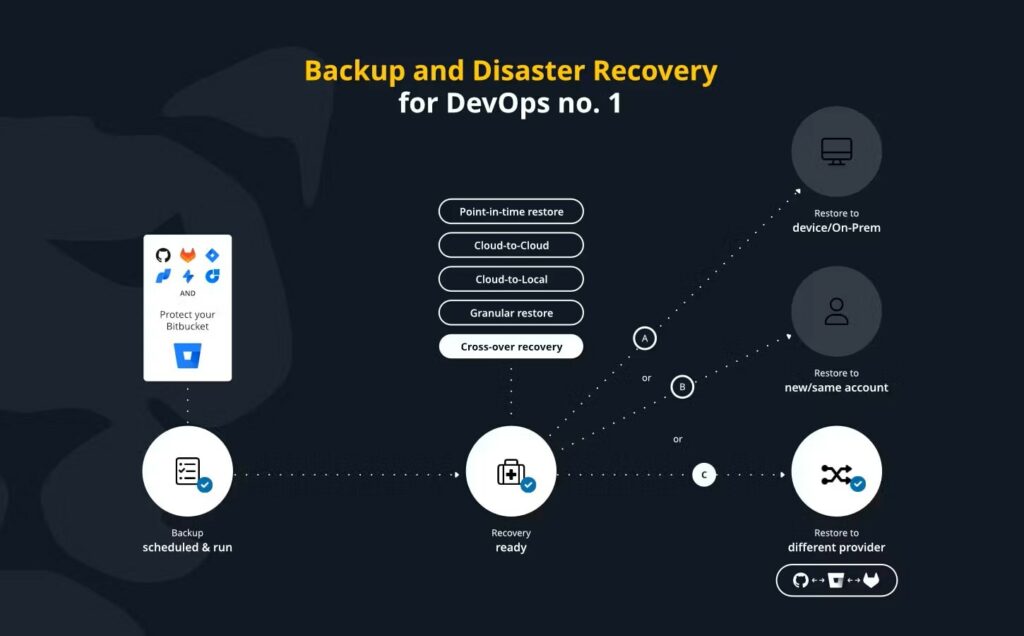
A backup and restore system like GitProtect.io can introduce automation, enhanced security, and scalability to complement best practices and backup capabilities (including replication).
Immutable and encrypted backups
Prevent unauthorized modification or deletion of Git LFS files by ensuring they are backed up immutably and encrypted. In other words:
- immutable storage ensures backed-up data cannot be altered or deleted post-backup
- end-to-end encryption (at rest and in transit) secures sensitive large files and repos from unauthorized access.
Automated backup scheduling
Regularly back up Git repositories and LFS data to minimize data loss risks:
- automate backups with flexible scheduling and make sure Git LFS is consistently protected without manual intervention
- allow backups to occur during off-peak hours to avoid disruption.
Multi-destination backup
Store backups in multiple, geographically dispersed locations (e.g., through GitProtect.io) to enhance resilience:
- whether it is on-premise, cloud storage, or hybrid setups
- and seamlessly integrate with major cloud providers (e.g., AWS, Azure, Google Cloud) and local storage solutions (ensuring redundancy).

Versioning and retention policies
Maintain historical versions of LFS data for compliance and recovery from ransomware with:
- backup versioning and configurable retention policies (access to past versions of LFS files)
- granular recovery for specific files or versions as needed.
Ransomware detection and recovery
Detect and mitigate threats like ransomware targeting Git LFS data, utilizing:
- ransomware detection mechanism, identifying anomalies in backups
- quick recovery of uncompromised Git LFS data (minimizing downtime and financial impact).
Compliance with regulatory requirements
Ensure Git LFS backups align with data protection regulations like GDPR, CCPA, or ISO 27001. Use GitProtect features to:
- comply with data residency and retention requirements
- provide detailed reports and audit trails for compliance audits.
Disaster recovery readiness
Make sure LFS files are included in disaster recovery plans to maintain business continuity. You can do it with:
- instant recovery of Git LFS files and repos in case of accidental deletion, corruption, or platform outages
- full repository restoration, including all linked LFS files (for minimal disruption).
To sum it up
Understanding how large file storage (LFS) works and setting up the platform’s specific security controls opens a way for implementing best practices for securing the Git LFS environment.
You can confidently manage large files while maintaining high-security standards by focusing on:
- access control
- data transfer and at rest encryption
- efficient file management.
By following best practices, you can ensure that Git LFS helps you manage large files far more efficiently and keeps them secure.
[FREE TRIAL] Ensure compliant DevOps backup and recovery with a 14-day trial 🚀
[CUSTOM DEMO] Let’s talk about how backup & DR software for DevOps can help you mitigate the risks



