


GitHub Backup to S3
Codebase expansion and the growing complexity of IT environments are good reasons to keep your GitHub backup in S3-compatible storage. Especially if you plan to boost data security while scaling
your storage horizontally with no physical upgrades needed.
From a business perspective, that is a step in the right direction. S3 storage efficiently streams disaster recovery strategies aligned with the 3-2-1, 3-2-1-1-0, or 4-3-2 backup rules. It translates directly into downtime and data loss risk reduction.
S3 to backup GitHub repos
Cost efficiency is a key advantage of S3-compatible service. Its pay-as-you-go models allow GitHub repos to be scaled as they grow. S3 systems offer tiered plans for frequently accessed data to remain in faster tiers. Older backups are moved to cheaper, cold storage.
GitHub backup to S3 allows users to take advantage of versioning, encoding services, and cross-region replication. These features enhance protection against accidental deletion or corruption.
At the same time, access policies (e.g., IAM roles and IAM users) enable fine-grained control over who can view, modify, or delete the stored data. This supports companies in their part of the Shared Responsibility Model (SRM).

AWS S3, Azure Blob, or Google Cloud Storage for your Git repositories?
When choosing the right S3 provider, matching their offering to the company’s data protection policies is essential.
Although it may seem trivial, such an approach, followed by optimal cost management, allows us to back up all our repositories efficiently and without losing data. So, what are the options?
AWS S3
Amazon’s service is recognized for scalability and security. Features also include versioning, encryption, and cross-region replication. AWS S3 integrates seamlessly with GitHub Actions for automated backups. It makes the service perfect for enterprises needing reliable cloud storage for every repo they develop.
Google Cloud Storage (S3-like)
Supporting multi-region redundancy and automatic class transitions, Google Cloud Storage may be one of the best choices for GitHub backups. It works well with Python scripts. GCS features include strong encryption and analytics for backup monitoring.
Azure Blob Storage
Azure Blob is the choice for users mainly operating in the Microsoft ecosystem. Azure provides immutable storage and automated tiering for better cost optimization. The solution is highly protected. It supports compliance needs, making it helpful in backing up GitHub information.
Backblaze B2
B2 is an affordable S3-compatible storage solution offering simple backups with no egress fees. It’s ideal for users looking to store GitHub repos securely and efficiently while minimizing costs.
Wasabi
Wasabi stands out for its consistent pricing and affordable, high-durability S3-compatible storage. The offer does not include additional charges for egress or API calls, making it an excellent choice for long-term GitHub information storage.
Each of the listed providers develop unique benefits for backing up GitHub repos, ensuring that saved data is safe and easy to recover from all objects and in any location.
Setting up GitHub backups to S3
In general, backing up GitHub repos to S3-compatible storage appears simple. Still, it requires thoughtful planning considering security and scalability.
Let’s analyze some standard methods for setting up automatic backups of the GitHub to S3.
Utilizing AWS CLI to create GitHub backups
As a reminder, AWS CLI is a command-line feature. It can automate GitHub backups to an Amazon S3 object. To automate the process, you can create a Python script or Bash script.
Here is an example of a script code:
#!/bin/bash
# Set environment variables for S3
export AWS_ACCESS_KEY_ID=your-access-key
export AWS_SECRET_ACCESS_KEY=your-secret-key
export S3_BUCKET=your-target-bucket
# Synchronize GitHub repo folder with the bucket (S3)
aws s3 sync /path/to/your/local/repository s3://$S3_BUCKET/backup/ --deleteAs you can see, the script syncs the local folder with an S3 bucket. This way, any changes are reflected in the backup. You can set up the task to run daily with the cron jobs. Another option is to integrate it into your CI/CD pipeline for continuous backups.
Backup automation with GitHub Actions
Using GitHub Action is another way to back up GitHub folders. Using this automation solution, users can run workflows triggered by repository events, for example, a push or pull request. By integrating Amazon’s command line into the GitHub Action workflow, you are free to automatically back up selected repositories to an S3 bucket.
And here is how you can create a GitHub Action code example:
on:
push:
branches:
- main
jobs:
backup:
runs-on: ubuntu-latest
steps:
- name: Checkout Repository
uses: actions/checkout@v2
- name: Install AWS CLI
run: sudo apt-get install awscli -y
- name: Sync Repository to S3
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
S3_BUCKET: your-target-bucket
run: aws s3 sync . s3://$S3_BUCKET/backup/In such a case, every push to the main branch triggers a GitHub Action workflow. It uses CLI to upload the latest version of the repo to the specified S3 bucket.
Custom Python code for GitHub backup
Some developers prefer more control over the process. A Python script helps automate the backup process. Its boto3 library allows for interaction with Amazon S3. This opens a way to set up a custom backup solution for your GitHub information clone.
The mentioned Python code example may look like this:
import boto3
import os
# AWS credentials from environment variables
s3 = boto3.client('s3',
aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY'))
# Path to the local repository folder
local_repo_path = '/path/to/your/local/repository'
# Upload data to S3 bucket
for root, dirs, files in os.walk(local_repo_path):
for file in files:
s3.upload_file(os.path.join(root, file), 'your-target-bucket', f'backup/{file}')Efficient GitHub backups – Best practices
It’s no surprise that storing backups in S3 is recommended to follow at least some practices to enhance data protection and compliance. To put it short, among them are:
Data encryption
At a minimum, use server-side encryption (SSE-S3 or SSE-KMS) to protect the information in the created S3 bucket (or objects).
IAM roles and policies
Use the least privilege principle granting users (IAM user) and roles (IAM role) minimum permissions required to perform any given task.
Versioning and Object Lock
By enabling these features you can safeguard backups from accidental deletion of corruption.
Cross-Region Replication (CRR)
CRR will help you establish redundancy and disaster recovery across multiple regions.
Lifecycle policies
Move old backups to cheaper options (like S3 Glacier in AWS) to automate storage cost optimization.

GitProtect – a middle ground between GitHub backup and S3 bucket
Another good practice is incorporating software for managing GitHub backups (or other Git environments) to automate the process. Such a solution eliminates the need for manual activities and reduces the risk of losing (or leaking) data.
GitProtect is a prime example of a reliable tool for managing GitHub backups (and other Git environments). It offers comprehensive disaster recovery services, ensuring 360-degree cyber resilience and compliance.
As an ISO 27k and SOC 2 Type II certified tool, GitProtect offers a safe way to back up and restore all or select data. That includes repositories and metadata:
- projects
- issues
- pull requests
- pipelines and more.
The platform supports granular restore for specific repos and file recovery and integrates with major cloud providers.
With built-in encryption, versioning, and immutable backups, GitProtect enhances protection and prevents unauthorized access or accidental deletions.
The GitProtect:
- centralizes backup management
- supports flexible scheduling services
- provides audit-ready reports for compliance.
The software works with cloud and on-premise storage servers. It delivers scalability or disaster recovery through backup replication.
How to manage GitHub backup in S3 with GitProtect
Storing GitHub backup data on S3 using GitProtect follows a similar process as with GitLab backups, as outlined in this article. However, since GitHub is integrated into the Microsoft ecosystem, utilizing Azure Blob for repository storage might be a more favorable option, aligning with the broader Microsoft environment.
Access account and blob storage in Azure
You must set up storage account and Blob container in Azure. Then, you can integrate via access keys or a shared access signature (SAS).
The first (access keys) provides complete control but requires caution due to high privileges. SAS offers temporary, limited access to specific resources, making it more secure for scenarios where restricted and time-bound permissions are needed.
GitHub, bucket, and GitProtect
When the previous steps are ready, and the GitHub account (organization) is connected to GitProtect, it’s time to configure an Azure Blob Storage container as storage in GitProtect.
Begin opening the Storages tab and select Add storage button.
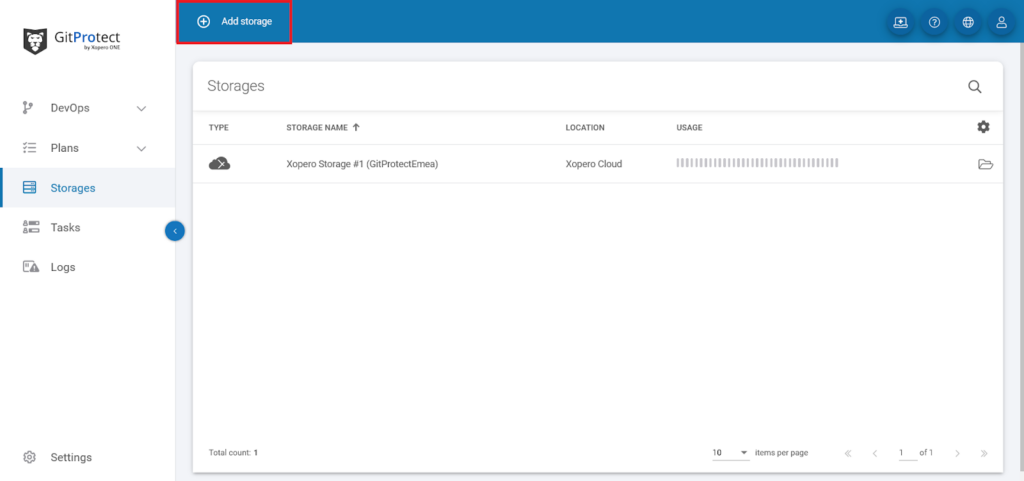
Use the Add storage aside to set the storage name in the Add storage name field (1). Next, click expand the Storage type section (2).
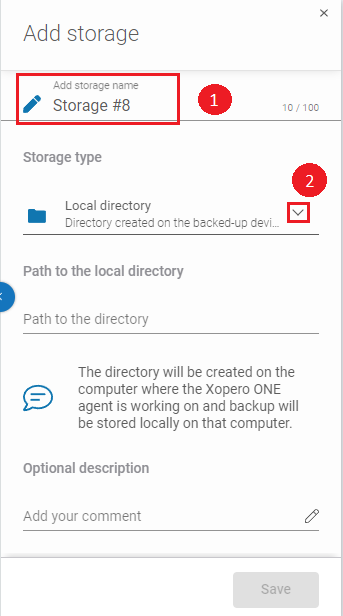
Now, scroll down the list and select the Azure Blob Storage option.
After that, the system will show you more sections: Authentication data (Connection String), Container name, and Optional description.
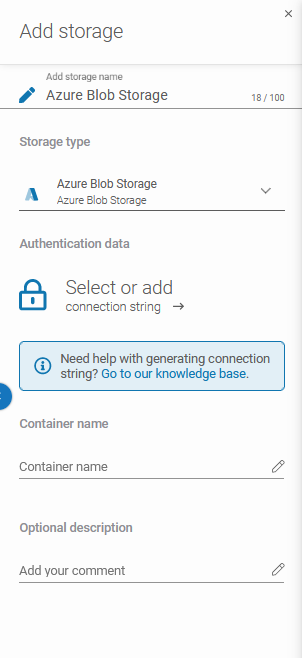
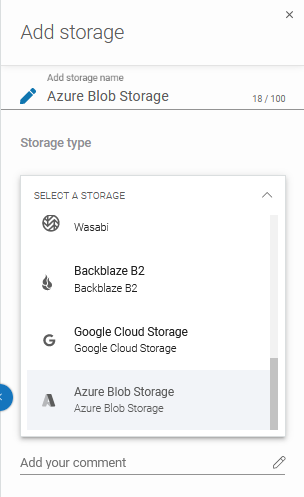
By hitting the padlock button you can add the password from the Password Manager or create a new one. After that fill the Container name and Optional description fields.
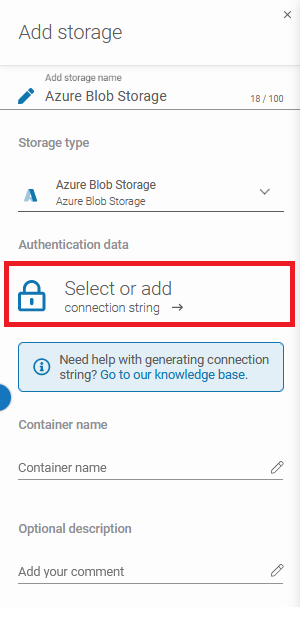
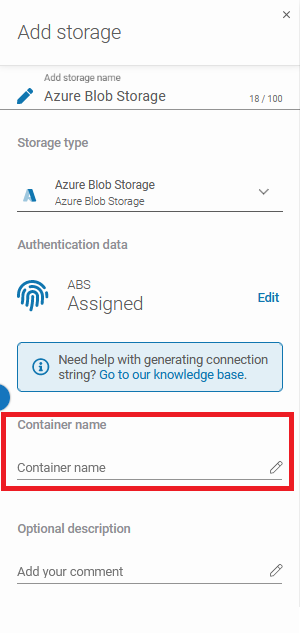
Ensure that the browsing machine – the GitProtect worker – is one of the licensed devices with the GitProtect agent installed and has access to your Azure Blob Storage container.

Click the Save button to add the storage. To see the storage on your list just refresh the page.
You will find more details and options in the GitProtect help center and documentation.
Conclusion
S3s allow you to store GitHub backups in a more secure and scalable way of efficiently managing repository data. Automating backups with AWS CLI, GitHub Actions, or custom Python scripts simplifies the process and integrates vital functions like encryption, versioning, and access management.
Any organization can safeguard its GitHub repositories from data loss, unauthorized access, and corruption by following best practices—such as using:
- IAM roles
- data encoding
- versioning
- cross-region replication.
Adding GitProtect to the backup process you can rely more on automation, digital protection, and store your repos fulfilling compliance. The platform integrates smoothly with S3. Businesses may effectively scale storage size while encrypting current repository data and establishing access control.
Providing centralized control with flexible scheduling and granular restore options, GitProtect simplifies backup management. That makes it a robust format for firms seeking protection against accidental or malicious deletions from both cloud and on-premise storage.
[FREE TRIAL] Ensure compliant GitHub backup and recovery with a 14-day trial🚀
[CUSTOM DEMO] Let’s talk about how backup & DR software for GitHub can help you mitigate the risks



