


Jira Backup to S3
Jira is a versatile and critical tool for more than 125,000 companies worldwide. That’s enough reason to perform Jira data with automated backup to S3 storage as part of a thoughtful strategy to protect valuable data and business continuity.
Almost any software matching Jira environment complexity is susceptible to information loss – mainly due to human errors.
According to Verizon, it happens in up to 85% of cases. If so, a robust plan for automated backups becomes crucial for broader data protection tactics.
Backup options for Jira Cloud and Jira Service Management
Each Jira (Cloud) backup file is stored in the local file system by default. However, there are three possibilities:
Jira Cloud backup
If your firm uses Jira Cloud, Atlassian provides a built-in backup solution. You can create a backup schedule or do it manually when storing and restoring data in Atlassian’s cloud.
Jira Data Center (formerly Jira Server) backup
In this case, you can rely on the provided backup manager to create and manage backup data. They can be stored locally or in an external service, like S3.
Third-party apps
Various applications available on Atlassian Marketplace offer advanced backup and restore features for Jira. They can integrate with S3, supporting automation.
Nonetheless, Atlassian recommends using the Amazon S3 solution to store backups. Especially, for the companies that manage large datasets and need to scale according to their needs.
Additionally, Atlassian suggests transferring backups to S3 in XML file format. For improved security, you may also use native database backups.
It’s suffice to point out that currently (2024):
Jira Cloud does not support automated backups. Currently, you can perform data-only backups (which exclude attachments, avatars, and logos) at any time. When you create a backup that includes attachments, avatars, and logos, you will need to wait 48 hours from the last time you created a backup with attachments.
Source: Jira Software support.
7 reasons to protect Jira data in Amazon S3
S3 (Simple Storage Service) offers several advantages, making it a top choice for Jira backups.
Scalability
It allows you to accommodate the growing data volumes of Jira instances. No (if any) significant infrastructure changes are needed.
Security
S3’s security is mainly based on solid SSE-S3 or SSE-KMS server-side encryption. Client-side security is also provided at rest or during data transmission.
Durability
It enhances data protection against hardware failures and other risk. The modern standard is 99.99999999999% durability.
Cost-effectiveness
The cost-effectiveness related to S3s is higher than that of the traditional backup solutions – especially for large datasets.
Integration
Fast integration with various cloud services and tools makes S3 easy to incorporate into the existing IT stack.
Security
Robust security features, including encryption and access control, allow S3 to protect sensitive data effectively.
Compliance
Compliance with GDPR, SOC 2, PCI DSS, FedRAMP, or HIPAA is a part of the solution.
What S3 for Jira backup file
As mentioned, Atlassian recommends utilizing the Amazon S3 capabilities offered by AWS (Amazon Web Services). In recent years, however, five players have dominated the market.
AWS S3 [H3]
Easily scales with your Jira instance growth. Jira tools and third-party apps usually natively support AWS S3, simplifying automation and management.
Microsoft Azure Blob
It offers slightly more complex pricing tiers than AWS but is competitive for large data volumes.
Wasabi
The solution is considered low-cost storage. It’s ideal for large and infrequently accessed data. The offer does not include API request fees or egress.
Backblaze B2
B2 is recognized as one of the most affordable cloud storage services. It works with S3- S3-compatible APIs but may require some third-party tool(s).
Google Cloud Storage
By definition, GCS is not an S3 storage. Nonetheless, it provides similar features and benefits. In the case of Jira backup, some additional apps might involve custom configurations.
It’s natural to underline that you should go through configuration requirements to check if a given service suits your needs and fits your current and future applications.
Jira backup to S3-compatible storage
After choosing your S3 provider or following Atlassian’s recommendation, you can create a connection to your Jira (Cloud) with an S3 bucket. Now, let’s do it in a step-by-step guide.
The first thing to do is configure your S3 storage (or reconfigure the existing one). In our case, it’s AWS S3.
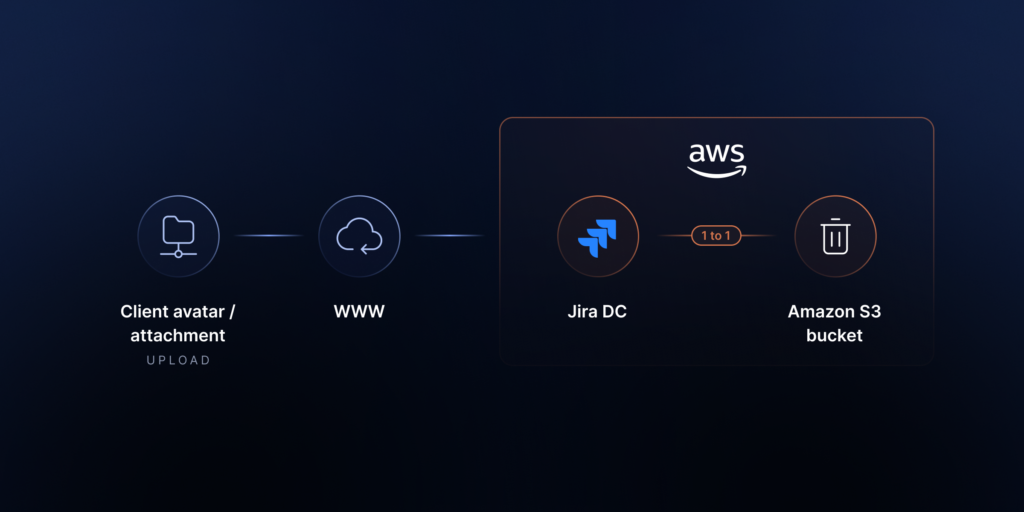
Source: Atlassian support documentation.
Next, you can set up the backup storage in Amazon S3 via the filestore-config.xml file in Jira <localhome>. To utilize S3 as your destination for backup data, the filestore attribute in filestore-config.xml must be modified to correspond to the s3-filestore ID.
By using S3 for avatars, you can modify filestore-config.xml to store backups as well by adding an association element for backups.
In addition, the filestore attribute should point to that bucket if you intend to store backups in the same bucket as avatars.
To use different buckets, create multiple <s3-filestore> elements and reference them in the respective association targets.
For example:
<?xml version="1.1" ?>
<filestore-config>
<filestores>
<s3-filestore id="avatarBucket">
<config>
<bucket-name>jira-avatar-bucket</bucket-name>
<region>us-east-1</region>
</config>
</s3-filestore>
<s3-filestore id="backupBucket">
<config>
<bucket-name>jira-backup-bucket</bucket-name>
<region>us-east-1</region>
</config>
</s3-filestore>
</filestores>
<associations>
<association target="avatars" file-store="avatarBucket" />
<association target="backups" file-store="backupBucket" />
</associations>
</filestore-config>Source: Atlassian.com.
And finally, to keep backups in a Jira <sharedhome> directory, you can remove the backup association element. If Amazon S3 isn’t set up or filestore-config.xml is not found in <localhome>, Jira will default to storing backups locally.
<?xml version="1.1" ?>
<filestore-config>
<filestores />
<associations />
</filestore-config>Source: Atlassian.com.
It looks slightly different when the Jira installation operates on an IPv6-only network. In that case, overriding the default endpoint with the dual-stack endpoint is necessary.
<?xml version="1.1" ?>
<filestore-config>
<filestores>
<s3-filestore id="backupBucket">
<config>
<bucket-name>dualstack-bucket</bucket-name>
<region>us-east-1</region>
<endpoint-override>https://s3.dualstack.us-east-1.amazonaws.com</endpoint-override>
</config>
</s3-filestore>
</filestores>
<associations>
<association target="backups" file-store="backupBucket" />
</associations>
</filestore-config>Source: Atlassian.com.
The above XML examples also allow you to store attachments, issue types, or any log.
After configuring the S3 bucket, verify if it successfully stores Jira backups. In Administration -> System, under the Backup system, check the bucket name and region for your backup files.
GitProtect – A more convenient approach to the backup process
To sum it up, moving Jira backups from the local repository to an Amazon S3 bucket is essential to increasing data security and avoiding data loss.
After all, integrating backup automation into your workflow is a vital step, whether you’re using Jira (Cloud) Software or Jira Service Management.
However, there is a more secure and convenient method to control Jira backup projects utilizing AWS services. You can use the GitProtect platform.
All-in-one Jira backup manager
GitProtect is a backup and recovery software designed for the DevOps ecosystem. The tool protects not only source code, but also all the related metadata, such as:
- pull requests
- comments
- issues (issue types)
- CI/CD tasks and more.
The platform includes several benefits. That consists of:
- restoring your repos directly to your Jira Cloud or Jira Data Center (formerly Jira Server) instance account
- unlimited data retention for archive purposes
- data replication – to create a backup file of your Jira data in a different location to prevent data loss or damage in a disaster event.

GitProtect offers advanced audit log(s) and visual statistics to help you track all actions and identify potential errors. You can also perform backups on-demand and receive customized email or Slack notifications.
In a word, GitProtect provides a simple and convenient way to backup, restore, and analyze the process of storing data in S3 (and much more), which every Jira (Cloud) administrator will appreciate.
GitProtect and Jira data backup to Amazon S3
Before you create a Jira data backup using GitProtect, register for a GitProtect.io account. Then, follow the instructions to add your Jira organization to GitProtect.
Of course, it’s worth remembering that the minimum permissions required to register the GitProtect app and create a backup or restore process are administrative permissions.
Now, the platform backs up the entire Jira environment. It works smoothly with Jira Cloud, Jira Service Management, and Jira Work Management (both on Cloud and Data Center instances).
The platform works smoothly with Jira Cloud, Jira Service Management, and Jira Work Management (both on Jira Cloud and Data Center instances). The backup process covers the entire Jira resources:
- issues
- projects (with tasks)
- projects Roles
- workflow, Users
- comments
- attachments
- boards
- versions
- fields (Custom fields, Layouts, Screens)
- votes
- any audit log
- notifications.
You can find a detailed list of protected elements at this link.
Create a backup plan
To set up a new backup plan, open the Plans tab on the left panel and click the (+) Add plan button on the (blue) top bar. The system will display a new panel. Enter a name for your plan.
Next, provide the name of the backup plan. Set the Backup type section to Jira.

In the following step, select the Jira organization you want to introduce to the backup and restore process.
Let’s mention again that GitProtect allows the Jira user (with administrator permissions) to protect all Jira data, whether on Jira Cloud or Jira Data Center (formerly Jira Server) instance.
You can also choose the Worker. It’s a device directly responsible for your Jira’s backup process. You can have many workers and use different ones for each backup plan. It is worth knowing, that Cloud Worker (cloud-installed) allows you to perform cloud-to-cloud backup.
Jira (cloud) backup storage
In this step, you need to select one of the locations assigned to you GitProtect as storage.
Next to it, you can also configure the schedule (scheduler) and decide your data retention (how long it should be stored).
And that’s it! Your primary setup to backup files from Jira (Cloud) to Amazon S3 is done.
If necessary, you can decide to manage Jira integration in GitProtect to establish, for example, a direct link between your Jira issues and corresponding Git repositories.
Jira (cloud) backup replication
A very powerful and unique GitProtect’s feature (as a backup manager) is replication. It allows for duplicating any backup file between different storage instances. And it can be done with a single or multiple backup plans. With the GitProtect system and its replication plans, you can replicate backups:
- from one storage to another
- between multiple locations
- between local storage (e.g., Jira Data Center instance) and public clouds (e.g., Amazon S3) – depending on the backup options you’ve created.
Adding replication in your disaster recovery procedure will help you to avoid data loss in critical cases, like:
- storage corruption
- malicious software attacks.
This way you can save your time, resources, projects, and each developer and Jira user’s satisfaction level.
Besides, the main idea of the replication is to allow GitProtect users to install and implement 3+2+1, 3+2+1+1+0, or 4+3+2 backup rules. Such an approach significantly increases the data safety.
Set up your replication plan
So, all you need to do is to set the storage destinations.
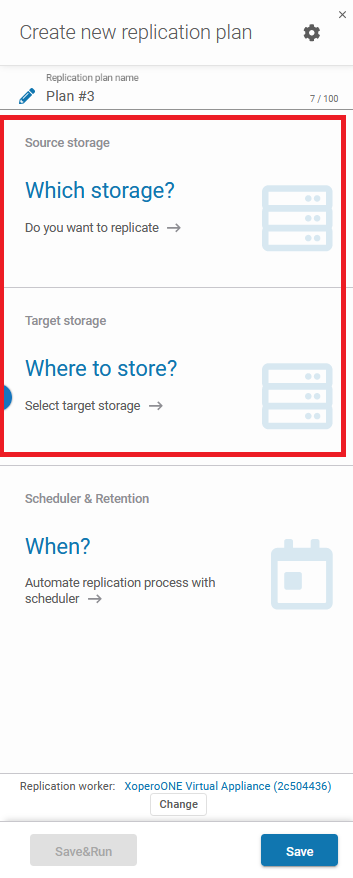
In the next step, configure a simple scheduler.
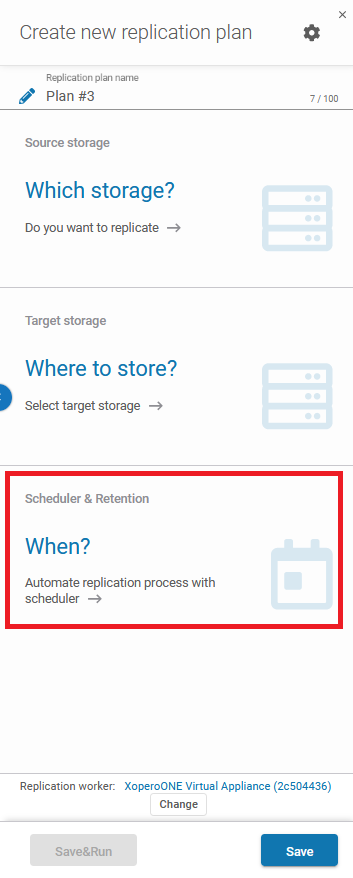
To make it all work, you need at least two storage locations:
- Source storage – with data to replicate on the second storage
- Target storage – the place where the data should be replicated (initially, it cannot contain any data).
Learn more about how GitProtect’s capabilities may help you solve your challenges by backing up all created projects in Jira (Cloud or Data Center).
[FREE TRIAL] Ensure compliant Jira backup and recovery with a 14-day trial🚀
[CUSTOM DEMO] Let’s talk about how backup & DR software for Jira Cloud can help you mitigate the risks



