


DevOps Threats Unwrapped: Mid-Year Report 2025
From minor hiccups to full-blown blackouts, the first half of 2025 made it clear that even the most trusted DevOps platforms are not immune to disruption.
In this ecosystem, every commit, push, and deployment relies on complex systems that, despite their brilliance, are fragile. Like a Jenga tower of integrations, it takes just one wrong move – a misclicked setting, a leaked secret, an API failure – for the whole thing to wobble.
GitHub now hosts over 100 million users and 420 million repositories. Microsoft Azure DevOps has surpassed 1 billion users worldwide, while GitLab reports 30 million registered users. Bitbucket powers more than 10 million professional teams, with Jira adding millions more to this global ecosystem. But as these platforms grow in size and complexity, avoiding outages or human error becomes increasingly difficult. At this scale, with top global brands relying on them, security breaches and increasingly sophisticated cyber threats are no longer a possibility, but a certainty.
DevOps Threats Unwrapped: Mid-Year Report by GitProtect examines the threats of H1 2025, focusing on unplanned outages, attacks, and silent mistakes with severe consequences.
Key insights:
- Azure DevOps recorded a total of 74 incidents, including one of the longest-lasting performance degradations that spanned 159 hours.
- European users were particularly affected, accounting for 34% of all incidents on Azure DevOps.
- GitHub saw a 58% year-over-year increase in the number of incidents, reaching 109 reported cases:
- 17 of them were classified as major, leading to over 100 hours of total disruption.
- April stood out as the most turbulent month, with incidents accumulating to 330 hours and 6 minutes.
- GitLab patched 65 vulnerabilities and faced 59 incidents, resulting in approximately 1,346 hours of service disruption.
- Bitbucket experienced 22 incidents of varying impact, which together lasted more than 168 hours.
- Jira reported over 2,390 hours of cumulative downtime across its ecosystem – that’s nearly 100 full days of service disruption.
- A total of 330 incidents impacted DevOps platforms in the first half of 2025.
If your DevOps pipeline is the heart of your organization’s innovation, consider these your warning signs.
Azure Devops
In the first half of the year, Azure DevOps experienced a total of 74 incidents, including 3 advisory cases and 71 incidents of degraded performance.
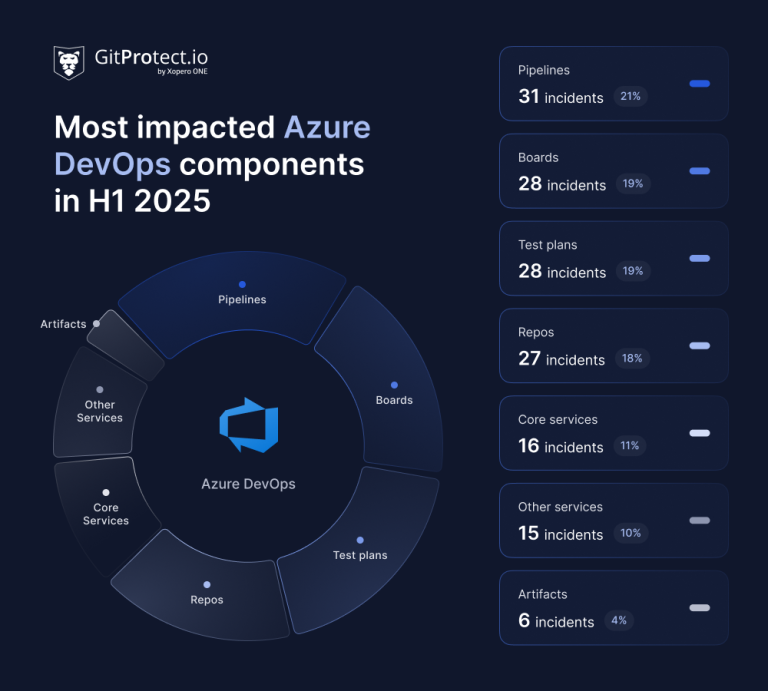
Some incidents impacted multiple components at the same time, while others affected only a single component. For instance, one outage could disrupt Pipelines, Boards, Repos, and Test Plans simultaneously. In our methodology, such an event is counted as one incident overall, even if it influenced several services. Within this total, the components were affected the following number of times:
- Pipelines: affected 31 times (21%) – the most unstable component
- Boards: affected 28 times (19%)
- Test Plans: affected 28 times (19%)
- Repos: affected 27 times (18%)
- Core Services: affected 16 times (11%)
- Other services: affected 15 times (10%)
- Artifacts: affected 6 times (4%)
In January 2025, Azure DevOps users worldwide faced one of the longest-lasting performance degradations on record— a 159-hour disruption that severely impacted pipeline functionality. For almost a week, users trying to create Managed DevOps Pools within new subscriptions without existing pools experienced persistent failures. These attempts repeatedly timed out with the provisioning error: “The resource write operation failed to complete successfully, because it reached terminal provisioning state ‘Canceled’.” The issue led to delays in builds, deployments, and onboarding processes across affected environments, highlighting the operational risks tied to large-scale platform dependencies.
Another serious security challenge for Microsoft Azure DevOps in 2025 was the discovery of multiple critical vulnerabilities, including SSRF and CRLF injection flaws within the endpointproxy and Service Hooks components. These vulnerabilities could be exploited to carry out DNS rebinding attacks and allow unauthorized access to internal services. Such attacks present significant risks in cloud environments, including data leakage and potential theft of access tokens. In response, Microsoft released security patches and awarded a $15,000 bug bounty to the researchers who discovered the issues.
Additionally, it’s worth noting that European customers experienced a higher number of incidents – 27 incidents, representing roughly 34% of all incidents. In contrast, Azure DevOps users in India and Australia reported the fewest incidents of degraded performance, accounting for only 4% of all incidents.
GitHub
GitHub experienced a significant 58% rise in incidents during the first half of 2025, jumping from 69 cases in H1 2024 to 109 this year.
Among this year’s incidents, 17 were classified as major, causing over 100 hours of total disruption. That’s enough time to run over 1,000 CI/CD pipelines from start to finish or binge-watch the entire Marvel Cinematic Universe.
Seventy-eight incidents (72%) had a minor impact.

May recorded the highest number of incidents, with 23 reported cases, while April saw the longest cumulative incident duration, totaling 330 hours and 6 minutes.
In the first half of 2025, GitHub Actions emerged as the most affected component, with 17 incidents, including a major disruption in May that lasted 5 hours. The outage, caused by a backend caching misconfiguration, delayed nearly 20% of Ubuntu-24 hosted runner jobs in public repos. This could have slowed down development cycles, impacted release schedules, and reduced productivity for teams relying on GitHub Actions for continuous integration. GitHub resolved the issue by redeploying components and scaling resources, and committed to improving failover resilience going forward.
Meanwhile, attackers actively exploited GitHub to spread malware. Among the most notable malware campaigns noticed during this time were Amadey, Octalyn Stealer, AsyncRAT, ZeroCrumb, and Neptune RAT.
GitLab
In the first half of 2025, GitLab patched 65 vulnerabilities of varying severity, marking a slight decrease from the 70 vulnerabilities disclosed during the same period in 2024.
During this time, GitLab also experienced 59 incidents, totaling approximately 1,346 hours of disruption. These included partial service disruptions (20 incidents – 34%) and degraded performance (17 – 29%), followed by operational issues (10 incidents – 17%), full service outages (7 incidents, adding up to over 19 hours of downtime – 12%), and planned maintenance (5 incidents – 8%).
The longest service disruption lasted for over 4 hours and was caused by issues related to a specific worker and traffic saturation that affected the primary database. This incident led to 503 errors and impacted the availability of GitLab.com services for users.

One of the most notable incidents involved a data breach at Europcar Mobility Group data breach. The attackers successfully infiltrated GitLab repositories and stole source code for Android and iOS applications, along with personal information of up to 200,000 customers.
Atlassian
Bitbucket
In H1, Bitbucket experienced 22 incidents with varying severity, resulting in over 168 hours of downtime. Among these, 2 critical incidents lasted for over 4 hours, impacting key services including Website, API, Git via SSH, Authentication and user management, Webhooks, Source downloads, Pipelines, Git LFS, and more.

January 2025 proved to be one of the most challenging months for Bitbucket, highlighted by a major outage widely reported on DownDetector. For 3 hours and 47 minutes, access to Bitbucket Cloud’s website, APIs, and pipelines was completely unavailable, disrupting developer workflows worldwide.
Jira
Atlassian’s Jira ecosystem – including Jira, Jira Service Management, Jira Work Management, and Jira Product Discovery – experienced 66 incidents in the first half of 2025, marking a 24% increase compared to H1 2024. Altogether, these disruptions added up to more than 2,390 hours, or nearly 100 full days of downtime.
Much of this downtime resulted from a prolonged maintenance period that began in mid-March and extended through the end of May. As a consequence, users of the Free edition of Jira services, particularly those located in Singapore and Northern California, may have experienced outages lasting up to 120 minutes per customer.
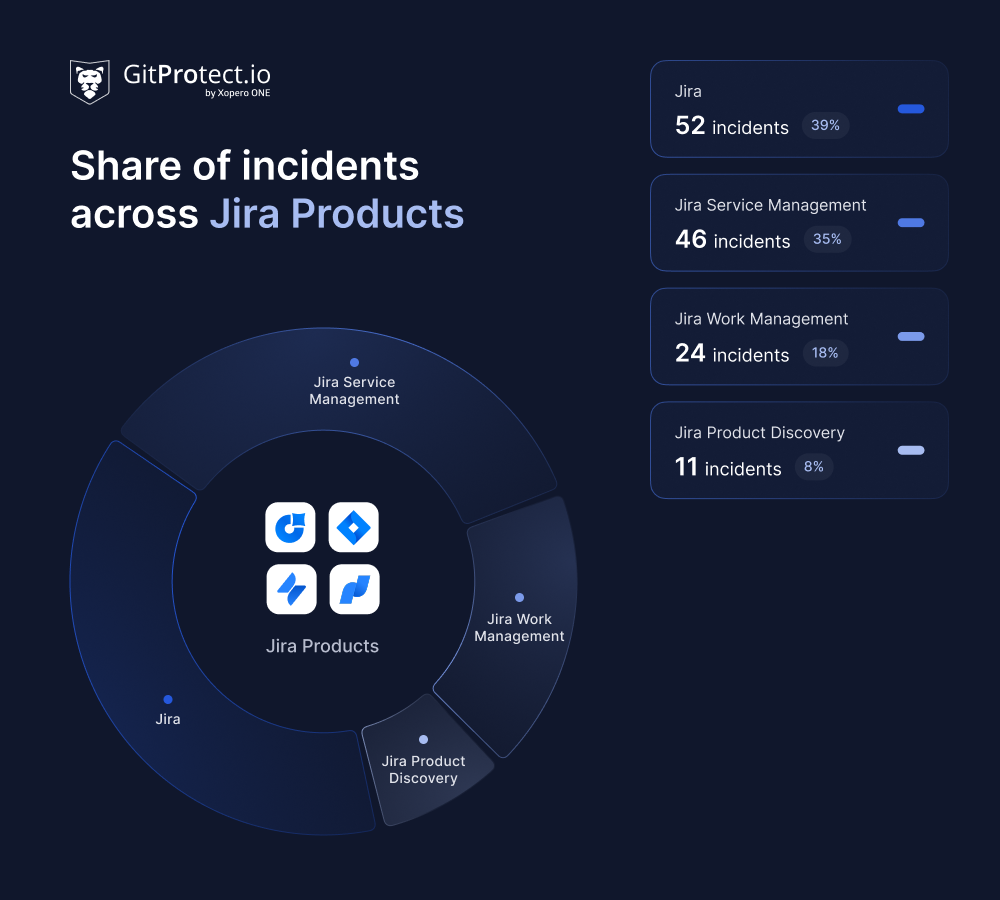
As mentioned, Jira recorded 66 unique incidents. Some of these incidents impacted multiple products simultaneously. The numbers below reflect total disruptions per product rather than unique events.
Jira users were the most affected, with 52 disruptions (39% of all Jira-related service impacts). Jira Service Management followed with 46 disruptions (35%), while Jira Work Management experienced 24 (18%). Jira Product Discovery had the fewest, with 11 disruptions (8%).
Jira was also at the center of several notable incidents in early 2025. One of the most concerning involved a string of ransomware attacks carried out by the HellCat group. The attackers developed a playbook for infiltrating organizations via Atlassian Jira instances, using stolen credentials to gain access. High-profile victims included Telefónica, Orange Group, Jaguar Land Rover, Asseco Poland, HighWire Press (USA), Racami (USA), and LeoVegas Group (Sweden).
Over 300 incidents in the DevOps ecosystem
In total, 330 incidents of various severity levels were recorded across the major code hosting and collaboration platforms, ranging from Azure DevOps to Jira.
Here’s how the incident breakdown looks across platforms:
- GitHub – 33% of all incidents
- Azure DevOps – 22%
- GitLab – 18%
- Jira platform tools (Jira, JWM, JSM, JPD) – 20%
- Bitbucket – 7%

While not all of them caused full-outages, the scale and distribution of these events reveal a lot about where the ecosystem’s weak points might be. Whether it’s version control, issue tracking, or CI/CD pipelines – these interruptions remind us that even the most popular platforms face reliability challenges. And for teams building software at scale, stability can no longer be taken for granted.
When Dev Platforms Go Down
DevOps teams can’t afford to wait passively when their core tools go down. Proactive backup, well-defined contingency plans, and flexible workflows make the difference between delivery and recovery.
- Back it up. Use automated backups for code, pipelines, issues, and boards.
- Work local. Ensure the ability to code with local clones and offline workflows.
- Mirror critical repos. Redundancy across platforms (e.g., GitHub ↔ GitLab) keeps projects moving.
- Review and adapt. After any outage, run a quick post-mortem. Improve what didn’t work.
Methodology note
All data comes from GitProtect’s internal analyses. Percentages may not add up to 100 due to rounding.


