
DevOps Security – Best Data Protection Practices
DevOps has already become an integrated part of almost every industry and its development process. Whether it’s technology, automotive, healthcare, or any other industry, it’s hard to imagine an organization that doesn’t rely on DevOps. Numbers speak better: the majority of consumers are from the technology sector – 44%, yet there are a lot of organizations from other industries that depend on DevOps – financial, education, etc. Just take a look at the statistics from the DORA survey:
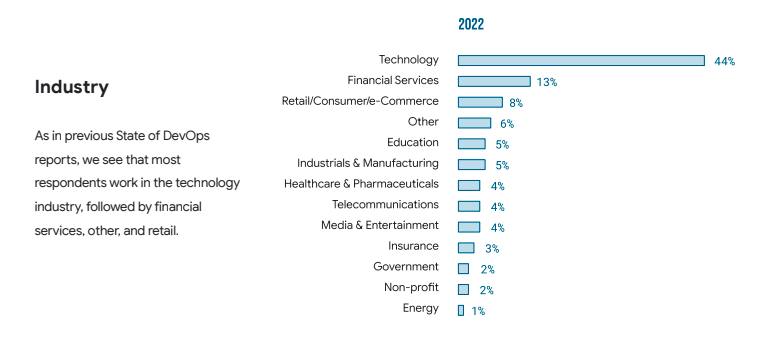
Source: 2022 Accelerate
However, let’s get back to the core topic of this blog post – how to help your DevOps teams integrate security into your software development process and what the DevOps best security practices are to protect critical source code environments against any security concerns and risks. Making security a natural part of DevOps strengthens applications from day one, ensuring a more robust and secure development lifecycle.
What are some DevOps security challenges?
DevOps security issues and challenges usually appear from developers and operations teams being on different pages with security teams. Developers want to push their software into the pipeline as fast as possible, while security teams are all about integrating security and squashing every last vulnerability and bug they can find, often prior to any post-incident security fixes. And that’s reasonable, as without a well-defined network perimeter and measures on integrating security at every stage of the development process for secure software, an organization has to deal with cybersecurity threats, data breaches, and data loss. Cloud environments present unique security challenges due to a wider attack surface and lack of a well-defined network perimeter. Why should we go far away? Let’s just remember the recent Mercedes-Benz source code exposure caused by a mishandled GitHub token and human error.
Check out the challenges and security fixes GitHub, GitLab, Azure DevOps, Atlassian, and their customers faced in 2024:
📌 GitLab vulnerabilities and security incidents
📌 Atlassian security incidents
📌 Infamous GitHub-related incidents and threats
📌 The state of the Azure DevOps threat landscape

So, the next time, instead of asking “Why protect DevOps data?”, just think of data loss and hours of interrupted business continuity. Among other reasons and security considerations in favour of data protection, let’s mention:
Compliance requirements
Depending on the industry you’re working in, your company may need to keep up with security audits, like SOC 2, ISO 27001, GDPR, Cyber Resilience Act, NIS 2, and others.
While building, we all use DevOps tools: GitHub, Atlassian, Microsoft, GitLab, put any SaaS provider here, follow the Shared Responsibility Model. It means that the SaaS provider is responsible for its operation, while customers are responsible for their data protection, security tools, DevSecOps tools they use, and security processes they implement.
Learn more about shared duties and responsibilities:
📌 GitHub Shared Responsibility Model
📌 GitLab Limited Liability Model
📌 Atlassian Cloud Shared Responsibility Model
📌 Azure DevOps Shared Responsibility Model
Are you a visual learner? Watch our video to find out all the details about the Shared Responsibility Model.
DevOps security best practices
Well, what to do to have an excellent security posture and know that your DevOps data is under the most reliable protection? What are the best practices to integrate security into your software development process, addressing any security concerns and issues? That’s simple: adapt your company policy to DevOps security best practices and make sure that all your team members understand their responsibilities within that security strategy well.To successfully implement DevSecOps, it is critical to initiate culture change from the top down within an organization. So, let’s go through all the DevOps security best practices in detail.

Switch to a DevSecOps approach
Once you decide to ensure DevOps security, you will need to turn to the DevSecOps approach, which is a set of principles and practices to ensure secure software development, infrastructure, applications, and data within the company.
This approach also requires a culture where not only security groups but every team member is responsible for security. Thus, a DevOps team learn from the security team about secure coding practices, while those, in turn, find out more about coding practices and the technology stack the organization they work in uses. This approach assumes that your security professionals can start writing code and get some proficiency in APIs, and your DevOps teams can learn how to automate security tasks.
Follow the shifting left concept
For an organization, it’s crucial to deliver high-quality software on time, but what about bugs and security vulnerabilities that can arise from the lack of testing? To address the issue, DevOps can adopt a shift-left approach, which foresees DevOps security measures integrated earlier in the software development lifecycle.
In this case, DevOps teams will be able to detect and address software vulnerabilities and security issues earlier while coding, and, as a result, reduce the risks associated with security stages later, during production.
Apply penetration testing and automated continuous security monitoring
If the development is the bones of software, the DevOps security is its muscles. The more security tests and vulnerability scanning you have, the better your company’s assets are protected. Whether the shift left approach should help to identify and address vulnerabilities earlier in the SDLC, penetration testing is applicable at later stages of development.
📎 Penetration testing is a specific authorized security assessment method aimed at evaluating the security of your organization’s application, system, or network. This method involves simulating any attack surface in your DevOps environment to find security gaps that threat actors can potentially use to compromise your data.
However, you should keep in mind that manual penetration testing can slow down the development process a little bit. Thus, it’s always better to automate all the security testing within your organization to detect vulnerabilities, security flaws, bugs, defects, and data breaches that may appear during coding in your development pipelines. Another important piece of advice is to run those tests as frequently as possible to give your software developers immediate feedback on different security flows and instructions to remediate them.
Implement the principle of least privilege to control access management
Access controls – passwords, API access tokens, secrets management, etc. – are one of the key factors of DevOps security practices. It means that the production environment and data are available only to authorized users who need them to perform their jobs. Limiting permissions reduces the risk of accidental or malicious actions in development environments.
In this case, if bad actors compromise your company’s system or any of its employees’ accounts, the damage will be limited to specific permissions. One day, limited access may save your organization’s entire system or network.
Keep up with compliance and security policies
Developing and establishing robust security policies and governance is essential for effective security risk management. So, your organization should define clear policies and procedures concerning access control, configuration management, code reviews, vulnerability testing, and security tools. Moreover, you should ensure that all your DevOps processes and security controls are in line with relevant international compliance protocols, such as HIPAA, PCI DSS, GDPR, or any other applicable to your industry. Defining roles and required permissions enhances security accountability. And don’t forget about regular updates in your organization to keep up with the newest security threats.
What’s more, it’s important that your DevOps and security teams work according to these policies and that all these policies are implemented across your entire SDLC.
Use vulnerability management
You should do your best to implement a system that will scan, assess, and remediate security vulnerabilities across your entire software development lifecycle. It will ensure that your code is safe and sound before development.
However, you should understand that vulnerability scanning and bug testing are constant processes – if a critical flaw wasn’t detected in the early stages of development, it can easily come to light during the production stage.
Automate your DevOps security processes and tools
You should try to automate all the security processes as much as possible. You can try to do it yourself with scripts or entrust this work to specialized automation tools. It will help your security team grow and accelerate security operations in line with the development practices, such as code analysis, vulnerability detection and mitigation, configuration management, etc.
Thus, once you automate security testing, backup processes, and other procedures, you will be able to detect security flaws and vulnerabilities early on without slowing down your pipeline from one side and saving time for your DevOps and security teams to focus on their core duties from the other.
Backup your DevOps environment
Being the final line against ransomware attacks, backup allows DevOps teams, software development teams, operations teams, and security teams to have peace of mind that they can easily restore all their critical data in any event of a disaster – infrastructure outage, git hosting downtime, human mistake, etc. What is critical here is the possibility of restoring DevOps data with a click without interrupting workflow continuity.
Let’s look at the features your DevOps backup should include to empower you with comprehensive and reliable backup as a security measure for your GitHub, Bitbucket, GitLab, Azure DevOps environment, and Jira ecosystems.
DevOps backup best practices
No matter which DevOps tool you use, GitHub, GitLab, Azure DevOps, or Atlassian’s Bitbucket and Jira, you need to be sure that your intellectual property, hours of work, reputation, and custom trust are steadfast. For that, you should ensure that your backup option covers three main aspects of backup:
- backup performance – to make it easy for you to operate with your backups,
- backup security – to provide the most secure features to protect your data,
- restore and Disaster Recovery – to guarantee fast restore under any disaster scenario.
Backup performance
Full data coverage
To be comprehensive, your backup should include as much information as possible. Thus, whether you back up GitHub, Bitbucket, GitLab, Azure DevOps, or Jira, your backup plan should have full data coverage in any deployment model.
Thus, when it comes to git hosting services, your backup plan should cover all repositories and their related metadata, including wiki, issues, LFS, webhooks, pull requests, issue comments, etc. In turn, backup for Jira Software and Jira Service Management should include all project management and communication data, such as Jira Assets, Jira Automation Rules, projects, Jira issues and comments, audit logs, notifications, attachments, workflows, boards, versions, and more.
Moreover, you should be able to set up different custom backup plans. It will help you adjust your data protection policy to the requirements, workflow, and structure of your organization.
The best practice is to have a few backup plans: one for unused repositories that you have to keep for future reference or compliance needs, and another for critical DevOps data that changes daily or even more frequently, such as when using the suggested GFS rotation scheme, or Forever Incremental.
Save your storage – incremental and differential backups
To minimize backup storage space, optimize backup performance, and control bandwidth, your backup solution should include only changed data from the previous copy. Ideally, you should have the possibility to specify various retention and performance plans for each kind of copy (full, incremental, and differential).
Different deployment models – SaaS and On-Premise
You should always have a choice… Thus, it’s vital that your backup software can be installed and run on both the cloud and/or your own infrastructure.
With a SaaS model, you may install it without having to set aside any extra hardware for a local server because the service is hosted on the cloud infrastructure of the provider. Its management and upkeep are taken care of for you, and the service provider ensures that it will continue to run.
When you deploy software on-premises, it is installed on a system that you own and manage, allowing it to function locally in your environment. The ability to install it on any computer – Windows, Linux, macOS, and even well-known NAS devices – is a great bonus. As the copies will be used within the local network, you won’t have to worry about network connectivity problems. What’s more, this deployment model will do backups quicker and more effectively as everything is run within your own infrastructure.
What’s important is that the deployment model of your choice should be independent of your data storage compatibility. For example, with GitProtect.io, you can both get the GitProtect unlimited cloud storage (which is always included in the license) and assign as many storage destinations as you need, whether they’re local or cloud. The backup provider supports AWS, Azure Blob Storage, Wasabi, Google Cloud Storage, Backblaze B2, or any other compatible with S3 cloud storage, on-premise storage instances (CIFS, NFS, SMB network shares, local disk resources), and hybrid and multi-cloud environments.
The 3-2-1 backup rule – a robust protection of your DevOps data
You should be able to create an infinite number of on-premises or cloud (preferably both) storage instances with your DevOps backup software. It will allow you to follow the 3-2-1 backup rule or other modern backup strategies (the 4-3-2 or the 3-2-1-1 backup rules), duplicate backups across storage instances, and eliminate any outage or event of a disaster.
GitProtect.io is a multi-storage system. It means that you can assign as many storage destinations for your DevOps backups as you need within your organization, legal, or compliance requirements. Thus, you can keep your copies:
- in the cloud (GitProtect Cloud Storage, Azure Blob Storage, AWS, Blackblaze B2, Google Cloud Storage, Wasabi, or any other public cloud S3-compatible,
- on-premise (SMB, CIFS, NFS network shares, local disk resources),
- multi-cloud or hybrid environments.
Once you decide to back up your DevOps tools with GitProtect.io, you will get unlimited GitProtect Cloud Storage for free. So, you can start protecting your DevOps data immediately.
Use Case: Let’s imagine that within your organization, and compliance needs, you should keep your data on [your Cloud Storage]. However, because of your consciousness, you decide to send your backup copies to your local device. Suddenly, one day, your git hosting service is down. What’s worse, [your Cloud Storage] experiences an outage, as well, and your organization’s workflow is paralyzed. Yet, don’t forget that you made some backup copies to your local device, so you can instantly recover your data with a click. All you need to do is log in to your GitProtect.io account, pick up the backup plan assigned to your local device, choose the last copy (it depends on the frequency of backups you set up), and recover the data. With the backup solution, you have different restore options – restore to the same git hosting provider’s account, to your local machine, or cross-overly to another git hosting platform (e.g., from GitHub to GitLab or Bitbucket).
Real-life story: IowaComputerGurus, a US leading supplier of custom application solutions based on Microsoft .NET Technology stack that provides exceptional design, development, website, and performance optimization services, uses GitProtect.io’s multi-storage opportunities to ensure the company’s GitHub data protection. Read the full story – IowaComputerGurus:
With source code being our most critical asset, knowing that it is protected and in a verified additional location gives us great comfort, even if we hope we never need to go back and retrieve it.”
Mitchel Sellers, CEO/Director of Development at ICG
Backup replication among storage instances
Backup replication is one of the most crucial factors you should keep in mind when deciding on backup software. Replication between storage instances helps to adhere to the 3-2-1 backup rule, as it provides you with the possibility to maintain consistent copies in several locations, ensuring redundancy and business continuity. Moreover, your backup software should permit you to replicate your DevOps data from any to any data storage, including cloud to cloud, cloud to local storage, and locally without any limitations.
GitProtect.io, for example, allows you to set up a replication plan within the menu of the central management console. To get started, you should simply specify the source and target storage, agent, and basic schedule.
Flexible and unlimited replication
Replication can become one of the most critical features when choosing a backup provider. The thing is that most SaaS providers provide a retention period for your data only from 30 up to 365 days by default. However, it’s not enough. Depending on the industry, the type of data you store in your repositories, how long you have to keep them, and when the data should be restored in the event of a failure, some businesses may need to retain some types of data for years.
Thus, you should be able to define retention within:
- the number of copies you need to keep,
- the time of each copy – how long your copy should be kept in storage,
💡 Important that you should have the possibility to set those replication parameters separately for the full, differential, and incremental backups.
- keep copies infinitely for archive purposes.
Monitoring Center – the DevOps security in your hands
Even if you’re not in charge of managing the backup software directly, you still can be responsible for keeping an eye on the backup performance, status updates, or maybe checking the one whose duty is to make changes to the settings that can affect your administrators. To put it simply, you need to have a monitoring center that is complex and tailored.
Custom email notifications and alerts are among the simplest methods to remain up-to-date without even logging in. That’s why you should be able to set up:
- backup plan summary details, including successfully finished tasks, ones finished with warnings, failed, canceled, and not started tasks,
- recipients, so that you don’t even need to have an account within your backup software infrastructure to stay informed about backup statuses,
- restore verification summary to have a full picture of your restore operations when you need them,
- storage capacity notification,
- status report of your plan,
- SLA report for compliance needs.
In the perfect scenario, for your DevSecOps team’s convenience, you should have backup notifications sent to the software your team uses on an everyday basis, like Slack, which is a staple for DevOps to collaborate and communicate. With Slack notifications, you won’t miss any important information regarding your backup.
Also, it should be possible for you to view the status of tasks in progress and historical events. If your backup software provides you with the tasks section, you will always have an understanding of actions in progress, along with comprehensive information at hand.
Moreover, you need to have access to advanced audit logs through your GitHub, GitLab, Bitbucket, or Jira backup software. All of the information on the operation of services, software applications, backups, and data restore is usually kept in logs. Additionally, audit logs permit you to see which actions your admins perform. That can help to prevent some intentional malicious activity from their side if a case like that arises.
Another way to make monitoring simpler and less laborious for your development and operations teams’ side is enabling the possibility of connecting those audit logs via webhooks and API to your external monitoring system and remote management software, like PRTG.
What’s more, you should make sure that all the mentioned information – backup and restore management, monitoring, and other system settings are easily available from a single central management console. There you should be empowered with powerful visual statistics, data-driven dashboards, real-time actions, SLA auditing, and Compliance reports.
The best way to bypass throttling – a dedicated GitHub/Bitbucket/Azure DevOps/GitLab account
When it comes to large corporate customers, it’s recommended to create a dedicated GitHub, Bitbucket, Azure DevOps, or GitLab user account that you can connect to your Git backup software. This account you should use only for backup purposes. In this case, you will catch up with two issues:
- boost your security, as the user of this dedicated account will have access only to the repos it needs to protect,
- bypass throttling, as each GitHub, Bitbucket, Azure DevOps, or GitLab user has their own pool of requests to the Git hosting API. It means that all the applications linked to this account operate within the same number of requests. As a result, your team can avoid these restrictions and carry out backup operations without any delays or limits thanks to the separate user.
However, if your organization is too big and possesses numerous repositories, you should think about creating a few dedicated users for backup purposes on your Git hosting service. Thus, once the first one exhausts the number of API requests, you won’t need to attach another one – it will be done automatically, and the same procedure will happen to the next one. What is the result? Even the largest DevOps environment continues to function without interruption during the backup performance.
Backup Security
DevOps backup solution for SOC 2 and ISO 27001 compliance
Security is shown to be a top priority for the majority of businesses. Let’s not forget that source code is the most valuable asset for any IT-related business. That’s the reason your repository and metadata backup have numerous security features that can assist you in following the Shared Responsibility Model, strengthening your company’s security posture, and guaranteeing data accessibility and recoverability. So to say, your DevOps backup software should enable your organization to maintain regulatory compliance while empowering your development and operations teams, as well as security teams.
You should make sure that your software provider and the Data Center where your service is hosted follow international security standards, audits, and certifications like SOC 2, ISO 27001, FISMA, HIPAA, GDPR, etc.
Here are the issues your backup software should successfully meet:
- AES encryption with the possibility to create a personalized encryption key,
- in-flight and at rest encryption,
- the opportunity to set the needed level of retention – flexible, long-term, and unlimited retention,
- the potential to archive old, unused repositories according to your legal and organizational requirements,
- all-in-one central monitoring and management,
- multi-tenancy and privilege-based access control,
- strict security and legal measures for the Data Center,
- ransomware protection for 360 cyber resilience and compliance,
- Disaster Recovery under any failure event and instant restoration.
In-flight and at-rest AES encryption
There is no way to talk about data protection without an appropriate and reliable encryption level. You should encrypt your data at every stage: while and before it’s on your device, during the data transmission, and finally at rest in your repository. Moreover, you should make sure that your software is encrypted with the Advanced Encryption Standard (AES). Since AES, which uses symmetric keys, the same key is used for both data encryption and decryption, is considered an unbreakable one.
Ideally, you should be able to set an encryption level and strength for your data, choosing any of:
- low – the one that requires a 128-bit encryption key (Cyber-Block Chaining mode) of the AES algorithm,
- medium – the one that operates in the same CBC mode as the low, but with a longer encryption key (192 bits),
- hight – operated within the same CBC mode as low and medium but more secure encryption key – 256 bits.
💡 It’s important to note that backup time depends on the selected method of encryption. Also, it makes the load on the end device or selected features limited. That’s why you should have a choice between different levels of encryption, all of which are still unbreakable.
Having your personal encryption key is essential to robust encryption and role-based access control. To safeguard user access and data, the majority of providers simply generate encryption keys. Yet, GitProtect goes one step further by letting you customize your unique encryption key. You can provide a string of characters based on which your personal encryption key is generated. What’s more, you will be able to provide us with your key only during the backup process using your own Vault. That will give you more control over your credentials and access and will enhance your data protection security.
Zero-knowledge encryption protocol
Have you heard that it’s crucial for your device to be unaware of the encryption key? It should get it only when the backup process takes place. You are the only one who knows the key in this case, even your device has no information about it. Security personnel usually call this method a zero-knowledge encryption. Thus, when you pick up a backup solution for your DevOps data, ensure that it provides all AES data encryption methods, allows you to create your personal encryption key, and enables a zero-knowledge approach.
Data Center – choose your preferred region
If you’re security-conscious and build your business on solid, secure principles, you understand how critical it is to have a full picture of your data stored and managed. Your backup software provider’s Data Center location may affect uptime, coverage, and application availability. That’s why choosing the most appropriate location to store your data is vital. You have this option right away with GitProtect.io; upon signup, you will need to choose whether to keep your management service in a Data Center located in the US (Washington DC.), the EU (Amsterdam), or the APAC region (Australia).
What’s important is that the Data Center you choose adheres to the stringent security regulations and is certified within ISO 27001, EN 50600, SOC 2 Type II, EN 1047-2 standard, FISMA, SOC 3, DOD, HIPAA, DCID, PCI_DSS Level 1 and PCI DSS, LEED Gold Certified, SSAE 16, and LEED.
Other things that should catch your attention are physical security measures, fire safety and suppression, regular, frequent audits, and round-the-clock network and technological support.
Employee accountability sharing can improve your team’s morale, don’t you agree? Moreover, it can help your team to speed up operations and have a better view of the business. That’s why, with your DevOps backup, you should be able to add new accounts, set privileges and roles to assign and delegate responsibilities to other members of your team and administrators. All of that will allow you to have more control over data protection and access controls.
The central management and monitoring console is the answer to this issue. With it, you can have audit logs with the full picture of the activities taken inside the system – which actions are performed, who made those changes, etc.
Ransomware protection for cyber resilience and compliance
Since backup is the last line of security against ransomware, it has to be immutable and cyber-proof. To make sure that it is, you need to be attentive to the way the backup vendor processes your data. For example, with GitProtect.io, you can have peace of mind that your data is compressed and encrypted to prevent it from being executed on storage. Thus, even if ransomware manages to access your backed-up data, it won’t be able to run and spread on the storage.
For on-premise installations, the agent only receives the authorization data for storage and your Git hosting service while the backup is running. What’s more, these details are kept in Secure Password Manager. Thus, in case ransomware infects the device our agent is on, it will have no access to the storage or the authorization information.
However, even if ransomware manages to encrypt your DevOps data, you should have the option to restore your chosen data from any point in time when your data wasn’t infected.
What’s more, if a backup vendor offers you storage technology that is immutable, and WORM-compliant, so to say, writes each file only once while reading it several times, it will make our DevOps data resistant to ransomware – impossible to modify or delete.
Disaster Recovery
Restore and Disaster Recovery – use case & scenarios
When you are facing the need to find the appropriate backup and recovery software for your DevOps environment, you should pay a lot of attention to the Disaster Recovery technology it provides. The main thing is that it should empower you to respond to any possible data loss scenario. While some solutions may offer basic recovery options for your git hosting downtime, true resilience demands readiness for more complex and critical situations inherent in the DevOps landscape.
Here are the restore options that GitProtect.io provides to help you withstand every disaster scenario possible:
- point-in-time restore,
- granular restore of the repositories and metadata you urgently need,
- restore to the same or a new repository or organization account
- restore to the local device of your choice
- cross-over recovery to another Git hosting platform, for example, from GitHub to GitLab, Azure DevOps, or Bitbucket, and conversely.
Moreover, GitProtect.io, unlike other providers, allows you to set up backup plans, monitor their performance, and run a restore of your backups from a single place – a central management console. So, you don’t need to install additional apps.
What if your GitHub/GitLab/Azure DevOps/Atlassian is down?
A Git hosting provider outage is probably one of those circumstances when you need to retrieve your DevOps or Project Management data fast to guarantee your team’s uninterrupted workflow. In such a disaster scenario, you should have the possibility to quickly restore your entire DevOps environment from the most recent copy or a specific point in time to your local operating system (if we speak about GitHub, Azure DevOps, Bitbucket, or GitLab, make sure that you can restore your data as .git).
Among the other options you should have are the possibility to restore your Git hosting local instance – GitHub Enterprise, GitLab Ultimate, Azure DevOps Server, or Bitbucket DC, or use the cross-over recovery option to restore your software development data to another Git hosting service.
When it comes to Jira with your software development and production data, you should be able to recover your Jira production environment to your local machine, the same or absolutely another free Jira instance.
What if your infrastructure is down?
Don’t forget that the 3-2-1 backup rule is unquestionably one of the most effective backup strategies. What else to say? It has gained widespread acceptance as a data security standard. Its core is that you have at least 3 copies in at least 2 different storage locations with one off-site.
As GitProtect.io is a multi-storage system, you can add as many on-premise, cloud, hybrid, or multi-cloud storage instances as you need. What’s more, you can easily set up backup replication across them. Thus, you may be certain that you will be able to recover all or only specific data from your second storage device at any time, even if your first backup storage is down.
What if GitProtect.io’s infrastructure is down?
As we rely on data security, we must be ready for any event of failure, especially if it threatens our infrastructure. In the case our infrastructure is down, we will provide you with an installer of your on-premise application. After that, all you will need to do is to log in and assign the storage where you keep your copies. That’s it, you have access to your backed-up data and can use any of the restore and Disaster Recovery options mentioned above to restore your critical software development and production data.
Restore multiple Git repositories or Jira projects at a time
There are various circumstances when you may need to restore your entire production and/or DevOps environment – service outages, downtime, etc. Restore and Disaster Recovery technologies that you can perform in a click are becoming decision-makers. After all, the main purpose of backup is to enable a fast restoration process for your critical data in the event of a disaster.
What’s the easiest way to do it? The ability to restore multiple GitHub, Azure DevOps, GitLab, or Bitbucket repositories and Jira production data. To make your disaster recovery plan simple, quick, and effective, you should have the possibility to select the repositories or projects you need to restore, view the most current copies, assign them manually, and restore them to your local device, another Git hosting service or, if it comes to Jira production data, to another Jira account.
💡 Attention to Jira users: According to Jira’s billing model, you have to pay for each user who uses the application. So, the potential restore of Jira users may seem an issue. Theoretically, restoring your entire production environment may cost twice as much as you do since you will need twice as many people, right? Nope… that’s not. With GitProtect.io’s no-user recovery option, you can easily restore all your Jira data but for users without exceeding your current Jira pricing plan. Additionally, this feature allows you to restore your data to a free Jira account.
Point-in-time restore – no limits to the last copy
Human mistakes is a common cause of cybersecurity risks and data loss; they can even lead to outages – in April 2022 Atlassian Jira experienced a massive outage that lasted for almost 2 weeks. There is no difference if we speak about git repository data or production data – it’s always difficult to predict from where the threat can come. You can face unintentional deletion of your critical data, or, in the worst scenario, an intentional one, but still, in both cases, all you will need to do is deal with the consequences. Having a backup plan up in your sleeve, you can restore your critical software development and production data with a click; all you will need to know is the time when a disaster took place, and then run your backup copy from the precise moment you need.
It’s worth mentioning that most backup providers allow you to restore only the last copy or the copy from up to 30 days prior. But what if you notice some human mistake, let’s say, in 6 months? Then, a backup solution with point-in-time restore capabilities and unlimited retention is more than a need.
Restore to your local machine
Well, GitHub, Bitbucket, Azure DevOps or GitLab SaaS versions may be your user option. However, you should have the possibility to restore your copies to your local machine at one time or another. What are the reasons? Service outage, Cloud infrastructure downtime, or poor internet connection. That’s why your backup software should allow you to restore your entire Git environment to your local machine in addition to other restore options.
What’s more, you never know when the event of failure hits your DevOps environment. So, your backup software should also offer you alternative options – cross-over recovery to another Git hosting provider, restore to the same or a new GitHub, GitLab, Azure DevOps, or Bitbucket repository.
No overwriting of repos during the restore process
Isn’t it convenient to have your repository restored as a new one rather than overwriting the original GitHub, GitLab, or Bitbucket repository? You may need to leave the original one for tracking the changes or just keep it for future reference. However, security is the main consideration here. Additionally, in this case, you get full control over your repository, deciding whether you should keep your repo or delete it.
Granular restore of only selected data
There may happen different situations – unintentional deletion, human errors, mistakes in daily operations – when you don’t need to restore your entire production or DevOps environment. In this case, you should be able to restore granularly only the data you urgently need. In the case of DevOps, it may be repositories or specific metadata, while in Jira, it can be projects, workflows with their dependent elements, and issue attachments.

Moreover, your backup provider should permit you to recover your software development and production data to the same or a new account, to your local device (or cross-overly to another git service, when it comes to git environments). That’s it – you have your data restored in the blink of an eye without interrupting your workflow.
Find out more about restore and Disaster Recovery requirements for each of GitHub, Bitbucket, GitLab, Azure DevOps, and Jira:
📌 Bitbucket restore and Disaster Recovery best practices
📌 Jira restore and DR best practices
📌 GitLab restore and Disaster Recovery – how to eliminate data loss
📌 GitHub restore and DR – scenarios & use cases
📌 Azure DevOps restore and Disaster Recovery
Enhance security & DevOps processes with backup
Understanding security incidents and threats that your production and DevOps environment can face – outages, infrastructure downtime, cyber attacks and ransomware, human mistakes, security breaches, etc. – needs proactive actions from both your operations teams, software development teams, and security teams to boost your software supply chain.
Thus, building a reliable and comprehensive data protection strategy for GitHub, Bitbucket, and Atlassian tools becomes a must-have in today’s reality. This strategy should not only include security testing, such as static application security testing, automated security testing, dynamic application security testing, and interactive application security testing but also it should contain other security processes. They should include:
- DevOps backup
- implementation of software composition analysis
- controlled privileged access management with restrict access
- automated processes
- application programming interface (API) management
- vulnerability management
- cloud security
- the possibility to automate software provisioning
- secure code practices
- configuration management
- short and frequent development cycles
- secrets management
- security scanners and much more
And, of course, don’t forget about checking the effectiveness of your DevSecOps approach, for example, using static code analysis or conducting security training for all employees within your organization.
It’s important that your security teams’ focus is on integrating security at every stage of your software development lifecycle (SDLC) to withstand any DevOps security challenges, guaranteeing your business continuity.
The article was originally published on February 28th, 2024
Before you go
🔎 Learn more about Atlassian data resilience for Jira Admins in our comprehensive guide
📚 Download our GitLab backup Guide and GitHub backup guide to always have all the necessary information at hand
🔎 Check out why repository and metadata backup, Disaster Recovery, and Compliance are an unbreakable trio
📅 Schedule a custom demo to learn more about GitProtect.io backups for DevOps tools to ensure your continuous workflow
📌 Or try GitProtect.io backups for GitHub, Bitbucket, GitLab or Jira environments to eliminate data loss and ensure your business continuity



