


GitLab Shared Responsibility Model: A Guide to Collaborative Security
Read the full article and learn what duties organizations have within the GitLab Shared Responsibility Model. Find out how to reduce your obligations and improve your GitLab data protection. Test a GitLab backup solution for free during a 14-day trial period.
GitLab is a popular DevSecOps and collaborative software development platform that enables businesses to automate software delivery, boost productivity, and secure end-to-end software supply chains. However, not everyone knows that like most SaaS service providers, GitLab operates according to the so-called Shared Responsibility Model (or Limited Liability Model).
This model recognizes the responsibilities of each party at the very moment when a customer creates an account on GitLab and starts using this service. But, do all the users know what responsibilities they have at the beginning? Not sure.
Thus, let’s try to understand what is a GitLab Shared Responsibility Model and what obligations each of the parties has to follow in order to achieve the code repository security.
To make a long story short, the Shared Responsibility Model is a framework for cloud security that defines the security duties for both SaaS providers and their users. It defines that a provider takes care of the infrastructure, and the entire service while a customer should think about his own data and related metadata.
Though GitLab provides a rather full package of tools, including backup and retention schemes, it is always a good idea to know what is really included in the service and what you, as a customer, should think of.
Being transparent with its documentation, GitLab states: “As part of GitLab Inc’s contracting process, GitLab provides all terms and conditions with our customers to ensure all parties understand the shared responsibility model.” So, let’s dive deeper and look closely at the GitLab Subscription Agreement where the Git hosting service states all the responsibilities of both parties – its own and its users.
What is GitLab responsible for?
If we peer into the GitLab Subscription Agreement mentioned above we will notice that “GitLab shall be responsible for establishing and maintaining a commercially reasonable information security program that is designed to”:
- guarantee the confidentiality and security of GitLab user’s content;
- guard against potential threats to the security of the user’s content;
- prevent unauthorized access or unauthorized use of the user’s content;
- make sure that GitLab’s subcontractors, if there are any, abide by the aforementioned requirements.
It sounds security-proof, doesn’t it? Moreover, if we look at the GitLab Trust Center, we can see that GitLab has a proven compliance and assurance credentials path. The service provider has passed numerous security certifications, including SOC 2 Type 1 and 2, SOC 3, ISO 27001, ISO 27017, GDPR, and others. Thus, it has high-security standards to protect its data: “In no case shall the safeguards of GitLab’s information security be less stringent than the information security safeguards used by GitLab to protect its own commercially sensitive data” (Subscription Agreement: Security / Data Protection).
So, GitLab is responsible for access to the platform and the infrastructure, backup which is run on the same Linux server as GitLab, configurations and maintenance modes, upgrades (here it’s worth mentioning that GitLab isn’t available when the update is in progress for single node installations), and infrastructure-side Disaster Recovery.
And what about the user’s data? Here is what is stated in the same document:

So, are the users responsible for their data? Yup… Let’s continue talking about it…
A Customer’s Responsibility: Deep Analysis
While GitLab takes care of the entire system, a customer is responsible for his authorization credentials and all the data in his code repository. It can include Repositories, Wiki, Issues, Issue comments, Deployment keys, Pull requests, Pull request comments, Webhooks, Labels, Milestones, Pipelines/Actions, Tag, LFS, Releases, Collaborants, Commits, Branches, Variables, GitLab Groups. So as not to sound unfounded, take a look at what is stated in GitLab documentation:
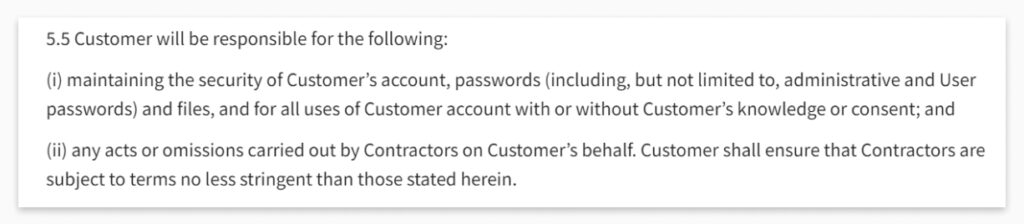
Once again, users are responsible for the security of their accounts, “passwords, and files”. It means that if something, for example, accidental or intentional deletion of the data takes place, the customer’s problem is figuring out how to restore it if possible.
Don’t forget it’s a myth that if your account data is deleted or corrupted GitLab can recover it. Read our blog post from the DevSecOps MythBuster series where we have already debunked this myth: “GitHub / Atlassian / GitLab handles backup and restore” – busted!
After figuring out which security obligations both parties have, we should definitely speak about cooperation… As the GitLab Shared Responsibility Model, like any other of its type, emphasizes the collaboration between the platform provider and its users. Here are the key aspects that are worth mentioning as well:
Education and training
There are thousands of resources and documentation that GitLab prepares to educate its users about best security practices. Thus, in turn, users should always try their best to stay in the loop – read documentation, blog posts, and undergo security training to boost their security skills.
Feedback and reporting
As it has already been mentioned GitLab encourages its users to provide timely feedback about any issues they face. By promptly reporting vulnerabilities or any suspicious activity, users not only play an active role in the security ecosystem but also help the provider respond to the issues faster.
Continuous improvement
As any other SaaS provider, GitLab regularly updates its product. So, it’s critically important for the users to follow these updates as they are usually aimed at improving user experience and security.
What can go wrong?
Human mistakes, ransomware attacks (which are on the rise now!), service provider’s outages, or your own infrastructure outages – all of that can severely impact your business continuity and, what’s worse, lead to data loss. Why not track the history of incidents and see on Use Cases why your GitLab data needs proper protection?
GitLab’s backup failure
Let’s just remember the year 2017 when the worst incident in GitLab’s history took place. Due to the accidental deletion of data, GitLab suffered an outage and needed urgent database maintenance. The service provider’s backup failed to restore, and, consequently, users who used the SaaS solution suffered data loss:
“The company has reached out to confirm that the outage only affects GitLab.com – meaning that customers using its platform on-premise are not affected.”
TechCrunch
Proxyjacking and cryptojacking malware attack on GitLab
In August 2023 researchers from Sysdig were alerted to a persistent campaign of attacks targeting vulnerable GitLab servers that resulted in the deployment of proxyjacking and cryptojacking malware, leveraging the platform’s resources for the attacker’s own gains.
Though, GitLab effectively addressed and patched the mentioned vulnerabilities labeled as 13.8.8, 13.9.6, and 13.10.3 in April 2021, “individuals who failed to apply these patches have now become targets for the LABRAT threat.” – states Cybersecurity Insiders.
Is there anything DevSecOps teams should be aware of?
If a company is really conscious about its repository data, it will think about backup – it’s nice to have the possibility to roll your data back in case of a failure. They can make up their own backup options, such as backup scripts, clones, and snapshots, or use any other GitLab backup option. But at the same time, they should keep in mind that they will need to do it manually, which is time-consuming and takes a lot of resources.
Well, it may seem easy and cheap but in the long-term perspective, it will be tiring and cost-ineffective. Why? In short – in a situation like that, somebody from the company will need to switch from his usual duties to provide backup copies. He will need to make those backup scripts, snapshots, and clones, keep his hand on the pulse to delete the old ones because they can waste a lot of storage space, and, when it is needed, write the script to restore the data. So, your developer will be always distracted from his core duties, which will affect his productivity.
Is there any other option to back up the data?
The solution is on the surface! A lot of SaaS providers don’t exclude the possibility of turning to a third-party backup and recovery solutions. In this case, companies can rely on professionals who will help them reduce their responsibilities and compliance. For example, GitLab backup by GitProtect.
If a customer decides to share his responsibilities with a third-party backup provider, he can get automated backups and data protection using the most popular and reliable backup rule, the 3-2-1 strategy. Under this rule, you can have three copies of your data in two different locations including one outside the company. This sounds great because GitLab gives the possibility to store all the data only on the same Linux server as GitLab. Also, it is possible to set up more advanced retention schemes, like FIFO, GFS, or Forever Incremental, which will surely help when you need to restore your data, whether it is point-in-time or Disaster Recovery.
We have mentioned that GitLab, like any other SaaS service, provides its customers with a retention option, but it is always limited. Some companies may need to keep their data for long periods due to their legal regulations or archive purposes. Thus, they may need long-term retention options. When a third-party backup service steps in, it is possible to get unlimited retention for backup copies. It means that all your information, even the oldest one, can be kept in a safe place and easily restored at any time you need.
Another point we need to pay attention to is updating. For single-node installations, GitLab isn’t available when the update is proceeding. In this case, a third-party solution can relieve the stress again. In situations like that you shouldn’t stop your work and wait, you can restore your repository using cross-over recovery to another platform, like GitHub or Bitbucket, and continue your work.
Conclusion
Once you decide to use a service, it is always good to know the legal side and the responsibilities of the parties. Because, when you know what to do, what responsibilities you have, and what to expect, you won’t be taken aback.
The way the so-called Shared Responsibility Model defines the roles is that it is always a customer, who should protect their data because he is a data owner. The SaaS provider, in our case, GitLab is just a data processor, who can process the data when and if the data owner permits. And if the customer – data owner – wants, he can add a data guard (a third-party backup and recovery solution) which will guarantee data accessibility and sustainability.
See yourself how backup software can help you reduce your responsibilities!
[FREE TRIAL] Ensure compliant GitLab backup and recovery with a 14-day trial 🚀
[CUSTOM DEMO] Let’s talk on how backup & DR software for GitLab can help you meet the Shared Responsibility Model



