


“GitHub / Atlassian / GitLab handles backup and restore” – busted!
Welcome back(up) to the DevSecOps MythBuster series! If somehow you have missed our first article, you definitely need to catch up (save the link).
But the carousel of myths keeps turning… so let’s jump in and debunk another two of the most common misconceptions… <drum roll sound 🥁>
MYTH #2
If my account data is deleted or corrupted, GitHub / Atlassian / GitLab / (put any SaaS here) is able to recover it
There is no point in elaborating too much. Have you heard about the Shared Responsibility Model?
Atlassian, GitLab, GitHub, Microsoft, Google, and seriously – put any SaaS here – operate according to the so-called “Shared Responsibility Model”. This concept has evolved with the introduction of plenty of SaaS tools and has become a standard used in legal policies by almost all possible vendors now. It assumes that both provider and customer have their responsibilities resulting from the use of SaaS platforms. While the official names of such documented rules can differ, all of them are based on nearly the same rules – especially when it comes to data protection.
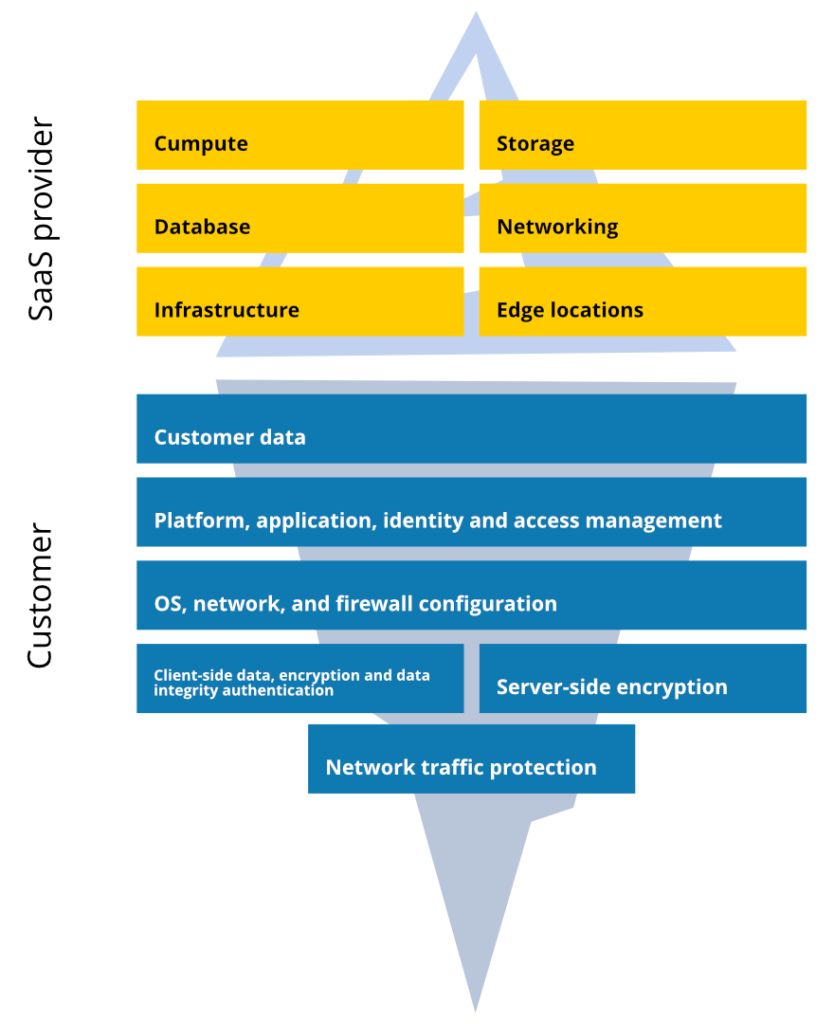
In short: service providers are responsible for their systems, hosting, and applications focusing on their own business and integrity at a macro level. Most of them provide 99.999% availability and uptime, preventing infrastructure from failures, errors, attacks, etc. However, when it comes to data protection at the account level, the user is responsible for data security and should be able to restore lost, stolen, deleted, or compromised data. Seems reasonable and obvious. After all, it’s user data, right?
⚠️ Know your responsibilities:
◾ Data availability and security.
◾ Recovering from operational data loss, human error, or ransomware attack.
◾ Meeting compliance and long-term data retention.
◾ Following the 3-2-1 backup rule with multiple storages, and offsite copies in case of outages and downtime.
◾ Data encryption and integrity.
More about:
Atlassian Cloud Shared Responsibility Model
GitHub Shared Responsibility Model
However, in order not to be unfounded, let us quote fragments of such regulations:
“We do not warrant that your use of the cloud products will be uninterrupted or error-free, that we will review your data for accuracy, or that we will preserve or maintain your data without loss”
Atlassian Cloud Terms of Service
“We are not responsible for any of your data lost, altered, intercepted, or stored across such networks. We cannot guarantee that our security procedures will be error-free, that transmissions of your data will always be secure […].”
Atlassian Cloud Terms of Service
[…] we will not be liable to you or any third party for any loss of profits, use, goodwill, or data, or for any incidental, indirect, special, consequential, or exemplary damages […].
GitHub Terms of Service
“Customer is responsible for implementing and maintaining privacy protections and security measures for components that Customer provides and controls.”
GitLab Subscription Agreement
Atlassian, GitHub, or GitLab (and any SaaS) claims to perform system-level backups and disaster recovery operations in case of infrastructure failure, attack, etc. to ensure uptime and accessibility. But let’s be clear – it’s impossible for them to perform restores of each of their tenants’ account data. Account-level recovery is non-trivial to develop and typically lies outside their responsibilities. That’s why they require each tenant to protect their own data and to avoid such expectations, most of them, including Atlassian, plainly state: “To avoid data loss, we recommend making regular backups.”
Checkmate.
This myth often goes hand in hand with another very popular yet even more untrue statement…
MYTH #3
GitHub / Atlassian / GitLab / (put any SaaS here) handles backup
Now, let’s look at the other side of the coin. Most of those vendors – GitHub, GitLab, or Atlassian offer some limited built-in backups or checkbox exports. Despite this, they still recommend third-party tools. For example, GitLab plainly mentions GitProtect as a standalone GitLab backup on their website. Why?
Well, built-in tools often come down to making a manual export or instance snapshot with a limited frequency via their API. This process addresses some basic data protection needs with limited data coverage, ignores a number of security aspects offered by standalone software, and requires a great deal of discipline from users in supervising and managing exports. It’s a manual process – so you need to remember to export your data on a regular basis and manage such “copies” on your own storage to not overload it in the blink of an eye. Moreover, you need to delegate responsibilities as well as track and monitor its correct execution.
In fact, while Atlassian/GitHub or GitLab’s built-in export tools serve as a basic solution for specific users, they may not fully address the complex needs of organizations seeking a comprehensive and dependable backup system. Among the most common limitations are:
- Data export, not backup
- Limited data coverage
- No automation – manual export every 24 or 48 hours
- Scripting required (if you want to somehow automate the process, you need to write your own script for export and restore)
- No granular recovery – account-level restoration only (all or nothing)
- No retention and rotation settings
- Lack of storage and additional infrastructure cost
- Various problems with restoring such exports (manual import, no granular restore, account-level restore only, overwriting data, and no restore guarantee).
Find out more: Decoding the Ultimate Choice: GitProtect Jira Backup vs. Atlassian’s Built-in Backup Abilities
While exports might seem a piece of cake, various problems might occur while trying to somehow restore some deleted or corrupted data. First of all, those tools consider restores as imports. Such imports can be performed only at the account level, without support for item-level, granular restore. It means you can restore all exported data or nothing that becomes unuseful in case of accidental item deletion and daily operations.
Such import requires manual steps including unzipping, organizing, and executing imports, increasing complexity and risk of potential errors. Moreover, such import takes place in the production environment which involves a lot of stress related to the correctness of the recovery process.
Let’s quote Atlassian one more time: “To avoid data loss, we recommend making regular backups.”
Backups, not exports. Make sure your backup software provides you with:
- Full data coverage (including all metadata),
- Automation and flexible scheduler
- Full, incremental, and differential copies
- Unlimited retention to meet your legal/SOC 2 requirements
- Free unlimited storage and compatibility with a plethora of external storage instances, including S3 or on-prem (backup 3-2-1 made easy)
- Granular restore, cross-over recovery and data migration to a different vendor, and more Disaster Recovery Technologies
- AES encryption with your own key, at rest/in-flight encryption, ransomware protection package, SAML integration, and more security features.
- Central management, audit logs, reports, notifications, and more for your peace of mind.
[FREE TRIAL] See for yourself – start a 14-day free trial 🚀
[LIVE DEMO] Let’s discuss your needs and see a live product tour



