
Azure DevOps Restore and Disaster Recovery
Make sure that all your Azure DevOps data is secured in any event of failure. Try GitProtect backup and Disaster Recovery software for Azure DevOps and prevent any data loss scenario.
The IT industry nowadays is growing faster than ever before, and with it, there are potential threats that could negatively impact your business. Being able to recover quickly from any event of a disaster should become a key aspect of your cyber defenses.
Therefore, in this article, we will focus on the importance of a reliable DR and restore strategy. So, let’s talk about how to build your DR strategy to ensure your Azure DevOps data is always recoverable and available.
Potential risks concerning your Azure DevOps data
Before looking at the DR scenarios and use cases, or even starting building Azure DevOps Disaster Recovery Strategy, it’s worth defining threats that can influence your Azure DevOps business continuity. So, among those threats we can mention:
- Service outages and infrastructure downtimes
- Human errors, such as accidental deletions
- Cyber threats, e.g. ransomware, bad actors’ activity, unauthorized access, etc.
Real-world case – Massive Microsoft Azure service outage in the North American region
In August 2024, multiple Azure services for customers, including Azure DevOps, in North and Latin America were unavailable for more than 2 hours. The reason was a Microsoft Azure outage that took place at 18:22 UTC and impacted mostly Azure Front Door (AFD).
However, Azure DevOps customers reported errors with connecting to their services not only in North and Latin America but also in the United Kingdom.
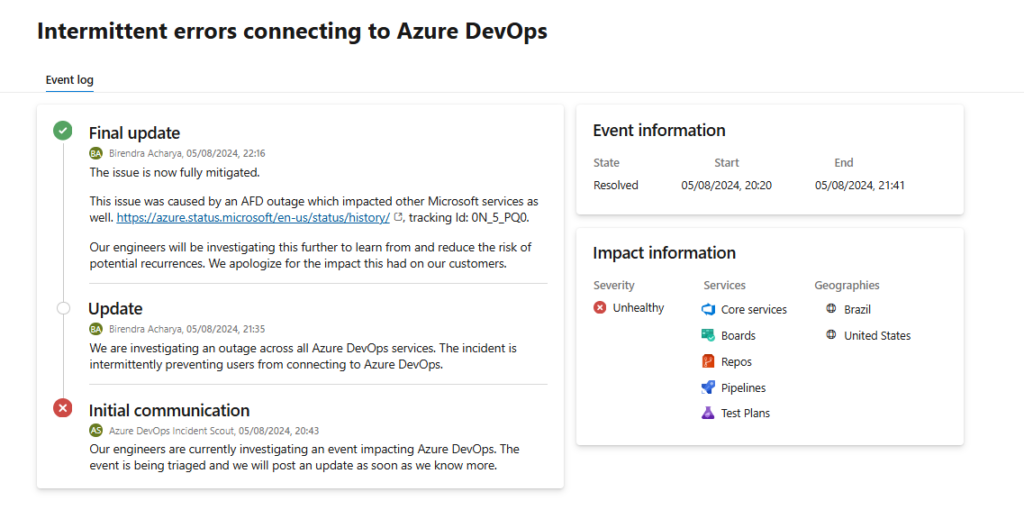
Source: Azure DevOps Status Page
Later, Microsoft explained that “This incident was triggered by an internal service team doing a routine configuration change to their AFD profile for modifying an internal-only AFD feature. This change included an erroneous configuration file that resulted in high memory allocation rates on a subset of the AFD servers – specifically, servers that deliver traffic for an internal Microsoft customer profile.”
How to build an effective DR strategy for Azure DevOps
Now that we are aware of the potential threats to Azure DevOps data, we can outline the key elements of an effective disaster recovery strategy.
Identify sensitive data
The first step in building your Disaster Recovery strategy for both Azure DevOps Server and Cloud versions is to identify the most critical data and workflows you need to protect. Your backup and DR software should cover both repositories, projects, and metadata to guarantee complete recovery in case of a security incident.
Once you pinpoint your active and most important repositories, projects, and other data, you can move on to choosing the appropriate security measures, including backup frequency, access controls, etc. – all the necessary measures to minimize or even eliminate the impact of any potential risks.
Plan Disaster Recovery procedures
The first few hours after the incident are the most critical. Thus, every action should be effective. To manage it, you should develop and document all the steps you and your team should take in case of a disaster to restore your business continuity as fast as possible.
Those procedures should include backup and recovery routines, a well-built emergency communication process, and activation and contingency plans.
Distribute responsibilities across your teams
It is crucial to not only educate your employees on the importance and steps of your disaster recovery strategy but also identify each team member’s role in that plan. You need to make sure that there is a person responsible for each step of your recovery process:
- to declare a disaster,
- to report about the disaster to management,
- to communicate with the press, customers, and third-party vendors,
- to manage the consequences of the event and fast recovery,
- to identify the reasons for the failure,
- to set up procedures to prevent such events in the future.
Moreover, it’s worth listing the names along with contact details and relevant obligations of everyone involved in your DR plan.
Ensure you have a failure mode analysis of your flows
When planning your DR strategy it is important to thoroughly implement a failure mode analysis (FMA) of your flows. You need to clearly identify potential points of failure and address mitigation processes accordingly. The main aspects include:
- Decomposing the workload
- Identifying dependencies
- Analyzing failure point
- Continuous detection
- Communicate the outcome
However, no matter what, failures can still take place, therefore it is important to design your workload using FMA to effectively address risks. Skipping this procedure can result in unpredicted behavior along with outages attributed to suboptimal design.
Have a communication plan for disasters prepared in advance
During a disaster scenario, effective recovery requires proper communication between relevant individuals. As a business, you may need to inform stakeholders, compliance authorities, clients, and employees. It is advisable practice to have message templates and communication channels along with a team that takes care of communications in case of a failure. As a result, when you experience a disaster event, your clients and shareholders’ trust should not be damaged.
Make sure you have a testing strategy for your DR
Before introducing your DR strategy, you should have it tested to verify its effectiveness. Testing could reveal new areas and aspects to address to further improve the recovery strategy along with the overall security of data. As you may know, there are different types of tests such as:
- Checklist testing – verification of procedures, like chains of command, integrity, and availability of backup systems.
- Walkthrough test – a review in the form of a step-by-step analysis.
- Simulation testing – you put your strategy against “what if” scenarios.
- Parallel testing – build and use recovery systems mirroring the production ones and run tests that resemble a real-life disaster event.
- Full-interruption testing – use real production data to deal with a fabricated disaster.
It’s a good idea to stay up-to-date with best practices for testing DR strategies. Among others, it is crucial to:
- Test frequently and create a schedule
- Document your tests
- Test employees, not only the DR solution
- Regularly analyze and update your strategy
Set your RTO
Recovery time objective is a metric used in disaster recovery strategies. It helps to determine the maximum amount of time the organization can endure being down. The lower your RTO is, the better your organization is prepared for the event of a disaster.
Make sure to balance cost efficiency with the effectiveness of processes. When your RTO is high you can cut costs but you may need to spend more money to get your data back, compensate for the downtime, and deal with the consequences of the disaster scenario.
If you invest in a third-party backup solution, that supports your lower RTO and guarantees smooth and immediate recovery in any event of failure.
Find your RPO
The next metric you need to keep in mind is the recovery point objective (RPO). This will help you to set the exact amount of time you need between backups and the amount of data that can be lost between them.
In short, if you set your RPO to 8 hours, that means that all of your processes and critical data should be recovered within that time frame. You will need to identify all of the critical data and how much of it you can afford to lose to keep your workflow uninterrupted.
If you carry out these analyses and figure that your company can easily proceed to work without data from the past 6 hours, then, your RPO is 6 hours. Similarly, if your RTO is closer to 15/20 minutes, it means that after this time your organization will no longer be fully operational. So, in that case, the company will require not daily backups but more frequent ones to accustom the lower RTO.
Regularly review RPO & RTO
Before you specify your RTO, you should carry out a strict evaluation of all of your systems. This way you guarantee that the identified RTO meets your organizational requirements.
Moreover, you need to systematically verify whether your backup and disaster recovery strategy still meets your RTO and RPO. Use replication, incremental, and differential backups, and granular restore, to evaluate and optimize your RTO and RPO metrics. When undergoing an audit make sure to have a clear overview of all the reports and logs to further support the continuous improvement of your RTO and RPO metrics.
Have a backup of your Azure DevOps environment to restore data fast
To guarantee comprehensive recovery capabilities it is crucial to pay attention to one of the fundamental aspects of any reliable DR strategy – backup. It is your safety net which can prevent you from data loss associated with accidental deletions, human errors, and ransomware. Ideally, your complete backup solution should include:
- Adherence to the 3-2-1 backup rule (have at least 3 copies, stored in 2 different locations, with one being stored off-site).
- Infinite data retention
- Replication between storages
- Versioning
- GFS scheme (Grandfather-Father-Son)
- Full, differential, and incremental backups
- Automation and scheduler
- AES encryption in-flight and at rest with the option to create your own encryption key
- Ransomware protection
- Scalability
- Clear monitoring capabilities of backup processes

Must-have restore options for your Azure DevOps data
As we have already said, to be ready to deal with disasters effectively you should have a reliable backup and disaster recovery strategy. The quicker you can resume your organization’s workflows after a catastrophic event, the better chances for long-term business continuity and success you have.
There are a couple of crucial features, that will support smooth, quick, and flexible recovery processes…
Point-in-time restores & unlimited retention
The ability to configure and perform a point-in-time restore of your Azure DevOps data in case of a failure is one of the key aspects. Hence, we should mention that point-in-time restore is closely linked to retention. Here we should mention that Azure DevOps has a maximum of 365 days of retention. And what if the repository or branch deletion happened more than a year ago and went unnoticed for some time? You won’t be able to restore it and your data will be lost.
However, if your backup solution provides you with long-term or unlimited retention, you will be able to restore your data from any point in time in the past, even from 3 or 5 years before.
Granular restore
Another key feature to incorporate into your cyber defenses is granular restore. By being able to specify elements and work items that you want to restore, for example, a specific repo or a team project, you shorten the time it takes to bring your data back. It happens as you do not have to recover everything but rather just the elements of your Azure DevOps environment that you specified.
Full data recovery
Depending on the situation, you may need to recover your entire Azure DevOps environment. Thus, make sure that you can perform multiple repository restore to different locations, including your local instance, the same or another Azure DevOps on-premise or cloud account, or cross-over restore to another git hosting service. These options will help you make your DR plan more efficient and robust.
Cross-over recovery
Then, there may be a situation when you need to restore your Azure DevOps data to another git repository platform, like GitHub, Bitbucket or GitLab. The reasons may be different – business requirements, data migration, outages, etc.
Disaster recovery scenarios & use cases
There are several reasons why an organization would need a backup and disaster recovery solution. These include following the shared responsibility model, meeting compliance requirements, archiving, security, and more.
But what is most important for the organization is to stay on track with business objectives. Therefore, recoverability and continuous data availability which is necessary for your business to run smoothly is the main goal here. So, choosing the right backup and DR solution for your Azure DevOps is truly important and significant for business continuity!
Let’s take a look at some potential disaster scenarios, where efficient DR strategy can help you resume your business continuity fast.
Scenario # 1 – There is an outage of Azure DevOps services, what should I do?
In the case of an Azure DevOps service outage, you may be unable to access your data, and, thus, all your working processes can be stopped. In this situation, you should be able to carry out an Azure DevOps Disaster Recovery and restore a backup copy as soon as possible to get back to primary business objectives.
That’s the situation when you can benefit from multiple repository restore. Moreover, you should be able to restore your Azure DevOps data to different locations:
- restore data to your local machine from the last copy or some chosen point in time.
- recover to your self-hosted Azure DevOps instance. Moreover, if an issue only concerns specific accounts (and yours is one of them), you can just make a new Azure DevOps account and restore your data there – and within minutes you are back on track,
- Use cross-over recovery and restore your critical Azure DevOps data to another git hosting platform, including GitHub, GitLab, or Bitbucket.
Scenario # 2 What if your infrastructure is down?
In the situation when your own infrastructure is down, your backup solution should provide you with mechanisms to restore your Azure DevOps data and critical workflows. The 3-2-1 backup rule should be the foundation of your backup strategy. In this case, you have at least 3 copies in no less than 2 storage destinations with one offsite. Thus, if one of your storage destinations is down, you can restore your critical data from another one.
For example, GitProtect allows you to assign as many storage destinations, both cloud and local, as your security and compliance require. GitProtect permits you to add any storage compatible with S3, or NAS/local. What’s more, when you set your backup plan with GitProtect, you can always use included GitProtect Cloud Storage for free as the primary or secondary storage destination. Moreover, you can enable replication between those storages to always have several consistent copies in different locations.
Scenario # 3 Backup solution’s infrastructure is down
It’s critical for every backup provider to be prepared for its infrastructure downtime or any other event of failure. Thus, when you choose your backup provider, make sure that it has security procedures that can foresee such a situation.
Conclusion
The effectiveness of your Disaster Recovery plan and restore efforts is heavily dependent on the efficient backup strategy. Thus, make sure that your backup strategy for Azure DevOps is built within the backup best practices.
And here is another tip – when you need to restore your data from a backup, always restore it as a new one since it’s both important from the security point of view and it gives you the ability to track the changes in your source code.
[FREE TRIAL] Ensure compliant Azure DevOps backup and recovery with a 14-day trial🚀
[CUSTOM DEMO] Let’s talk about how backup & DR software for Azure DevOps can help you mitigate the risks



