


Git Forking Workflow
Recently I was talking to my friend about Open Source projects. That was a lively debate and we wondered about how to cooperate in such projects, of course from the technical point of view. How are they stored, how can you contribute to their development, and finally – who and how controls what the community adds to such a project. This inspired me to describe a mechanism called forking in Git because a lot of people have heard of it, but when you need to delve into the details, it turns out that not everything is so obvious. Let’s check how it works and what a forked repository is.
What is forking in Git
Fork and clone… Is it the same? Actually forking in Git in short means copying a project. This will copy the entire project, just like the Clone function, but there is a fundamental difference between them. If we do Clone, we will just create a local copy of the repository, so to say – cloned repository, and all synchronization will take place between the base repo and our local copy. You can read more about git clone operation, the Clone function and how to clone a repository here: Git clone vs backup.
Fork, on the other hand, differs in that it copies the entire repository, so to say, you create forked repositories, but on the server-side! And then this copy can be cloned and worked on it, completely separate and independent of the basic project. Powerful functionality. Wondering where the name Fork came from? The copies we create in this way can be visualized as a fork. Anyway, just look at the icon for this option in GitHub:

How does forking work
It doesn’t matter who, where, and how manages the base project, if it is possible to fork a repo, that fork is entirely yours. You don’t have to worry about permissions or accesses. You can treat such a fork as your own public repo in your namespace. So where is magic? With this feature, you can easily synchronize your work between two seemingly separate git repositories! Let us consider a small example:

original/niceRepo stands for the name of the repository in the given namespace. This is a representation of the public repository that we want to make some changes too, but not having any permissions to it. So we use the fork option and create a copy, this time in our namespace – myNamespace/niceRepo. We clone our own repository, make changes locally, push, and finally, we come to the point. At the moment, we can perform a Pull Request between our repository and the original one. If we do this, the project owner will receive a notification that someone wants to make changes, and then it depends on him or her whether our change will be accepted or not. It is important that such Pull Request allows for code review and discussion on the proposed changes, just like in the case of a typical PR. Now let’s briefly discuss how it works on different platforms.
Fork in GitLab

It is always worth looking at the official documentation, I encourage you to do so because in this case, GitLab describes the process very easily. In short, the whole operation is to find the project we are interested in, click the fork option (in the upper right corner, as in the picture above), then select our namespace in which we want to make a copy and it’s ready. Importantly, GitLab encourages us to use repository mirroring. I also recommend that you do this, this option will allow you to automatically sync changes from the original repo with our copy. Beware of the naming convention, because GitLab uses Merge Request, not Pull Request, as in GitHub.
How secure are your repos and metadata? Don’t push luck – secure your code with the first professional GitHub, Bitbucket, and GitLab backup.
Fork in GitHub
And since I mentioned GitHub, I will tell you immediately how it works in this service. The actual execution of fork works almost identically, so I won’t describe it. However, the main difference is that GitHub by default does not provide the option of automatic synchronization between our and the original repository. It is true that we have a button that allows us to do it manually, but it is a downside to the competing platform. On the other hand, it must be admitted that the GitHub documentation describes very clearly how we can deal with this and easily synchronize our local copy to be up to date with the original repo all the time.
Fork in Bitbucket
While the GitHub and GitLab web interfaces are quite similar to each other, Bitbucket differs significantly from them. Repository forking is no exception. While this option is still in the upper right corner, after opening the repository we are interested in, there is no well-known “fork” icon there. We need to open the drop-down menu and select the “Fork this repository” option there, as shown in the image below:
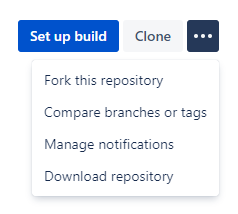
Bitbucket also allows us to check the “Private repository” option. Apart from the obvious consequences of this decision, there is also one less clear matter here. Namely, the fork in Bitbucket by default inherits permissions for users / groups and there may be a problem with the limit on our Bitbucket plan. Checking this option allows us to bypass this limitation.
Also, just like on GitHub, we have here a button available to sync changes between the original repo and our copy. The important thing is that the sync only happens between main branches, although we can also manually select a different branch, another feature branch.
Forking workflow
We already know what fork is, we also know how to create our own on three popular platforms. Now I will talk about how to properly work with its use and deliver changes to the original repository. In fact, I mentioned it at the beginning, but I didn’t say it’s a formalized process called Forking Workflow. We’ll talk about the different ways of working with Git another time, now just a few words in relation to today’s topic.
The main advantages of git fork workflow are two things – branched flow, where everyone works on their own copy, and above all the fact that only the project maintainer can push to the original repo, so any changes have to go through their hands. Why is this an advantage? Because it is a control mechanism. It is the creator of the original design that decides what will be in the codebase and what will not. No matter how beautiful and functional the code someone wants to include is, it is the maintainer who decides whether that code will be there.
Another advantage is that at some stage of the project, it can be split into two (or more) separate ones. For example, due to differences in development plans among maintainers, or because of the desire to create a commercial solution based on the existing one. Of course, there are still licensing issues here, but we will not deal with that now.
Forking Workflow is very similar to Git Workflow (which I will tell you about the other day), but instead of dedicated branches, we have a dedicated, separate repo that is a copy of the original. Let’s go back to the example and the picture from the beginning of the article:
- we have a public repository called original/niceRepo
- we make its fork called myNamespace/niceRepo
- this is entirely our copy of the original repo which we clone locally
- we introduce changes as in normal work with Git
- only when our changes are in the main branch of our fork, we do PR/MR to the original repo
- the maintainer decides whether our changes will be applied
Is the use of forks popular?
If you’ve reached this point, then you should know enough to be able to create your first fork. We still have a remaining question – what for? Well, it is a common practice in Open Source projects. If we want to co-develop such a project, this is how we have to do it. It’s not art for art’s sake at all, it’s a popular thing in the IT world.
Perhaps the most famous example here will be Red Hat Linux. The project was split into two branches, two forks – an Open Source project called Fedora, and a paid one – Red Hat Enterprise Linux. Both projects operate dynamically to this day, although almost 20 years have passed since this division.
Another famous example – Bootstrap, which currently has almost 74k forks. As you can see, the topic of Open Source projects is alive and present among developers. So, the mechanism of creating forks is important and still being developed on the side of popular hosting services, even though the Git engine itself does not have such an option.
If we start creating our own public repositories or creating forks, we must also remember about the appropriate backup. I recommend reading this article: Restore deleted repository. There is such a thing as git network, if we use the fork option, we should also know what the consequences are of removing a repo that belongs to such a network. Without this knowledge, we may be unpleasantly surprised and this is the last thing we want to meet without having a backup.



