


GitLab Backup to S3
Businesses increasingly rely on S3 object storage for GitLab backups. Firms leverage the flexibility of the 3-2-1, 3-2-1-0, or even 4-3-2 strategy (or others) and improve disaster recovery options. At the same time, S3s lower the risk of potential data loss, contributing to operational cost optimization.
GitLab’s own guidance recommends S3 storage (e.g., over NFS) for its performance and ease of integration.
Given the rapid growth of GitLab repositories – containing source code, CI/CD artifacts, and application data – S3 becomes a more logical and reliable choice. Its native features, such as cross-region replication (CRR) and object versioning, further bolster recovery options and ensure redundancy.
It’s worth remembering that cloud providers secure the underlying infrastructure, but the user
is responsible for securing and managing backups. That involves enforcing encryption (including two-factor authentication, database encryption key), versioning, and policies for restricted access rights. And it’s hard to find an exception.
Such an approach puts control over sensitive information directly in the hands of organizations. While this may sound challenging, it provides compliance and security strategies flexibility.
Besides, scalability is the new black nowadays. Eliminating file-system complexity and supporting highly available storage solutions make S3 a natural fit for enterprise-level GitLab backup requirements and obligations.
It’s even more critical as weekly full and daily incremental backups are a common practice to balance storage costs and backup efficiency.
The storage for your GitLab data backups
The number of S3-compatible storage providers has grown in recent years. Along with increasing demand for scalable and cost-effective tools of this type, the growth of cloud adaptation and security needs follow.
In addition to the major players listed below, niche cloud storage providers focus on specific business needs, such as data lakes or archival storage.
Nonetheless, among the best-known S3 services, we can consider 5 top solutions.
AWS S3
AWS S3 is a highly scalable and secure object storage service by default. It integrates seamlessly with GitLab for backup and archival purposes. The storage offers lifecycle management, versioning, and cross-region replication for disaster recovery. Every Git user finds it easy to operate on.
Azure Blob Storage
Azure Blob is ideal for GitLab users who are already working in the Microsoft ecosystem. It provides scalable storage and swift integration into Azure services. The Blob’s strong points are immutable storage for compliance and automated tiering for cost optimization.
Google Cloud Storage
With solid analytics and AI integrations, Google Cloud Storage is great for high-performance GitLab backups. It supports automatic storage class transitions and multi-region redundancy for enhanced reliability. It’s worth noting that GCS is not an S3 solution in a sense but has very similar capabilities.
Wasabi
Wasabi is a cost-effective S3-compatible storage option that offers predictable pricing with no egress or API fees. It’s a strong choice for GitLab users needing affordable long-term storage with high durability.
Backblaze B2
B2 is known for its simplicity and low cost. That’s a S3-compatible storage with no egress fees. It’s well-suited for GitLab users needing inexpensive, reliable backup solutions with easy cloud service.
After determining where and how you plan to utilize the S3 object storage capabilities, you must choose the right S3 provider for your GitLab-specific information.
A quick overview of GitLab backup to S3
In GitLab, the running backup process is based on the sudo gitlab-backup create command (the central part of the backup script).
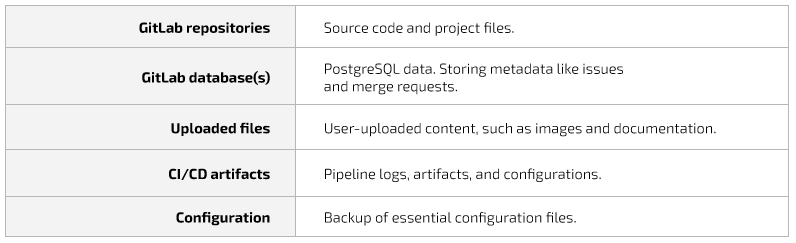
As a reminder, let us mention that it includes the following components:

These are crucial for GitLab instance backup, enabling easy restoration from the backup directory.
Backup archive in S3
At a GitLab level, to configure (reconfigure) S3 requires accessing and editing the configuration file:
/etc/gitlab/gitlab.rb
The configuration may look like the following:
gitlab_rails ['backup_upload_connection'] = {
"provider" => "AWS",
"region" => "your-region", # e.g., "us-west-1"
"aws_access_key_id" => "your-access-key-id",
"aws_secret_access_key" => "your-secret-access-key"
}
gitlab_rails['backup_upload_remote_directory'] = 'your-s3-bucket-name'Thinking about an upload, you can choose a slightly different approach. Here is an example script:
gitlab_rails['backup_upload_enabled'] = true
gitlab_rails['backup_upload_connection'] = {
"provider" => "AWS", "aws_access_key_id" => "YOUR_ACCESS_KEY",
"aws_secret_access_key" => "YOUR_SECRET_KEY",
"region" => "YOUR_REGION"
}
gitlab_rails['backup_upload_remote_directory'] = 'your-backup-bucket'After each backup, you should check your S3 bucket to confirm that you uploaded the backup successfully.
You can also configure the backup path and retention by setting the policy:
gitlab_rails['backup_path'] = "/var/opt/gitlab/backups"
# Local directory to store backups before upload
gitlab_rails['backup_keep_time'] = 604800 # Time in seconds (1 week)Then, you use a simple command to create a backup:
sudo gitlab-backup createOf course, there is an option to automate backup with cron jobs. For example, to back up GitLab at 5 AM daily and upload it to S3, use the following line:
0 5 * /opt/gitlab/bin/gitlab-backup create CRON=1Restoring GitLab backups from S3
You need three default steps to bring back your GitLab backup stored in S3 storage.
- Go to your S3 bucket, select the required tar file (*.tar), and download it for your GitLab server.
- Restore the backup.
- Ensure you halted/stopped GitLab to avoid conflicts (no error message):
sudo gitlab-ctl stop- Move the downloaded backup file (*.tar) to the GitLab backup directory:
sudo mv backup.tar /var/opt/gitlab/backups/- Now, use the backup restore command:
sudo gitlab-backup restore BACKUP=timestampIn this case, replace the timestamp attribute with the timestamp of your backup tar file (otherwise, an error will occur).
- Restart your GitLab:
sudo gitlab-ctl startIf the restore command aborts, check for a GitLab version mismatch or an error message related to possible missing dependencies. You may also need to verify that the backup tar file is not corrupted.
In addition, ensure the backup’s installed version matches the version of GitLab running on your GitLab server.
When using S3 storage, it is a good practice to verify that the IAM role and IAM profile permissions are correctly set.
Schedule regular backups using cron job(s) to keep all the information consistent.
Files synchronization for GitLab data
Users often try to check their backup and conduct the integrity check using the rsync command. However, you should remember that S3 does not support this command directly in the traditional way (local disks or NFS servers).
Moreover, using the command to migrate Git repositories may result in information loss or repository corruption.
If you plan to synchronize the local data with S3 resources, you can do it via AWS CLI with the sync command:
aws s3 sync /local_directory/ s3://bucket_name/directory/As an alternative and in the same way, utilize rclone and s3cmd commands. Both work similarly to rsync:
s3cmd sync /local_directory/ s3://bucket_name/directory/
rclone sync /local_directory/ s3://bucket_name/directory/A more convenient and time-savvy backup approach
To increase safety and convenience, you can use GitProtect to manage the whole process faster. It’s a far more convenient, error-free approach with security measures ready for every scenario.
GitProtect
GitProtect is the world’s only disaster recovery tool for DevOps environments. Utilizing its features effectively supports continuous operations and helps to prevent information and productivity loss.
The latter applies to accidental issues and commit deletions. To resolve such problems, you can restore data granularly at any time.
In addition, you can migrate data between vendor accounts or deployments (C2C, C2P, etc.) with little effort.
With GitProtect, you can perform all the above commands and instructions for backing up (backup script) and restoring repos by clicking all the steps through a convenient GUI. In the meantime, you are free to dive into all the details you need.
All DevOps stack backup automation
- set up your backup strategy, using 3-2-1, 3-2-1-1-0, 4-3-2, or other rules
- schedule (even every 10 mins)
- use AES 256-bit encryption and the customer’s own key
- utilize up to unlimited retention (others offer up to 365 days)
- rely on robust security options:
- Data Residency of Choice
- SSO and SAML integration
- role-based Access Control
- broad Ransomware Protection setup
Store and connect any storage
Depending on your needs, you can use:
- the already-included and unlimited cloud storage (S3)
- your own cloud/on-prem storage (e.g., AWS S3, Azure, and more).
Instant Remediation Center
You are provided with:
- backup assurance and notifications
- audit-ready SLA reporting and visual stats for immediate remediation and data availability.
The tool allows you to backup and restore all chosen information – repositories and metadata (e.g., from GitLab database: issues and merge requests) – via a single management console. It was designed to connect with any storage, providing a fast and convenient GUI interface.
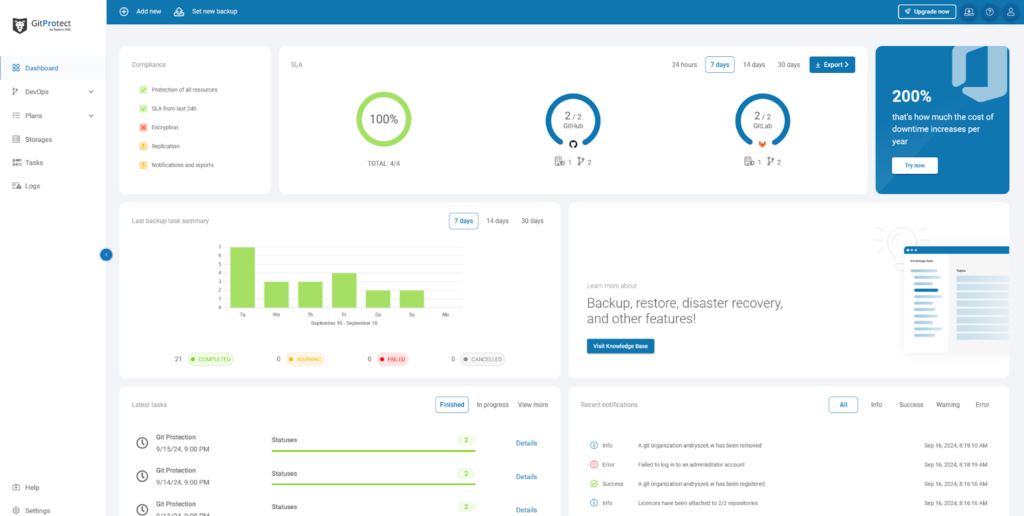
Let’s demonstrate by moving the local GitLab backup directory to the AWS S3 buckets. As mentioned, the Amazon S3 solution offers easy integration with GitLab for backup and archival purposes.
GitLab information in the AWS S3 buckets
A great and practical example is moving GitLab backups to the AWS S3 buckets, e.g., from local storage, another cloud provider, or even network-attached NAS/SAN storage.
After assigning your GitLab instance to the tool, you can add an AWS S3 target storage. To do so, expand the Storage type list and select AWS storage.
Now it’s time to fill out the Access Key and assign a received secret access key using Password Manager.
Next, choose the Region where your buckets are created and enter the unique Bucket name. The latter describes the unique name of the container in which you’ll store your repositories.
Before saving the configuration, select the Browsing machine with storage allowance (for example, a device with an Internet connection). Use the Change button to choose one of the devices assigned to GitProtect that will connect the storage to the system.
Click the Save button once everything is configured.
Bucket and IAM user permissions (upload user access)
Of course, each Amazon AWS S3 bucket must have at least minimal permissions to be used as backup storage in the GitProtect service.
Such a container, designated for storing data, requires the following policy assigned in JSON format:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal":
{"AWS": "arn:aws:iam::{account}:user/backup-user"
},
"Action"[
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::bucket-name",
"arn:aws:s3:::bucket-name/*"
]
}
]
}When creating a new instance, you can use the Immutable Storage configuration to protect your information against accidental (or malicious) deletion or modification.
For that, additional permissions are necessary:
- s3:GetBucketObjectLockConfiguration – needed to read Object Lock
- configuration.s3:GetBucketVersioning – used to read the versioning configuration.
Both permissions should find their place in the Action section, which needs to look like in the example below:
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:GetBucketVersioning",
"s3:GetBucketObjectLockConfiguration"
],GitLab backup files replication in GitProtect
Replication is a capability that further distinguishes GitProtect. It allows you to create multiple copies of your backups stored in different locations – cloud providers (like AWS S3, Azure Blob, etc.) or on-premises storage.
That significantly increases your business’s data availability and disaster recovery potential.
Replication enhances data durability and fault tolerance. Even if one storage location fails, your backup copy is accessible elsewhere.
To put it briefly, utilizing the replication feature minimizes the risk of information loss by implementing the 3+2+1 or 3-2-1-1-0 rule, thus enhancing business continuity.

To create a replication plan, you just set the storage and configure a simple scheduler. Creating a replication plan involves at least two storages:
Source storage
It contains data for the replication process.
Target storage
It’s a space (place) where you plan to replicate the data.
The target storage must be empty to be available in the replication window. If some data exists on the storage (which you want to use as a target storage), it will be unavailable in the Target storage list.
When planning a replication strategy, consider storage location, schedule, frequency, and available resources. Schedule replication during periods without active backups and ensure adequate resources, as replication copies more information than a regular backup.
The replication frequency depends on your backup process frequency, but performing it at least once a week is recommended if backups are frequent.
Specific data for conclusion
S3-compatible storage efficiently supports GitLab backups due to its default flexibility, disaster recovery capabilities, and cost-effectiveness.
With the rapid growth of repositories containing source code, CI/CD artifacts, and critical information, S3 ensures high availability and redundancy. Key features, like cross-region replication and object versioning, provide additional protection against data loss.
While cloud providers secure the underlying infrastructure, it’s up to users to manage their backups, including encryption, versioning, or entry control. That gives organizations more control over compliance and security strategies.
S3 is a highly secure and industry-recommended solution for storing data, offering robust protection features such as encryption, access control, and compliance capabilities. However, when backing up GitLab environments to S3, it’s vital to consider third-party backup tools like GitProtect.
GitLab recommends using external S3 backup solutions, as they do not natively handle them. GitLab has explicitly pointed to GitProtect as a reliable standalone solution.
That emphasizes the need to ensure comprehensive data protection and ease of recovery when using S3 for GitLab information copies. Practical options for disaster recovery and scalability are a few examples of what uploading backups can create. Managing GitLab backup in S3 with GitProtect increases the process’s security, convenience, and replication options – unique on the market-related metadata.
[FREE TRIAL] Ensure compliant GitLab backup and recovery with a 14-day trial🚀
[CUSTOM DEMO] Let’s talk about how backup & DR software for GitLab can help you mitigate the risks



