


How to Prevent Backup-related Throttling Without Losing Data (or Mind)
Consider that your backup is running smoothly. Your dashboards are green. The DevOps team is sleeping peacefully. And yet, behind the calm surface, something is happening. Your API limits are being chewed up, call by call, until you’re throttled into silence. Suddenly, your system stalls – quietly and invisibly. The irony is, you build a backup system for resilience. Now, it’s the vulnerability.
There’s a quiet assumption built into most backup systems. It’ll resolve itself if you just throw enough bandwidth, retries, and threads at the problem. However, in DevOps, it’s naive. Dangerous.
Throttling in DevOps is not just a glitch
Why is it dangerous? When every DevOps tool communicates through rate-limited APIs, such as GitHub, GitLab, Bitbucket, or Azure DevOps, there is no alternative.
SaaS vendors aren’t being punitive when they impose API limits. They protect their infrastructure, maintain availability, and shield users from abuse. The problem arises when a backup solution interacts with the mentioned systems as if it owns the place. All the more so when a backup system is “unaware” of API hygiene.
So, a backup running that blindly pulls:
- metadata
- repositories
- pull requests
- webhooks
- smconfigurations
- comments.

This is done without pacing itself. The result? From the API perspective, such a situation becomes indistinguishable from a denial-of-service attack.
Once throttling begins, the dominoes fall fast:
- backup jobs stall
- critical configurations aren’t captured
- version histories become fragmented.
Then the false assumption that everything is safe and restorable shatters.
You may not notice it immediately. The log will appear deceptively normal, with a few skipped objects or a slight delay here and there. And yet, the cost reveals a problem over time.
Then, you try to reverse-engineer the cause of the failure. It turns out that a silent, unreported throttling event sabotaged the entire chain. From a business perspective, it’s not a bug but an existential risk.
The whole thing is not about technical debt. It can lead to reputational damage, especially when a disaster recovery test fails to function properly. There’s also an operational cost when the dev team has to manually reconfigure environments. Additionally, audit exposure reveals that your backup missed a repository containing your compliance script.
How innovative systems avoid the trap
Effective throttling prevention is an architectural approach rather than a reactive one. It begins with backup engines deeply integrated with API rate limits, rather than just being aware of them. The big picture is that such systems don’t brute-force their way into SaaS platforms. They converse, interpret headers, as well as observe quotas. Moreover, they anticipate consequences.
This manifests, among other things, through dynamic pacing. A well-designed system reads the room. It doesn’t assume the same call rate will work at 2 a.m. and 10 a.m. The solution monitors the API’s responses, notes the Retry-After headers, and adapts its behavior without human intervention.
If it notices pressure, it backs off. When a specific endpoint is rate-limited, the flow is redirected to other tasks that can be performed in parallel without exceeding quotas.
Some systems, such as GitProtect, take this further and utilize well-designed job orchestration. Backup threads are distributed based on understanding the API’s cost per object type, rather than relying on a simplistic “repository-per-thread” logic.
A repo with massive commit histories (or one linked to CI workflows) is treated differently from a dormant wiki. Such an approach reduces unnecessary API pressure and ensures that backups don’t trip over themselves even at scale.
Incremental logic also plays a crucial role. Well-developed systems track state, not full sweeps that trigger abuse mechanisms. It’s about monitoring commit deltas, webhook triggers, and change stamps. Such an approach reduces API usage and dramatically shortens backup windows. That creates a more sustainable rhythm harmonizing with the platform’s operational limits.
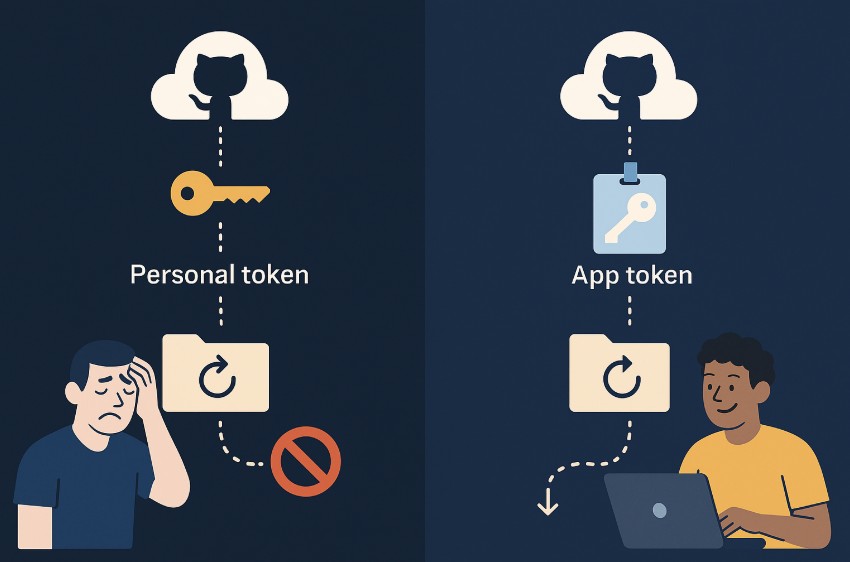
Authentication method and credential distribution
One thing is barely mentioned, yet it screws up more backup ventures than experts are willing to admit. It’s the way API authentication works. Next to bandwidth, schedule, or even volume, another factor may be the damn token.
If your system utilizes a personal access token or OAuth to communicate with GitHub’s API, you might already be on thin ice. The reason is that you tied your entire backup workload to the (human) user’s rate limit. That means one well-timed backup sweep, and you’ve burned through their quota.
At the same time, the developer can’t push code or trigger a CI run. He probably can’t even click around in the interface – without getting rate-limited.
You can also use the Github App method. And that’s a completely different story, as it:
- is scoped to the organization
- has broader limits
- doesn’t hijack anyone’s personal quota.
It resembles running backups from the service entrance, not the front door. That means you’re not clogging up the hallway. Such an approach makes a difference at scale. While backing up dozens or hundreds of repos, the traffic quickly adds up. When all of that goes through a single credential – even a big one – it’s a gamble.
Unless your system “knows” how to:
- split the load
- distribute jobs across multiple credentials
- route around the throttle points.
The above may seem like a hack, but it’s a strategy. Why? Because the trick here is not about staying under the limit. The goal is to avoid sabotaging your devs. Instead of creating a burden with backups, they should be tools available when needed—without the API misbehaving.
What does throttling prevention mean for business continuity
A system noticing API limits doesn’t just avoid getting blocked. It ensures continuity and successful test restores. This way, you can bounce back in the event of:
In more strict terms, that means:
- faster Mean Time To Recover (MTTR)
- fewer gaps in data lineage
- peace of mind when facing auditors.
The above means you don’t have to inform your DevOps team that they’ve lost a week’s worth of pull requests because the backup system was shut down mid-process.
The overall effect? The operational gains compound. By avoiding overloading systems, infrastructure costs drop. At the same time, developer frustration decreases as data restoration progresses. From a security perspective, you reduce the attack surface. Why? Because your backup engine isn’t constantly knocking on the API’s door like a spam bot.
A final thought
If your current backup solution allows you to define “resilience” as merely retrying failed calls until the quota resets, then it’s not resilience. It’s just a sign of recklessness. Worse, you’re operating on borrowed time if you treat GitHub, GitLab, or Azure DevOps like a dump truck instead of a carefully rationed endpoint.
The third “if” relates to your disaster recovery plan, which hinges on restoring from a system. According to this plan, the team has problems defining and thus noticing throttling. Calling it a plan is gambling without knowing its basic rules.
Teams must also acknowledge that backup isn’t about volume, but control supported with precision. This way, you can respect the limits imposed by the systems you protect. The banal conclusion is that when your backup and disaster recovery solution doesn’t demonstrate those qualities, the question is not whether you’ll fail. It’s when.



