

How to Undo a Commit in Git
Nowadays a lot of people type “git undo commit” in a search engine. Thus, I want to show you how you can undo changes in your repositories, and which git commands you need to use in your command line!
Depending on the situation, undoing a commit can either preserve or rewrite history. We must therefore consider whether the change exists only locally or has already been pushed to a shared repository, as rewriting public history can be risky. Before modifying the git log or creating new corrective commits, it’s important to understand which operations are safe in a given scenario.
Ways to roll back changes
As you know Git is a version control system. Thus, let me briefly point out how Git works. First, I should note that when we work with the repository, we have 4 levels:
- working directory – all changes tracked and untracked by git
- staging (index) – changes ready to be committed
- local repository – all unsynchronized local commits
- remote repository – external synchronization point
Those layers are important because rollback operations can work contrastingly for different levels. Another important thing, before we move on with our further consideration, is the fact that Git has a DAG (Directed Acyclic Graph) history. We can branch the work. Each git commit has its own unique SHA commit hash. Thus, manipulating commit history that has already been pushed to a shared repository can cause us trouble.
Git reset
Let’s consider the first case. The last commit in the remote repository is A. We grab this code and start working. We’ve created a new feature, made our own commit B, but it’s still only local, we haven’t done a push yet. Our linear story goes something like this: A — B. It turns out, however, that this feature is redundant (or wrong) and we don’t want to have it. We can easily edit and remove this last commit with the git reset command operation. We also have to choose the flag (soft, mixed, hard), which determines whether the changes will be saved in our working directory or not. Done!
Though, you need to know that such an operation can lead to data loss when using certain reset modes. Above, in the following example, we have considered the case where the latest commit B was only on our local repository. In such a situation there is no problem and we can safely perform this operation.
But what if we wanted to reset a git commit that already exists in the remote shared repository? Well, this is where it gets a little wild. Git will allow us to do that, why not, but we should avoid such an operation ourselves. This is important because when we ‘break’ such a sequence and the git log is not consistent, the push will be rejected unless we explicitly force it. We’ll get an error when trying to push because Git blocks non-fast-forward pushes by default.
How to undo a commit in git
There may come a time when you will need to undo something – for instance, undo local commit, restore files to a previous state, or undo changes in git. There are a few basic tools (and rules too), but keep in mind that some of these operations can not be undone later. To be more specific, we are getting into a dangerous area where you may end up with some lost data and work, so… be careful. Now, let’s go back to the main topic and find the answer to how to undo changes in git.
Visual learner? Then, don’t read but watch our GitProtect Academy video to find out how to undo a commit in git (Psst, don’t forget to subscribe!)
Git revert commit
So how can we undo changes that already exist outside? Fortunately, there is a safe solution – the git revert command operation. With it, we can undo changes from a specific commit. We don’t have to check who changed what and where in a git log command or look for a commit message, we just tell Git that the particular commit is to be rolled back. From a code perspective, we are doing something that resembles an ordinary UNDO. There was a change – there is no change. We got rid of the unwanted code. However, from Git’s perspective, it looks a bit different.
This command creates a new commit that reverses the changes, without modifying or removing existing commits, which makes it safe to use in shared repositories.
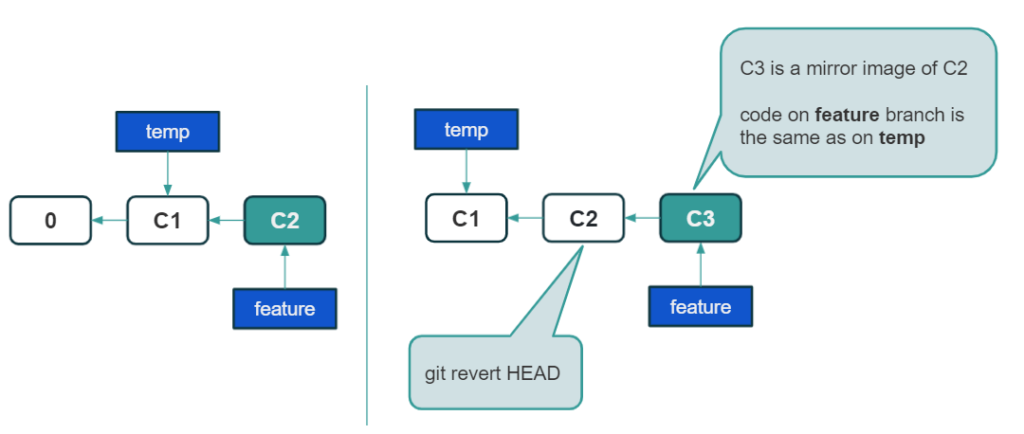
How to revert commit in git
I have accidentally pushed critical data
We already know several ways to roll back changes, each has its own advantages and disadvantages. But these were only theoretical examples to learn any git command. Let us now consider a more difficult case. Suppose I had a password or other very important piece of information saved in the plaintext in the notes.txt file. I accidentally added this file to my current commit and I did a push. What’s next, any other subsequent commits? A quick git reset would require rewriting shared history (force-push), which is risky in a team setting. Git revert can remove the secret from the current code, but it will still remain in the repository history.
Well, it will not be visible in the current version of code, in the current HEAD, but it will be stored in the repository history. This is very dangerous because it gives the illusion that the password is no longer available in the git repository. Well .. there is. In my article about ransomware attacks on GitHub, Bitbucket, and GitLab I am describing a case that proves that such things happen in the real world:
“In 2018, an experiment was conducted to search Github for withdrawn commits that contained the words “removed password” in the message. Result? 350k!”
Resetting a public commit
So how can we deal with it? It is not that simple, especially when many people use our git repository at the same time. This can be a big problem for our company. Because not only do we risk losing important data, but also repairing such a problem may stop work on a given project for some time. Why? Let me explain what steps would be taken in such a situation.
We will be using the git reset operation, but before that, we need to pause syncing with the external repository for a while. Team members must temporarily stop pulling and pushing, and open pull requests should be closed or paused.
How secure are your repos and metadata? Don’t push luck – secure your code with the first professional GitHub, GitLab, Bitbucket, and Jira backup.
The person to fix the situation should ideally do a clean clone of the project (remember to download the tags). What’s next? Well, now we’re doing a git reset, something we already know and understand that it spoils our commit history. But don’t worry, in this case, we’re doing it on purpose, and we’re about to figure out how to get out of it. This is easy enough because we just reset with the –hard flag (i.e. discard local changes and reset the working tree to the selected commit). When we are sure that the unwanted change is gone, then we push, but necessarily with the –force flag, which overwrites the state of the remote branch. This allows us to push even if we changed the git log. Be careful! This is a very risky operation, and the use of the –force flag is often restricted by branch protection rules for security reasons.
Okay, we’ve cleaned up the situation on the main branch, but we still need to resolve the problem. What if someone had already downloaded these changes locally before we fixed them? Ideally, each developer should delete local copies and make a clean clone. But this is quite problematic. In this case, developers must resynchronize their local branches with the corrected remote branch and re-apply any local work if needed, resolving conflicts along the way.
Branch removal
There is also another way to solve the aforementioned problem. We can make a local copy of the current branch with the unwanted code and then remove the working branch completely from the external repository. On our copy, we reset as above, but we don’t need to use the –force flag, because the original branch was removed from the remote repository, and is recreated under the same name with corrected content.
In both situations, there is one more thing that we must remember. Very important from a security perspective. If someone somehow knows the commit hash of our unwanted, deleted git commit, they may still be able to access it and recover the data for some time. The removed previous commit will become the so-called orphaned git commit, not linked to any branch, but will still exist. It would be worthwhile to manually use the GIT’s GC mechanism here, but we’ll talk about it another time.
Moreover, Git provides a command called restore that can recover deleted files as long as the data still exists in the repository history.
Backup
Another, and it seems to be the safest, way is to use a backup of the repository from before the unfortunate git commit. Although also that might require some work. If we even have such a backup at all. The risk here is losing changes made after the backup was taken. However, we can patch them and then apply them to the version recovered from the backup. If we have a properly configured backup process, then deleting the repository and performing a quick recovery from a backup seems to be the safest and fastest solution. It does not require us to manually type git reset commands to get specific changes.
The conclusion that we can draw from all the considerations mentioned above is to make a backup as often as possible because you never know when it may be needed. And when you will need it, be sure it will, only then we can realize how much it costs us to lack it.



