Merge vs. Rebase – Ways to Combine Changes in Git
Version control systems can be effectively used for one-man projects, but the vast majority are used to support teamwork. It doesn’t matter if it’s 5 or 500 people, the idea remains the same. And that’s a huge advantage of Git. It has gained popularity, among other things, due to the fact that the branched process of introducing changes to the repository is very easy and fast. Of course, in theory, because the human factor can complicate even the simplest solutions.
Code merging problems
As I mentioned, Git supports branched processes, and this is one of its main features. But how does it work? At any time, we can create a separate branch, that is a pointer to the commit. From that moment on, our work becomes split and we can develop two different versions of our project in parallel. This is something great, it gives us a lot of possibilities, we can create separate branches for separate features, bug fixes, release versions, and so on. Even each team member can create their own separate branch to practice and test something, or to introduce a new person to the project. Just use it as you want. But at some point, a problem arises – how to merge these two parallel versions of the project together? What to do with changes that affect the same parts of files but are resolved differently? Well, Git gives us two tools to help us put our separate branches together: which is MERGE and REBASE.
How secure are your repos and metadata? Don’t push luck – secure your code with the first professional GitHub, Bitbucket, and GitLab backup.
Before we discover both, it’s worth mentioning that no matter which method we choose, there is always the risk of overwriting or losing certain changes during the process. Can Git recover file? Yes and it is worth being prepared for such a situation to avoid possible problems. You can find more information about this subject in my previous article can Git restore file.
It may also turn out that, for example, when merging changes, we have made our local repository a huge mess and it’s hard to dig out of it. Then Git can quite easily restore branch to origin by removing the “garbage” and force-fetching the external version to try to merge our code again. It is a waste of time so we will learn to use these tools correctly.
Merge
Let’s imagine a very simple scenario: our last commit is A, this is where the project is split to branch1 and branch2, on each of them commits B1 and B2 are created, respectively. Then our repository looks like below:
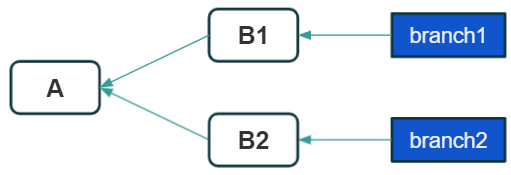
Merge function allows us to merge changes from one branch to another. In our case, we want to include branch2 to branch1. Being on the target branch, which is branch1, we need to execute the command like this: git merge branch2
What will happen after its execution? Git will create the so-called merge commit, an additional commit that will merge changes from both branches. After this operation, we can see our repository as something like this:
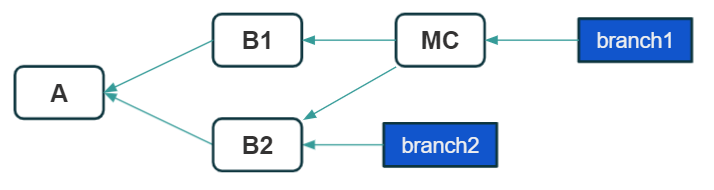
Notice that branch1, which now has the merged changes, also has an additional merge commit, marked as MC. Branch2, on the other hand, has not changed at all, the operation only applies to the branch to which we include the changes.
What are the merge benefits?
Merge is a fairly simple operation, we are not interested in the exact content of each commit on a given branch, but the sum of changes and differences between branches. Whenever this operation is performed, the so-called merge conflict may appear, but this is relatively rare. Don’t get me wrong, it is quite common in daily work, however I used the word “rare” as most merge operations succeed without conflict. However, as with anything, it does come with some risks.
First, as we discussed in the previous paragraph, any careless merging of changes can lead to the loss of some changes from merged branches. Common human error when resolving merge conflicts. On the other hand, another downside of the merge itself is the fact that the aforementioned merge commit is created. This is an additional commit, which in itself does not bring anything new to our project. Why am I taking this as a disadvantage? Because it extends our history excessively. A branching still exists in history, only from the moment of the merge operation we have connected yet still existing branches. Besides, after a long time we have thousands of such merge commits in the project. This makes the history of changes significantly difficult to read.
Rebase
On the one hand, rebase does the same thing as merge – that is, to merge changes from separate branches. However, the principle of operation is completely different and more complicated. Let me start with the benefits: rebase doesn’t create a new merge commit. Paradoxically, from the perspective of the history tree, it does not even merge branches with each other. Rebase collects commits from one branch and then “paste” them one by one into the other branch, resulting in a nice, flat, linear story. Readability is its main asset. A flat history allows us to easily find commits that contain errors or just read through and understand the project.
But as always we have pros and cons. Rebase has a major disadvantage that results directly from the principle of its operation. The process of pasting commits at the end of the branch where we are applying our changes has two problems:
- the commit being attached to is a completely new commit (from the Git perspective), which can damage the history if we operate on public commits
- we attach the commit after the commit, which can cause a huge number of conflicts that are not actually there and merge operation would not detect them
Without going into details, let’s test a simple scenario. Let’s go back to the starting point from the beginning of this article, before performing the merge operation. We have separate branches: branch1 and branch2 and corresponding commits B1 and B2. Now let’s try do this on branch1: git rebase branch2
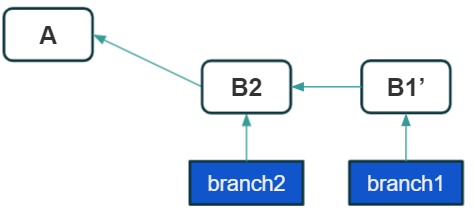
That’s the result. We re-based branch1. We pointed branch2 as a new base, and then joined the commits from branch1 at the end of this new base. Note that we don’t have commit B1 anymore, instead we have B1′. It’s an exact copy of B1, with the same changes and same metadata, but it’s technically a new commit and has a different SHA code than B1.
Differences and consequences
As you can see, both merge and rebase will eventually cause that changes from both branches being combined to a particular branch. One creates an additional merge commit, the other modifies the history to make it flat and transparent. Rebase usually causes more conflicts than merge. Besides, it is more difficult to use and this is probably the reason why programmers use merge more often. Either way, it’s worth weighing up the pros and cons.
Risks
As I mentioned at the beginning of this article, being able to branch out easily is something brilliant but risky at the same time. Git provides the tool, but people use it and may consciously or unconsciously make a mistake that could cost us a lot. If we do a “wrong” rebase/merge locally and push it, we may lose the changes and not even know it. We must always remember to regularly backup our repositories. It will save us a lot of work, nerves, and costs. You can treat Git as a backup, but as I described above, sometimes Git cannot restore a file and even a basic Git operation, if misused, can take a heavy loss.