Git Workflows
Git is the most popular version control system nowadays, and it’s a known fact. Probably as many as 90% of programmers use it. However, it is not only used commercially. Many novice programmers also use Git right now, and many courses and tutorials incorporate the basics of Git into their initial lessons. Before we go any further, however, I would like to ask perversely – what exactly is Git?
The definition in Wikipedia looks like this:
Git is software for tracking changes in any set of files, usually used for coordinating work among programmers collaboratively developing source code during software development.
When I explain to someone with my own words, I often use the term engine or just tool. Because it is a tool, and extremely powerful, and we can use it in many ways. As with a hammer, we can hammer nails with it (in several ways, even with a handle!), but we can also use it to punch a hole in the wall or stir the soup in a pot. In order to take full advantage of the tool’s capabilities, we need to know it well and know what it is really for and how to use it best. It’s exactly the same with Git.
What’s Git workflow?
The way Git works gives us a lot of freedom and flexibility to use it. There is no imposed working method here, it depends entirely on us and our knowledge of technology. Contrary to appearances, this is an advantage, not a disadvantage! On the other hand, we need to handle it somehow. If each developer used Git in their own way in a project with 100 people, it would be quite a mess. Therefore, over time, certain work standards appeared, the so-called workflows. They describe what and in what order we should do so that the teamwork with our version control system goes smoothly and, above all, coherently and easy to scale.
Git workflows: Centralized workflow
The easiest and, in my opinion, the worst is Centralized Workflow. Why then do I even mention it? Well, you have to look a little bit into the past. Once the most popular version control system was SVN, and some projects still use it today. Well, Centralized Workflow works on a very similar principle. We have one central repository here which serves as a single sync point. The main branch – called main – replaces here used in SVN – trunk. All changes are committed just to it, and no other branches are used.
I consider this workflow the worst because it does not use the potential that Git gives us. In addition, the use of only one branch causes more frequent conflicts, no division into production and development code, and difficult coordination with more programmers in the project. However, there is an advantage. When migrating from SVN to Git, the use of this workflow allows our employees to work in exactly the same way as before. On the other hand, I would personally recommend training your team and switching to Gitflow right away, but I can understand that not everyone can afford it, so Centralized workflow can be an alternative. It would be good if this was only a temporary alternative.
In order for everything to work properly and the commits history to be linear, there is an important thing to do before we push our changes out. First, we should perform a fetch, and then rebase – here I refer you to the article about merge vs rebase. Not pull and not merge. Why so? The point is for our own commits to be “at the end” of the story, so we need to rebase. Thanks to this, we have a linear history, our changes are the last and we can calmly and without conflict (theoretically) make a push. As you might have guessed, it’s not always that easy, but I’ve already mentioned it – this workflow can cause conflicts and we need to be aware of that.
How secure are your repos and metadata? Don’t push luck – secure your code with the first professional GitHub, Bitbucket, and GitLab backup.
Git workflows: Feature Branch Workflow
A natural development of Centralized Workflow is the so-called Feature Branch Workflow. It allows us to use the capabilities of Git to a much greater extent, primarily using – as the name suggests – feature branches. This approach gives many benefits, but the most important of them is the fact that finally, the main branch is a place for “ready” code that is tested and proven – one that should not contain bugs.
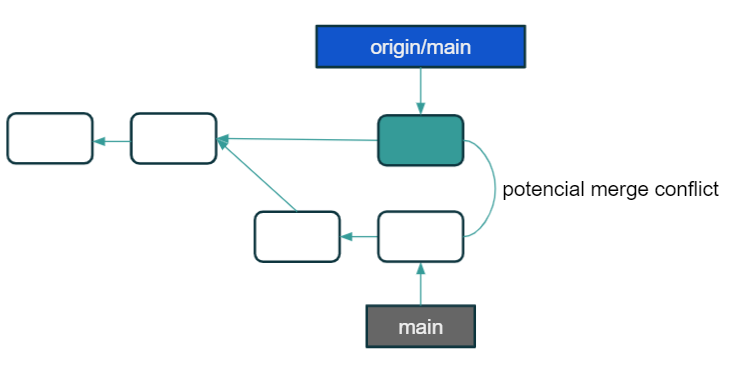
In this standard, each feature has a separate, dedicated branch. Thanks to this, it is easier to work on a given code fragment, the changes do not interfere with the main branch, and above all, it gives us the opportunity to create Pull Requests. It may seem trivial, but Pull Requests are the greatest advantage of this approach. The possibility to discuss, even during development, to verify changes, correct bugs, and code quality before including changes to the main branch – these are huge advantages and in the long term our code will be of much better quality than if we did not use PR. And what does working in this standard look like? Let’s look at the figure below:
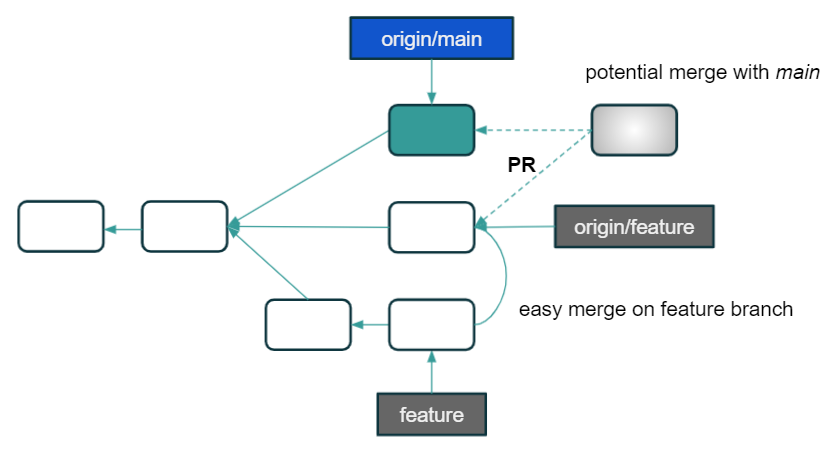
There is a lot going on in this picture, but let me explain. We see 3 branches here:
- origin/main – this is a remote main branch
- origin/feature – this is a remote feature-branch we are currently working on
- feature – it’s a local feature-branch that syncs with origin/feature
Thanks to this configuration, we can easily push or pull the code related to a specific feature. Regardless of how many people work on a task, all code on this branch is related only to it. When we want to synchronize these changes with the main branch, then we create the previously mentioned Pull Request (or Merge Request, depending on the platform), marked as PR in the picture. Importantly, in this model, we can use both rebase and merge to combine changes. A number of the so-called merge-commits will not be as large as in the case of using merge in the Centralized Workflow.
This way of working focuses on business value, i.e. specific features. Dedicated branches are created for them and those values decide about the workflow in the project.
Git workflows: Gitflow
Another workflow – the current standard – is Gitflow. Someone might point out that it is not much different from Feature Branch Workflow, after all, it also relies on dedicated feature-branches. However, there is a fundamental and enormous difference between them. Well, Gitflow introduces more “special” branches and gives them individual roles, making it a great help in implementing the Continuous Delivery or Continuous Integration process.
First things first. What is it exactly about? First of all, we have two basics branches here:
- main (once called master) – here is the so-called production code, usually the version from this branch is installed and available to the client
- develop – main development branch serves as an integration of all feature-branches
But that’s not all of course, it’s just the beginning. As in the previous workflow, here each feature also has its own dedicated branch, which is later integrated not with the main, but with the develop branch. Another novelty appears further. Gitflow introduces the so-called release-branches, which is a separate place for code prepared for deployment. From this point on, the release is detached from the develop branch. We can fix bugs, but all new features go to develop and the release knows nothing about them.
Speaking of bug fixes, Gitflow is prepared for that too. Introduces the concept of hotfix. What is it about? This branch is created directly from main and is also linked directly to it. So we’re omitting all the other branches here, including even develop. Of course, after such an operation, changes from hotfix-branch should go to develop, so as not to spoil the history of the repository. We promote these changes “down”, so that not only the main knows about them, but also every other branch we are currently working on. Let’s sum it all up by looking at the picture below:
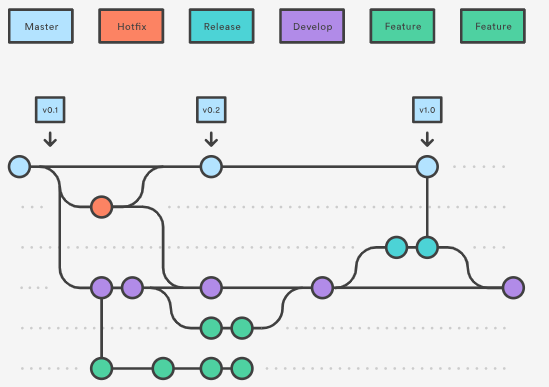
At first glance, this may seem complicated, but after a quick familiarization, it turns out to be quite easy to understand and use. It is simply a standard that we must keep and apply as intended. As I mentioned, such flow is helpful in DevOps work and the use of CI/CD. Moreover, we can easily apply another Git tool called tagging here and tag the correct versions. Thanks to this, we will have easy access to every version of our software that has ever been created in the project.
It is also worth mentioning here the support that facilitates working with Gitflow. Git has the git flow init command, thanks to which we can initiate the flow in our repo and execute specific instructions faster. Sample commands:
- git flow feature start my_feature
- git flow feature finish my_feature
- git flow hotfix start login_hotfix
As you can see, these commands are so self-describing that we should be able to easily teach our team to use this standard – for the benefit of all.
Forking workflow
Finally, I would like to mention something called the Forking workflow. In short, it consists in copying the project, by making its fork. These copies are practically independent, we can split our project into a separate fork at any time. However, there is an important benefit from this – we can perform Pull Requests between such repositories! This opens up a lot of opportunities for us, most often used in the case of open-source projects. If you are interested in the details of this flow, I refer you to this article: Git forking workflow.
Briefly summarizing, as you can see from the reading above, Git is a powerful tool, flexible and not imposing any specific way of working. There are several proven and used ways of working, but it is up to us which one we use. And how effective. Good team preparation, appropriate training, and adherence to standards will certainly pay off and allow our company to develop faster and have greater control over the manufacturing process. And that should be of great interest to us!