


DevSecOps MythBuster : “Nothing fails in the cloud / SaaS…”
Welcome back(up) to the DevSecOps MythBuster series! If somehow you have missed our previous articles, you definitely need to catch up!
And we’re just getting started! Our DevSecOps Mythubuster’s tentacles reach for another popular myth…
Myth #4 Nothing fails in the cloud / SaaS
As the number of organizations using cloud and SaaS apps grows, data loss and cyber threats become a huge concern. It is estimated that a single midsize business uses around 217 SaaS applications. For cybercriminals, it opens at least that many “doors” to break into company IT systems and steal company data.
Do you still think your data in the cloud is safe? Let’s start with a few statistics.
TechTarget’s Enterprise Strategy Group released a report in February 2023 called “Data Protection for SaaS”. They asked IT professionals about the most common causes of data loss or corruption in SaaS-based applications.
Top 3 – service outage/unavailability, malicious deletion from cyber attack, and accidental deletion.
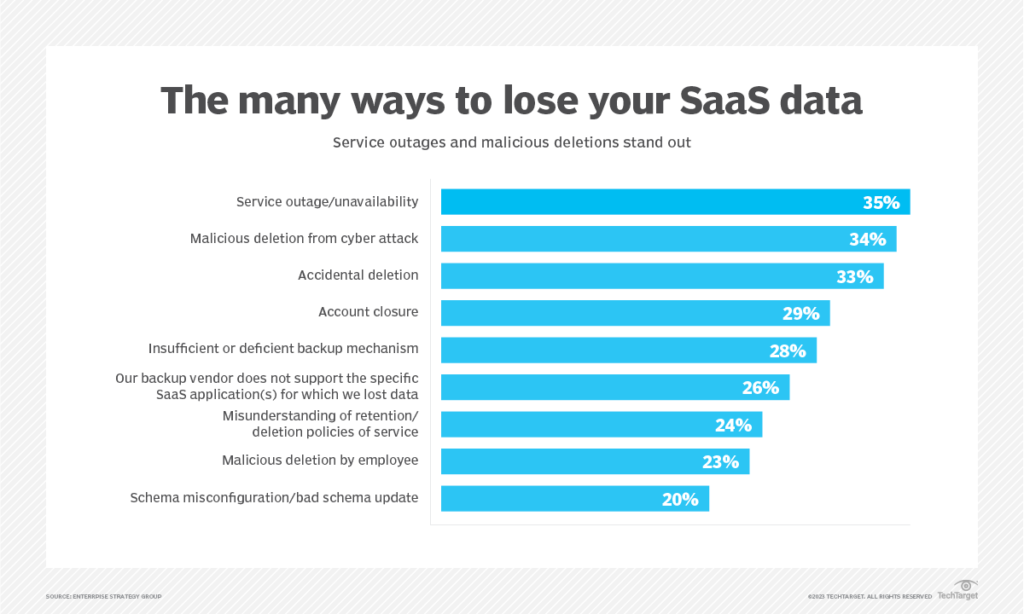
Source: TechTarget
And it’s hard for us to disagree with that. When talking to clients about DevOps backup software, these reasons, along with the need to ensure security compliance, become the main arguments for choosing our solution.
In this article, we will focus on DevOps data, kept in GitHub, GitLab, and Atlassian tools as source code, projects, and all related metadata constitute Intellectual Property which is one of the most important resources for every tech-related company.
Service downtime and outages
SaaS/cloud outages are nothing shocking – they happen to every cloud provider. While many reasons could contribute to such an unavailability, it does not necessarily mean that your data is gone. The question is what to do to keep your business up and running? How to minimize costs? Do you have a fail-over or Disaster Recovery plan for your SaaS application data?
Let’s choose the winners of this year’s list of the biggest cloud failures… A multi-day IT Glue outage in January, an hourslong Microsoft outage in March, or a fire that wreaked havoc for Google Cloud users in Europe. Pick yours.
Okay, now it’s time for Jira. We bet you heard about the biggest Jira failure of the last year. And if not, you should definitely listen to this story. An all-time Jira outage affected 775 customers and lasted for almost two weeks. And this is how long it took the company to recover all customer data. What was the reason for this massive outage? No surprises this time – human error.
To make a long story short – the reason behind it was a maintenance script that accidentally wiped hundreds of customer sites due to communication issues between two Atlassian teams working on deactivating a legacy app. However, instead of being provided the ID required to disable the app, the deactivation team was sent the IDs for the cloud sites where the app was installed. Also, the script was launched using the wrong execution mode (permanent deletion instead of recovery failsafe deletion).
Want to learn more? Read our article: Was the Jira Outage the Last Atlassian Problem?
In our annual rankings of the loudest threats, we calculated 41 incidents in Bitbucket and 53 incidents in Jira mentioned in Atlassian Status. About 11 hours Atlassian Bitbucket users were out of the service or partially out, while Jira users experienced about a staggering 329 hours of outage.
Read more: 2022 In A Nutshell: Atlassian Outages And Vulnerabilities
When it comes to Github-related “fackups” of 2022, we made a pretty long list of serious outages, high-severity vulnerabilities, data breaches, stolen credentials (and source code itself!) from well-known brands, and hacker attacks. Only the best of 133 that happened.
Once upon a time… – a true story about some ransomware attack on Git repositories
It may surprise you, but more than half of ransomware attacks last year targeted SaaS data. Ransomware attacks on SaaS tools were the most likely to be successful (52% of them resulted in data encryption).
Data in public infrastructure clouds like AWS, Azure, or Google Cloud was the no. 1 target, while endpoints, such as laptops and mobile devices, and on-premises data came in at no. 2 and no. 3, respectively.
If you think this won’t happen to your repositories or metadata, let us tell you the story of some attack…
It was a broader attack against the famous trio of Git hosting services – GitHub, GitLab, and Bitbucket. The bad actor performed command line Git pushes to repositories he accessed, indicating automated methods. These pushes overwrote the repository contents with the ransom note (below) and erased the commit history of the remote repository.
“To recover your lost code and avoid leaking it: Send us 0.1 Bitcoin (BTC) to our Bitcoin address 1ES14c7qLb5CYhLMUekctxLgc1FV2Ti9DA and contact us by Email at [email protected] with your Git login and a Proof of Payment. If you are unsure if we have your data, contact us and we will send you a proof. Your code is downloaded and backed up on our servers. If we don’t receive your payment in the next 10 Days, we will make your code public or use them otherwise.”
During this attack, a third party accessed repositories by using the correct usernames and passwords for one of the users with permission to access repositories. These credentials may have been leaked through another service. Probably through SourceTree’s free Git client, belonging to Atlassian, as it was found as the common denominator for all hacked accounts.
The security and support teams of all three companies had taken steps to notify, protect, and help affected users recover from these events. They wrote a joint article on safe practices for Git repositories. They were also working with the affected users to secure and restore their accounts. Unfortunately, there is no confirmation anywhere whether all accounts were successfully restored and how long it took.
RepoJacking – a threat that even sounds dangerous
Dependency repository hijacking (RepoJacking) has already been threatening businesses for years. It can potentially have affected major projects of such companies as Google, Kubernetes, GitHub, NodeJS, and many others. RepoJacking is a supply chain vulnerability with a subdomain takeover-like conceptual underpinning. In more common language, it results in that the attacker may take over retired organizations or users’ names and publish trojanized versions of repos to run some malicious code in it.
Want to learn more? Read our article: GitHub RepoJacking: Are You Sure Your GitHub Is Safe?
Accidental deletions
Finally, human errors – the most common reason of all data losses and one of the most favorite attack vectors for criminals.
Unfortunately, most vendors, including Atlassian do not ensure you with granular, point-in-time restore in case of unintentional deletion and daily operations. Let us remind you – for example, that it is not possible to restore a single issue from Jira if it was accidentally deleted. You probably know how much information a single issue can contain – configuration, all comments, attachments, links, or sub-tasks. All this can disappear forever as a result of one mistaken click by your employee.
More SaaS providers enable you to restore data after deletion for some given time. For example, in GitHub, a deleted repository can be restored within 90 days unless the repository was part of a fork network that is not currently empty (then it can not be restored at all). Once you discover such deletion 91 days later, you won’t be able to restore this repo anymore. The so-called permanent/hard deletion occurred.
Who is guilty? Most users!
Unfortunately, there appears to be a lot of confusion about where data loss stems from. Many organizations make dangerous assumptions about who is truly responsible for backing up the data in their SaaS applications.
In a recent blog post, we referred to this myth, described the main assumptions of Shared Responsibility Models all SaaS vendors rely on, and even quoted some parts of their terms of service.
⚠️ Know your responsibilities:
- Data availability and security
- Recovering from operational data loss, human error, or ransomware attack
- Meeting compliance and long-term data retention
- Following the 3-2-1 backup rule with multiple storages, and offsite copies in case of outages and downtime
- Data encryption and integrity.
Learn more – check our previous blog post
That is why even though Atlassian, GitHub, and GitLab offer some form of native ‘backup’ (we would say “clone”) features, they recommend using professional, third-party DevOps backup tools to guarantee a reliable Disaster Recovery in the event of data loss, attack, human error or system failure.
For example, GitLab mentions GitProtect as a standalone GitLab backup on their website.
How to protect your data against deletion?
DevOps backup & recovery solution. Make sure it offers two restore options – granular restore of only chosen objects in case of accidental deletion and daily human errors and Disaster Recovery technology that instantly restores all SaaS application data in bulk. This can prevent business downtime and interruptions in the event of a ransomware attack or long-term service unavailability.
At GitProtect, we’ve safeguarded critical data across cloud, on-premises, or SaaS environments for thousands of customers. Focusing on business and DevOps-critical data in Jira, GitHub, GitLab, and Bitbucket, we’ve made a native, dedicated software that ensures your data recoverability, accessibility, and security compliance.
Disaster Recovery:
- Every-scenario-ready – when GitHub/GitLab/Atlassian, yours or our infrastructure is down
- Point-in-time restore – thanks to flexible versioning and unlimited retention, you can restore data from a very specific point in time (even from years).
- Many destinations – the same or new account, local machine.
- Restore between deployments – from cloud to on-premise accounts, cloud to cloud or local to cloud.
- Cross-over recovery – to another Git hosting platform (e.g. from GitLab to GitHub, and conversely) that can also be used to migrate data to another tool.
Jira Granular Restore:
- Browse copies and immediately restore any deleted object in Jia – projects, issues, workflows, attachments, and more.
- Migrate Jira data and the entire configuration from one project to another
- Move data between various Jira accounts
- Copy project configurations from Sandbox to Production
- Separate out projects or consolidate different Jira sites into one

Granular Restore for GitHub, GitLab or Bitbucket:
- Browse copies and immediately restore any deleted object – chosen repository or metadata
- Migrate repositories and the entire configuration from one account to another
- Move data between various accounts and even vendors (i.e. GitHub to GitLab or Bitbucket and conversely)
- Separate out or consolidate accounts.
- Restore data between deployments (SaaS to self-hosted and conversely).
Don’t trust blind – experience it for yourself.
[FREE TRIAL] Ensure compliant DevOps backup and recovery with a 14-day trial 🚀



