


Git Restore: How to Restore Deleted Files in a Git Repository?
Restoring deleted files with commands like ‘git restore’ might seem straightforward, but it can’t serve as the foundation of your backup strategy. Let’s explore why…
Have you ever accidentally deleted a file from your DevOps environment, like GitHub, GitLab, Azure DevOps, or Bitbucket? Did you wonder how to restore deleted files from your repository, how to check if such a restore will work properly, or how to track file changes in the backups themselves? Have you wondered how the git restore command works? Do you do backups of version control systems at all, and are you sure that your source code and multiple files in your repositories are safe? Do you use commands like git clone and git restore to recover deleted files?
They are critical questions, because while Git is a powerful distributed version control system, it was never designed to be a backup solution. Treating Git commands or custom scripts as a substitute for backup exposes organizations to unnecessary risks.
Key insights:
💡 Git commands like git restore, git checkout, and git clone are not backups. Yup, they can help recover deleted files or undo local changes, but they don’t provide full, reliable protection for repositories or metadata.
💡 DIY backup scripts are fragile and costly to maintain. Custom scripts require constant updates, documentation, and testing. Without dedicated resources, they often fail silently (without the possibility to restore accidentally deleted files, for example), leaving teams with a false sense of security.
💡 A cloud service provider is not a backup. Storing code in GitHub, GitLab, Bitbucket, or Azure DevOps doesn’t guarantee protection. Outages, ransomware, or accidental deletions can still wipe data or make it temporarily inaccessible.
Backup approaches for ‘git restore’ deleted files
The problem discussed here is the lack of a standard for archiving distributed version control systems. Let’s assume, for example, that we have a local Git server adapted to our needs, and we want to back up this custom solution now, but how do we do it?
You can, of course, archive the entire server, but it’s a backup of everything, including the operating system and unnecessary or even potentially dangerous files with all the file content, applications, etc.
So, how do you perform a Git backup when you want to recover deleted files, and how do you take care of our repositories? We have built-in Git tools like git clone, but how to deal with incremental archiving of individual repositories in such a system, and how to take care of changes made to multiple files?
We can, of course, throw our repositories into a, for example, GitHub cloud, but it’s also not a backup. We must remember that the “cloud” is someone else’s computer and that someone may also have failures. Moreover, all service providers, like Microsoft, Atlassian, or GitLab, follow the Shared Responsibility Model, which clearly defines that your account data is your responsibility. So, it’s you who needs to protect it… and back it up.
Git is exciting and awesome, but it can be dangerous
Listing 1. How to create a PDF file with the ‘git clone’ command
The git bundle command is fascinating. It bundles a set of Git objects (even an entire repo) into one single file. Git bundle is implemented in Git, and thanks to this git command line, you can treat that file as if it were a standard Git database. Let’s look at Listing 1…
git clone -mirror company.pdf kafej
Cloning into ‘kafej’...
Receiving objects: 100% (221/221), 111.21 KiB, done.
Resolving deltas: 100% (100/100), done.
$ cd kafej
$ ls
company.pdf company.tex
Listing 1. Creating a PDF file with ‘git clone’ command.
Listing 2. How to create a valid PDF file with the ‘git bundle’ command
The command git clone -mirror company.pdf company will create a PDF file for us, which will be a Git repository. I mentioned it specifically because all the fun starts with the following command – git bundle. It turns out that thanks to a minor modification in the “bundle.c” file, which consists of disabling the compression, we can prepare a PDF file from which Git will be able to clone a repo in your working directory. Let’s look at Listing 2…
$ git init
$ git add kafej.pdf
$ git commit kafej.pdf -m “added”
$ git bundle create company.pdf -all
Listing 2. Creating a valid PDF file with ‘git bundle’ command.
Listing 3. How to restore files from the Git repository
The file prepared in this way is intriguing, to say the least. Because thanks to the change introduced in a “bundle.c” file, it will be a valid PDF file, and in principle, most PDF readers will open it like a regular one. It offers many possibilities, good and bad ones.
The git restore command is also interesting. Hopefully, you are aware that this tool doesn’t roll back the changes to the repository. We know the name can be confusing, but this comand tells git restore fileName will only remove from this file your local changes. So, thanks to this command, we can undo local changes, but only on our disk. In fact, if you need to restore the file from your repo, you can do that with the git checkout command. Let’s look at Listing 3…
$ git rev-list -n 1 HEAD -- kafej.xml
$ git checkout 9ad202d538c6ee6448e2c1ca1529f0e78edd3f86~1 -- kafej.xml
Listing 3. Restoring files from the Git repository.
First, we need to use the git rev-list command to find the last commit and then use the checksum to restore the file (e.g, an accidentally deleted one) we are interested in using the git checkout command. Of course, restoring files is not difficult, and we can do it, but thanks to GitProtect backup and Disaster Recovery for DevOps tools, restoring files and your entire environment with GitHub, GitLab, Bitbucket, or Azure DevOps data is much faster. Moreover, you can have peace of mind that in any disaster scenario, you can easily retrieve missing files or lost files of your DevOps environment.
Stop treating git clone like a backup
Let’s imagine a scenario in which we already have a script based on git clone or git bundle, and let’s even assume that we are sure that such an internal solution is sufficient for us. I hope that, based on the above proof-of-concept, everyone is aware of the dangers of such an approach.
Custom scripts prepared by an internal team inside the company work well. Still, we must have a group of people who will constantly update such a script, check its operation, and refresh the documentation… Only then can we be tempted to say that we are relatively safe.
Without well-prepared documentation, we have to consider big problems when, for example, the main person from such a team suddenly quits their job. However, without constantly checking whether the script is appropriately preparing backups, we can only assume that we do not have backups.
In turn, the lack of updating the script for new versions, such as GIT, may result in incorrect execution of this script.
So, it means a lot of work and much time…
It’s estimated that IT teams might spend over 250 hours a year on backup processes and still have no guarantee that they will be able to restore their data in case of a failure, like a service outage, internal organization’s downtime, ransomware attack, or you simply accidentally deleted a file and noticed that only after a few weeks (or even months!), etc.
⚠️ Just to mention, according to the CISO’s Guide to DevOps Threats, DevOps service providers faced:
GitHub: 26 major impact issues with 130+ hrs of disruption
Bitucket: 4 major impact issues with 4 hrs of disruption
GitLab: 7 major impact issues with 790+ hrs of disruption

Backup solution wins over backup scripts
Third-party backup tools, like GitProtect, on the other hand, are comprehensive solutions that will always ensure that the repositories and all the related metadata (like deleted important files) are safe and available for recovery at any moment and from any point in time.
For example, Zoop, one of the biggest fintech companies in Latin America, decided to back up its GitHub repositories with GitProtect backup and Disaster Recovery software after dealing with backups on its own for some time. First security engineers of the company manually backed up each repo, which needed a lot of manual maintenance, but then, after evaluating its tries, the organization decided on a third-party backup tool.
“When we need to restore a repository, GitPorotect brings speed, convinience and secuirty to this process,”
– says Andre Esteves, Senior Security Analyst at Zoop (Read the full Case Study here)
However, behind the decision to opt for GitProtect was also the compliance requirements. As the majority of compliance protocols, like NIS2, SOC 2, ISO 27001, etc., require organizations to be able to restore their data in case of a disaster, and, unfortunately, backup scripts can’t guarantee it.

How to restore your deleted files with GitProtect
We have already mentioned that GitProtect isn’t only an application or a tool for backup. It’s a comprehensive product that gives you a reliable backup of your data without any additional application or script. So there is no need to trigger any git commands, like git restore, git checkout, or git clone, to back up or restore your deleted files on GitHub, Bitbucket, Azure DevOps, or GitLab.
The data restore option is available directly in the management panel. Thus, all you need to do is choose the data you want to restore from (point-in-time restore) and decide on a location you want to restore deleted files to:
- to the same GitHub, GitLab, Bitbucket, or Azure DevOps repo,
- a new repository (a new location),
- crossover recovery – to another hosting platform. It enables fast and easy migration – you can restore your Bitbucket repository to GitHub, Azure DevOps, or GitLab and conversely,
- your local repository service/device.
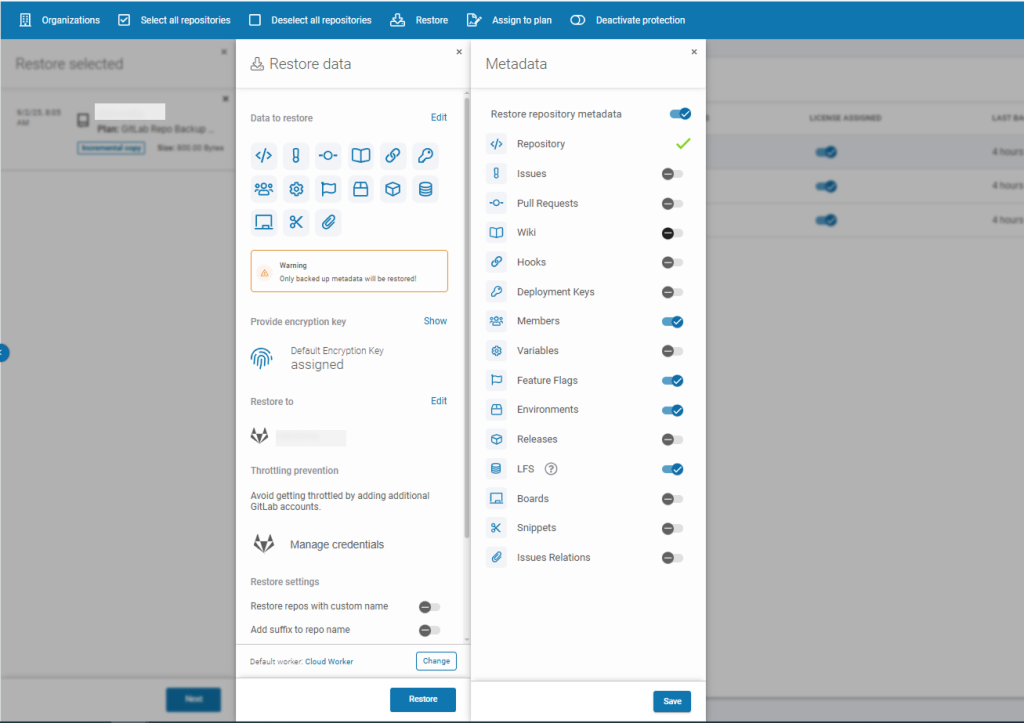
Choosing metadata to restore with GitProtect backup and Disaster Recovery software
It’s also worth mentioning that you get the option to restore not only one repo or many repositories, but also all or selected metadata from a given backup.
Before you go
📚 Make sure that all the git commands are at hand – download the Git Commands Cheat Sheet that breaks down all the necessary git commands and terms, like git log, git status, git show, git reset, git checkout head, commit hash… and much more
📚 Want to deepen your skills in git clone? Check out our Git Clone Guide – a specific file that focuses deeply on git clone options when it comes to file deletions
🔎 Find out more about backup best practices and how to make your DevOps backup the most effective when it comes to data recovery
📅 Schedule a custom demo to learn more about GitProtect.io backups for DevOps tools to ensure your continuous workflows
📌 Or try GitProtect.io backups for GitHub, Bitbucket, GitLab, Azure DevOps or Jira environments to eliminate data loss and ensure your business continuity
The article was originally published on May 27th, 2021



