


How to Use Git Pull Force to Overwrite Local Files
Since the work of programmers has become teamwork – that is, practically always – there has been a need to synchronize the code created by different people. Currently, the world is so computerized that even companies that do not deal with software, more and more often have internal IT departments for their own needs. As a result, we have more and more developers, and that means more and more code to sync, and it repeats over and over again.
While working on Linux, Linus Torvalds felt this problem the hard way and developed the Git system, which makes it much easier to synchronize code and, as a result, speeds up its production. Git is known as a distributed version control system. But what does that mean? Well, each working copy on the developer’s computer is literally a copy of the entire repository. Thanks to this, we can make any changes locally, add or remove code, create new branches, etc. It is also a security feature because in the event of a failure we can restore the repository based on only one local version. Although I wouldn’t rely on that and we should always have the right backup tool.
There is one more thing related to such distributed architecture – determining which copy will be the main one. All the others will integrate into it. Our changes will be uploaded there and we will download other changes from it. Thanks to this solution, each local copy knows only about one external repository and does not have to integrate with any other. This solution is borrowed from centralized solutions, such as SVN, but it is worth being aware that this is just a standard and practice, not a feature or limitation of the Git tool itself.
Git workflows
Since we are talking about standards and practices, it is worth getting acquainted with the different types of Git workflows. It is important that regardless of the workflow used, synchronization of changes comes down to two operations – downloading new changes from the server (pull) and sending our changes there (push). If every programmer creates new files, there is no problem here, he or she downloads code created by others and adds what he or she created themself. However, real-life is far from perfection and this is rarely the case. Usually, the team works on the same files, which runs the risk of overwriting changes made by someone else. The use of the appropriate workflow, mentioned in the link above, allows us to deal with it by ensuring the current branch is updated correctly during synchronization.
Git push and git pull calls
Leaving the workflow behind us, let’s analyze how exactly the data synchronization mechanism in Git works. Let’s start with what happens when we send our changes out. The operation for this is called ‘push’. Here is a small digression on merge strategies. If the story is linear and the merge adds another commit at the end, then the so-called fast-forward occurs. It just adds the commits that were sent and updates the branch so that it now points to the newly added changes. The second situation is when we have a branched history and there is an additional so-called merge commit. Let’s see it in the pictures below:
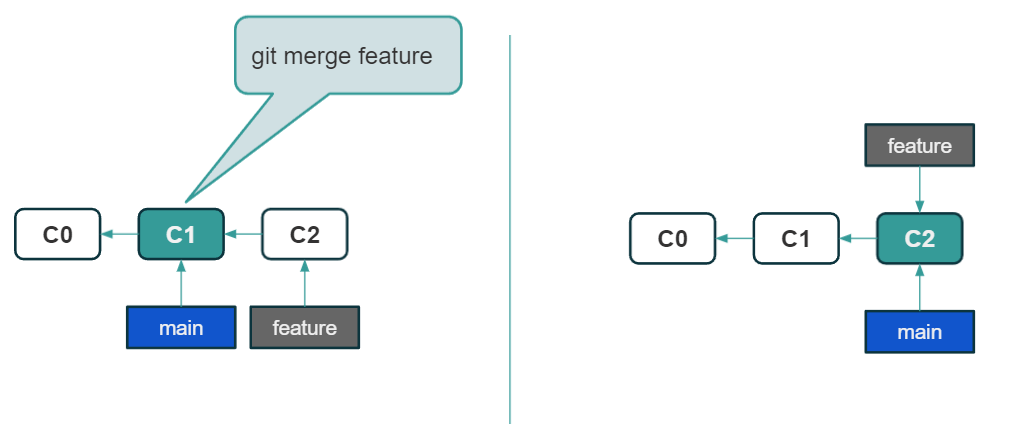
fast-forward
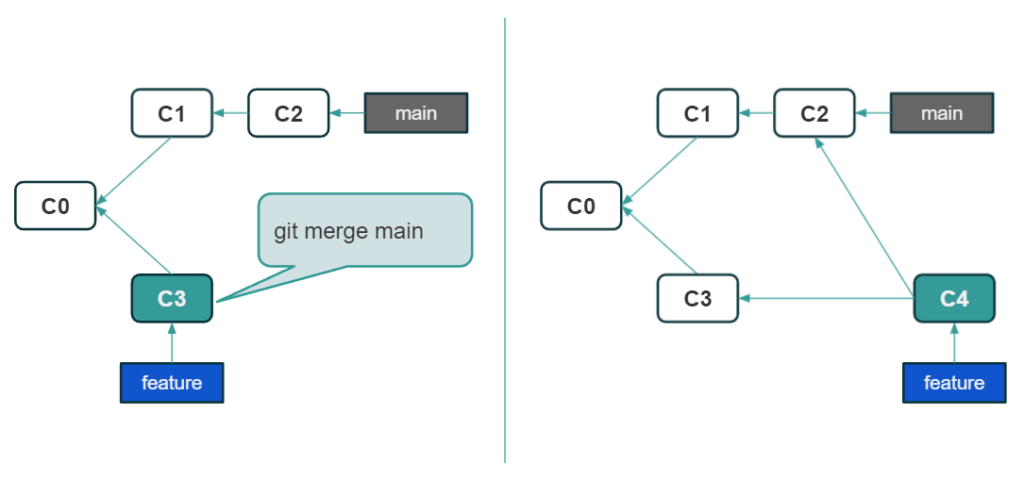
3-ways merge
Let’s go back to the “push” operation. It is only possible if fast-forward execution is possible. Our local changes land in the remote repository and all other project members can download them from now on. If a fast-forward merge is not possible, Git will not let us sync as it is and we will get an error message. Most often it results in the fact that we have to locally download the latest version of the code, perform the merge on our machine, and only then try to send our changes to the remote repository. The git merge command integrates changes from one branch into another, resolving any conflicts that may arise.
I mentioned downloading the latest version of the code. This is what the “pull” operation is for. In fact, it takes two steps, the first is the fetch operation, which downloads code from a remote repository to the so-called remote-branch, which is a local copy of what’s outside. And then a merge to the local working branch is performed. The git merge command offers various options and behaviors during this process, such as controlling fast-forward merges and handling merge conflicts. Then our changes will be merged (or not, more on that in a moment) and we have the current code version, identical to the state in the remote repository.
How secure are your repos and metadata? Don’t push luck – secure your code with the first professional GitHub, Bitbucket, and GitLab backup.
Merge conflict
Git can efficiently merge changes automatically, but this is not always possible. Because what should happen when two people simultaneously change the name of the same file, and into two completely different ones? Are you sure the machine should decide? Of course not, and Git is aware of that. In the case of changes that cannot be unequivocally assessed and automatically combined, there is the so-called “merge conflict”. Merge conflicts occur during the merging process when integrating changes from different branches or when local changes conflict with updates from a remote repository. This is a situation where the merge operation was interrupted mid-execution and manual action is required to end the conflict. At this point, I will skip the topic of available graphical tools to facilitate this task and the details of conflict resolution itself.
It is important that the conflict can be solved in two ways – interrupt the operation and return to the state before the merge option is run, or select the changes to be accepted and approve them with the commit operation. A new so-called merge commit that introduces conflict-free changes to the repository. Now just send a new commit to the external repository and the situation is under control.
An effective method of avoiding conflicts (or rather minimizing their number) is frequent synchronization. This helps to reduce the number of conflicts, and even if they do occur, they are usually easier to resolve. Using git diff after executing commands such as git fetch can help analyze differences between local and remote changes, making it easier to resolve merge conflicts. But let’s consider one thing – can git pull overwrite local changes? Well.. not by default. Remember that in the case of a “pull” operation, there are actually two operations – fetch and merge. Eventually, even if our changes are replaced locally, it will be done through a merge commit, so what we had in the code before will still exist in previous commits. We cannot talk about overwriting here, since our code has not disappeared from the repository. However, as a reminder, this is the case of the default (and most common) behavior. So let’s have fun and try to really overwrite something.
Overwriting and “force” parameter
There is the magic word ‘force’ in Git, which is the parameter of many commands. It is both salutary and dangerous, depending on whether it is used correctly and consciously. In general, this parameter allows us to force an operation that Git would not normally want to perform. There can be many reasons here, e.g. history mismatch at the time of push execution. Earlier I described how “push” and “pull” operations work by default, but now let’s check what happens when we add this new parameter to them. So how to force git pull? To make it short, you can force git repo to pull data from some remote repository by fetching data from it and then resetting changes to the branch. Git doesn’t have a direct ‘git pull –force’ command, but you can achieve a similar effect by using ‘git fetch’ followed by ‘git reset –hard origin/main’ to overwrite a local branch.
Git pull force actually affects only one of its components, namely the fetch operation. In one case, to be exact. Let’s take a look at the Git documentation for the “fetch force” operation for a moment:
When git fetch is used with < src>:< dst> refspec it may refuse to update the local branch as discussed in the < refspec> part below. This option overrides that check.
And further, in the <refspec> section, we can find an example that explains the <src> and <dst> parameters above:
tag <tag> means the same as refs/tags/<tag>:refs/tags/<tag>; it requests fetching everything up to the given tag.
The remote ref that matches <src> is fetched, and if <dst> is not an empty string, an attempt is made to update the local ref that matches it.
So, here we have our potential use of the –force flag. As described in the documentation, until we specify the second parameter manually, the parameters of < src> and < dst> are the same and there should be no error here. This is the default behavior. However, if we intentionally want to download the content of another branch under a given branch, so our parameter values will be different, there may be a synchronization problem here and Git will refuse to perform such an operation. Here, our new friend comes to the rescue, which will force such a step to be performed despite the differences in both branches. However, we must be sure what we are doing, because this step will override our local changes. So the answer to ‘how to force pull in git?’ is simple – use the “force” parameter at the end of our statement. Additionally, when using ‘git checkout’ to switch branches, be aware that Git will prevent switching if there are uncommitted changes that might be lost during the process.
What does git push force do?
Let’s move on to the next operation. What does git push force do? Here the matter is a bit different because git push force will overwrite changes in the remote repository, not our local one. Which is potentially much more dangerous! By default, Git will only push if it succeeds in doing the aforementioned fast-forward merge. In any other case, we will get an error and the operation will be rolled back. This is well structured because it forces us to keep order in the history and to sync locally before we can send our code out. Additionally, during the push operation, local branches are updated with the latest changes from the remote repository.
Well, we are not talking today about ‘normal’ actions, but about how to avoid them with our magic flag. Adding “force” during a “push” operation will cause Git to accept our every change, no matter how messy we’ve made in the commits history. We just say “do it anyway” and overwrite the story forever. It is very dangerous because it creates the risk of losing a large amount of data and usually such an operation is unacceptable in a well-configured repository. The local repository plays a crucial role in synchronizing changes with the remote repository, ensuring that developers can manage their code effectively. Let me also post another quote from the Git documentation on this topic:
This flag (…) can cause the remote repository to lose commits; use it with care.
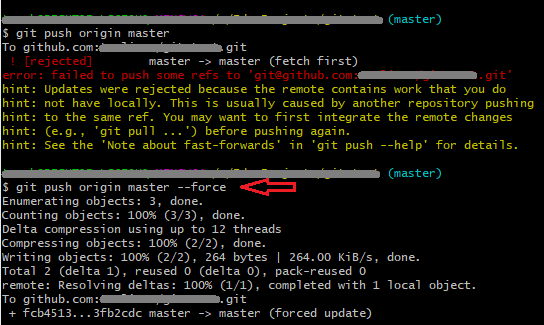
Boom… If we do something like this, at this point our repository history has already been overwritten and we have potentially lost some data.
Is git force push bad?
I will answer in my favorite way – it depends. Generally, as agreed, it is a very dangerous tool and must be used wisely. But can it be called bad? It will cause a lot of problems for us when misused, but for some reason, it still exists in Git. I will give you a simple example from my own experience. I teach people programming and we often use Git repositories for workshops. Each workshop has its own repo, these are not big projects but are made in large numbers. Often, when a new one is created, there is already some commit in it, e.g. with a README file or something like that. Well, I already have a locally created project that I want to put all into this repository and not mess with any merging of changes. The “force” parameter comes to your aid. The effect is that I delete everything that was in this repository so far and put there only what I prepared earlier myself. A simple example, but it shows the usefulness and principle of operation of this tool.
Note: Before using ‘git push force’, you can use ‘git stash’ to manage uncommitted changes, allowing you to revert to a clean working directory.
There is also a fundamental difference between using git push force and git pull force. Overwriting changes while downloading modifies our local copy, so it is not a dangerous action from the perspective of the entire project. Up to a point at least. In the case of “push” operation, the problem is more serious because it affects everyone using this repository and can be quite a mess. Fixing such a problem can take a lot of time and nerves. And money too. After a ‘git push force’ operation, you can use ‘git stash pop’ to retrieve and apply stashed changes, effectively managing your version control. It should come as no surprise to anyone when I mention the necessity to make backups.
🔎 Learn more on how to build a reliable DevOps data protection strategy – DevOps security & backup best practices
Summary
So let’s put it all together. Is using the “force” option risky? Yes. Very much, especially in the case of “push” operation. Do I need special permissions to use this option? By default, Git does not impose this, but popular services such as GitLab, GitHub, and Bitbucket do allow this. And important branches should have such security if we take our projects seriously. This is called protected branches, and it allows you to make various rules, including protection against the “force” option. And is it a bad practice to use this option? No, as long as we use it for the purpose for which it was created and we are fully aware of the consequences. Additionally, using the ‘force’ option can lead to issues with ‘untracked working tree file’ errors, where local uncommitted files conflict with incoming changes, potentially causing loss of local changes.
Finally – do we need a backup? Of course. It is always needed and we should always remember about it. Especially when we play the very dangerous game of overwriting history by force.
[FREE TRIAL] Ensure compliant DevOps backup and recovery with a 14-day trial 🚀
[CUSTOM DEMO] Let’s talk about how backup & DR software for DevOps can help you mitigate the risks



