


How to Protect Jira Assets: Best Practices For Backup And Recovery
It’s hard to imagine a modern ITSM (IT Service Management) and general configuration management in Jira without Jira Assets. All the more so, it allows IT teams to model physical infrastructure, logical dependencies, user ownership, licensing, and even financial amortization of resources. The possible challenge is its hybrid architecture, followed by tight schema and application logic coupling. Any automation error or misconfigured import may corrupt your CMDB.
Forget about hypothetical situations. The market knows numerous multi-hour outages in ITSM operations. Mainly due to schema-wide cascading deletions and overwritten attribute sets (caused by faulty API scripts).
Certainly, protecting this layer requires you to deeply understand how data is stored and where the critical paths lie. You also need to get familiar with how to build a backup and recovery pipeline that aligns with:
- RTOs under 1 hour,
- RPOs under 15 minutes,
- ability to pass integrity validation under load.
According to the CISO’s guide to DevOps threats, Atlassian’s Jira experienced 132 incidents of different impact in 2024, which shows a 44% growth compared to 2023.
Assets storage model. What you’re backing up
Jira Assets data is stored across specific ActiveObjects tables in the Jira database (Data Center). The most vital include (among others):

The tables mentioned use foreign keys and serialized JSON structures. They require precise relational consistency to avoid orphaned data or circular dependencies.
However, elements like attachments reside in the filesystem. They’re placed within the /data/attachments directory in Jira Home by default. If you exclude attachments from backup, object attributes pointing to these files will break (unnoticed) during recovery. The Jira system will fail to render previews or links.
In the case of a Cloud instance, the approach is different. You can say Atlassian abstracts this layer entirely. Jira Assets data resides in a proprietary backend atop an AWS stack. That means there is no direct database access. Backups must be handled via the Jira Assets REST API – with or without third-party tooling.
Part 1. Solutions for Jira Assets DC
Though Atlassian has already announced the end of support for its Data Center by March 28, 2029, let’s still look at some of the options. A full backup of Assets on Jira Data Center starts with consistent database snapshots. For PostgreSQL, a point-in-time consistent export of relevant tables may be set using:
pg_dump -Fc \
-t "AO_8542F1_IFJ_OBJ" \
-t "AO_8542F1_IFJ_OBJ_TYPE" \
-t "AO_8542F1_IFJ_ATTRIBUTE" \
-t "AO_8542F1_IFJ_SCHEMA" \
jira_prod > assets_only.dumpYou have to execute such an export with complete transaction consistency. So, –no-synchronized-snapshots is not advised. Significantly, if the schema changes due to ongoing imports or automation.
At the same time, the attachments must be captured:
tar -czf attachments_$(date +%F).tgz
/var/atlassian/application-data/jira/data/attachmentsHowever, in regulated industries, best practices include generating SHA256 hashes post-backup:
sha256sum assets_only.dump attachments_*.tgz > backup_hashes.sha256During recovery, this approach validates that no tampering or corruption has occurred.
A bit deeper dive into database backups in Jira
It’s worth noting that Atlassian recommends native database tools for backups due to their reliability and performance. For PostgreSQL, the usual choice for logical backups in Jira is the pg_dump utility. For physical backups for larger instances, pg_basebackup is best.
For example, configure a cron job on the Jira Data Center to create a daily logical backup:
#!/bin/bash
BACKUP_DIR="/backups/jira/db"
TIMESTAMP=$(date +%Y%m%d_%H%M%S)
DB_USER="jirauser"
DB_NAME="jiradb"
BACKUP_FILE="$BACKUP_DIR/jira_db_$TIMESTAMP.sql.gz"
mkdir -p $BACKUP_DIR
pg_dump -U $DB_USER $DB_NAME | gzip > $BACKUP_FILE
# Rotate backups (keep 7 days)
find $BACKUP_DIR -name "jira_db_*.sql.gz" -mtime +7 -deleteThe script above dumps the database, compresses it, and rotates backups to manage disk space. Of course, you need to ensure the DB_USER has sufficient permissions. Then, it’s time to test the backup integrity using gunzip and psql to restore it to a test environment.
Another example of a daily dump in PostgreSQL may look like this:
pg_dump -U jira_user -h localhost -F c -b -f /backups/jira_db_$(date +%Y%m%d).backup jira_dbFor comparison, the same step, but with rotation, in MySQL can be shaped as shown below:
mysqldump -u jira_user -p$PASSWORD jira_db | gzip > /backups/jira_db_$(date +%Y%m%d).sql.gz find /backups -type f -name '*.gz' -mtime +30 -deleteConsidering physical backups in PostgreSQL, pg_basebackup provides a faster option for large databases (>50GB). For example:
pg_basebackup -U $DB_USER -D /backups/jira/pg_basebackup_$TIMESTAMP -Fp -Xs -PThe command creates a full backup of the PostgreSQL data directory. Combined with write-ahead logs (WAL), it’s suitable for point-in-time recovery (PITR). To enable WAL archiving, configure archive_mode and archive_command in postgres.conf.
archive_mode = on
archive_command = ‘cp %p /backup/jira/wal/%f’What about filesystem backups?
As you already know, the JIRA_HOME directory, typically located at ~/.jira-home, contains critical files like attachments (data/attachments), indexes (caches/indexes), and configuration files.
To back up the described directory, you need careful synchronization to avoid corrupting Lucene indexes, which Jira utilizes for search. So, if you aim for a robust solution, then the rsync method with a pre-backup script to pause indexing is a good choice.
#!/bin/bash
JIRA_HOME="/var/atlassian/application-data/jira"
BACKUP_DIR="/backups/jira/fs"
TIMESTAMP=$(date +%Y%m%d_%H%M%S)
BACKUP_FILE="$BACKUP_DIR/jira_home_$TIMESTAMP.tar.gz"
# Pause indexing
curl -u admin:admin -X POST http://jira.example.com/rest/api/2/indexing/pause
# Sync and archive
rsync -av --delete $JIRA_HOME /tmp/jira_home_backup
tar -czf $BACKUP_FILE -C /tmp jira_home_backup
# Resume indexing
curl -u admin:admin -X POST http://jira.example.com/rest/api/2/indexing/resume
# Rotate backups
find $BACKUP_DIR -name "jira_home_*.tar.gz" -mtime +7 -deleteThe script:
- pauses indexing through Jira’s REST API,
- syncs the JIRA_HOME directory
- archives it
- resumes indexing.
You need to replace admin: admin with a service account. In the next step, secure the credentials using a .netrc file or environmental variables.
In general, the rsync command for attachments and indexes may be utilized as:
rsync -avz /var/atlassian/application-data/jira/ backup-server:/jira_backups/
Jira’s built-in backup service
Like any self-respecting software developer, Atlassian has implemented a native data backup mechanism in Jira. The platform’s admins utilize an XML backup utility, accessible via:
Administration → System → Backup System
It generates a single ZIP file containing issues, configurations, and selected JIRA_HOME data. The solution is convenient yet very limited. The mechanism excludes attachments and is resource-intensive, often causing performance degradation on large instances with more than 500,000 issues.
For smaller instances, you can schedule XML backups using a script involving the REST API. For instance:
#!/bin/bash
JIRA_URL="http://jira.example.com"
USERNAME="admin"
PASSWORD="admin"
BACKUP_DIR="/backups/jira/xml"
TIMESTAMP=$(date +%Y%m%d_%H%M%S)
# Trigger backup
curl -u $USERNAME:$PASSWORD -X POST "$JIRA_URL/rest/backup/1/export/runbackup" -H "Content-Type: application/json" -d '{"cbAttachments": false}'
# Wait for backup completion and download
# Note: Implement polling logic to check backup statusHowever, automating XML backups is less reliable compared to database and file system backups. The method can cause potential timeouts. If so, it should be reserved as a secondary option (or for configuration exports).
Testing point-in-time restore: granular recovery and referential pitfalls
Exceeding acceptable downtime windows while restoring full backups isn’t rare. Many or even most teams aim for granular restores. Especially during incidents initiated by automation or import errors.
However, such a step is far more complex than it appears.
Let’s take rolling back a single object as an example. It requires identifying all dependencies (e.g., attributes that refer to other object types, automation rules using such attributes), truncating the specific object set, and reinserting from a filtered pg_restore.
For instance (SQL):
DELETE FROM AO_8542F1_IFJ_OBJ WHERE OBJECT_TYPE_ID = 11203;
pg_restore --data-only --table=AO_8542F1_IFJ_OBJ --file=filtered_obj.dump assets_only.dumpHowever, making such changes without setting up the necessary rules for your data (attribute constraints) and the unique identifiers linking things together (UUID bindings) can lead to problems. You might have broken connections between the data (dangling objects).
Other issues might be inconsistencies in your system’s overall structure, such as breaking schema consistency. Therefore, you must test restores on staging. You should be using the exact version of Jira and the plugin state. Equally important is utilizing checksum-based post-restore validation against a dataset.
Part 2. Solutions for Jira Assest Cloud
It’s worth reminding that Atlassian Cloud doesn’t officially support full schema-level exports in JSON format via the REST API. They were part of older Insight Server versions. The recommended way to export (backup) large sets of objects is to use the CSV export with the Jira (Service Management) UI.
If you plan to automate exports (backups), you usually:
- export CSV files manually or utilize scripting UI automation
- or use the REST API to retrieve objects individually or in pages (pagination), which requires custom scripts.
For example, let’s retrieve the workspace ID required for API calls. Before making the latter, you need your workspace ID (bash):
curl -u [email protected]:API_TOKEN \
-H "Accept: application/json"\
"https://yourdomain.atlassian.net/rest/servicedeskapi/insight/workspace"Note the “id” field of the workspace you want to work with from the JSON response.
To restore objects from JSON files, you must send a single (one) POST request per object. For this purpose, you use the current Assets API endpoint and Basic Auth with an API token.
For instance, take a JSON file (object_345.json):
{
"objectTypeId": "250",
"attributes": [
{
"objectTypeAttributeId": "2797",
"objectAttributeValues": [
{ "value": "Object Name" }
]
},
{
"objectTypeAttributeId": "2807",
"objectAttributeValues": [
{ "value": "Object Description" }
]
}
]
}Of course, you must get the correct objectTypeId and objectTypeAttributeId from your Assets schema configurator or via API.
Now, create a POST request to create an object:
curl -X POST \
-u [email protected]:API_TOKEN \
-H "Content-Type: application/json" \
-d @object_345.json \
"https://api.atlassian.com/jsm/insight/workspace/{yourworkspaceId}/v1/object/create"It’s worth mentioning that:
- the old endpoint https://yourdomain.atlassian.net/rest/insight/1.0/object/create is deprecated and doesn’t work in Atlassian Cloud
- bulk export of objects in JSON format via the REST API is not supported in Atlassian Cloud
- for large datasets, export CSV using UI or implement paginated object retrieval through API
- import requires sequential POST requests per object, respecting object type and attribute IDs.
A quick look at recovery procedures
Approaching database recovery, let’s start with logical backups. To restore the latter, you can use:
gunzip jira_db_20250415_120000.sql.gz
psql -U jirauser -d jiradb < jira_db_20250415_120000.sqlWhen it comes to physical backups, you should stop the PostgreSQL service. Then, you copy the backup to the data directory and replay the WAL files (if using PITR). The last thing is to test restores in a sandbox environment to validate RTO and RPO.
File system recovery with validating and testing
When you want to restore JIRA_HOME, the first thing to do is to stop Jira. Then it’s done, extract the backup, and verify file permissions. For instance:
tar -xzf jira_home_20250415_120000.tar.gz -C /var/atlassian/application-data
chown -R jira:jira /var/atlassian/application-data/jiraFurther, rebuild indexes in Administration → System → Indexing after restoration to ensure search functionality.
A good practice (or even a must) is regularly testing backups by restoring them to a staging environment. You can automate the process with a script to check backup integrity.
#!/bin/bash
BACKUP_FILE="/backups/jira/db/jira_db_20250415_120000.sql.gz"
gunzip -t $BACKUP_FILE && echo "Backup is valid" || echo "Backup is corrupt"In short, a backup is useless if it can’t be restored.
Jira Assets backup automation and third-party integrations
Experts across the Internet keep repeating that manual backups are error-prone. To remove human-made errors from the backup and restore equation, top-performing teams integrate tools like GitProtect.io.
It’s an enterprise-grade, automated backup and disaster recovery tool, tailored for DevOps and PM data protection, including Jira, Bitbucket, GitHub, GitLab, and Azure DevOps..
The GitProtect solution allows you to back up and restore your Jira Assets in a few simple steps.
From the Jira admin’s perspective, the solution extends backup and recovery beyond Atlassian’s native capabilities. Companies can use granular control, compliance, and resilience for mission-critical workflows.
Here’s why:
Cross-tool dependency protection
Usually, Jira is integrated with other DevOps tools, for example:
- Git repositories (e.g., issues referenced in commit messages)
- CI/CD pipelines are connected via third-party integration automation rules.
GitProtect.io backs up Jira Cloud and Git repositories (GitHub, GitLab, Bitbucket, Azure DevOps), preserving platform issue references.
When backups are configured across these tools, GitProtect ensures that cross-referenced data (e.g., Jira issue keys in Git commits) remains accessible after recovery, provided all linked systems are restored.
Backup automation without script maintenance
Even though Atlassian Cloud provides basic backups and Data Center requires manual scripts, GitProtect allows for:
- Policy-drive scheduling
For example, daily incremental and weekly full backups.
- Pre/post-backup hooks
For instance, pause indexing during backup to ensure consistency.
- No reliance on brittle pg_dump or filesystem snapshots
Compliance and legal hold
The tool uses immutable backups (WORM storage) for audit trails, which is crucial for SOC2/ISO 27001. Backups are supported with role-based access control; for example, Jira schema restores are restricted to admins.
Faster, granular recovery
GitProtect allows you to restore individual issues (not just the entire project) through Jira’s REST API integration. Your team can also utilize point-in-time recovery for attachments or workflows corrupted by misconfigured apps.
Offsite replication for disaster recovery
The tool makes it easy to connect and use hybrid storage targets (e.g., AWS S3, Azure Blob, on-prem NAS, etc.) with encryption-in-transit. This also entails geo-redundancy to meet RPO/RTO SLAs, e.g., under 1 hour recovery for critical projects.
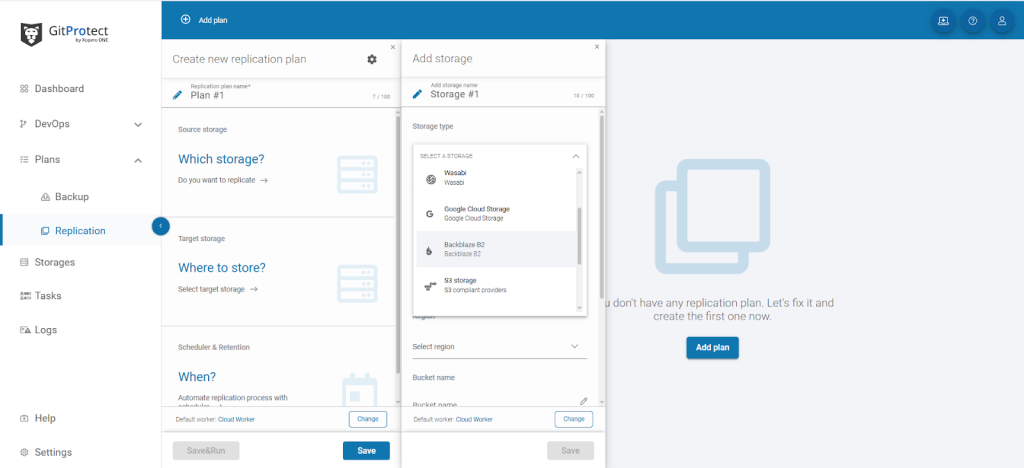
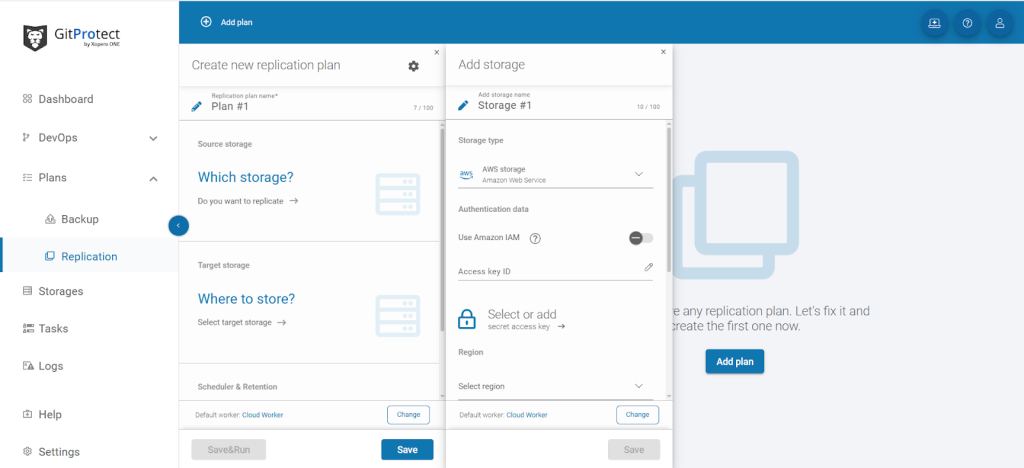
Native Jira backups lack cross-tool consistency and legal-grade retention. GitProtect.io fills the gap by treating Jira as part of the DevOps pipeline (not just a standalone database). For teams that already back up Git repos with GitProtect.io, adding Jira is a natural extension to protect the entire SDLC.
More than a safety net: metrics that matter
Ideally, each Jira admin could treat backup as a simple checkbox. However, the reality of business and IT clarifies that backups are a core component of system integrity and, as such, must be tied to SLA/OLA performance indicators. Among the latter, the most vital are:
- RPO (Recovery Point Objective)
Note that without API-level automation, the realistic RPO in Jira Cloud is 24 to 48 hours. With automation, the needed time is reduced to minutes.
- RTO (Recovery Time Objective)
Considering full schema recovery, the average RTO in the Data Center is 12 to 35 minutes. Of course, if you assume tested SQL restore paths. The measurement shrinks to even under 10 minutes with object-level restores and tested pipelines. - Integrity rate
Backup verification using checksums and dry-run imports yields an over 99.97% success rate when using automated validation scripts on staged environments.
Final notes
All the information above shows that protecting Jira Assets should be based on a disciplined approach to backup and recovery. That includes blending native tools and automation, followed by rigorous testing.
Jira administrators can mitigate risks and ensure operational continuity by (among others) implementing database and file system backups and validating recovery procedures. Various scripts, configurations, and strategies outlined here are a foundation for resilience, adaptable to instances of different scales and complexities.
However, given the limitations of the native Atlassian tools, using a third-party solution like GitProtect is a far more convenient, safe, and efficient approach. The software allows you to manage quickly all aspects of a reliable backup and disaster recovery process. That includes granular restore, automation without maintenance, and cross-tool dependency protection.
Let’s not forget unmatched RPO and RTO times with over 99,97% success rate. These give any Jira admin more confidence and a sound argument in security-related activities.
[FREE TRIAL] Ensure compliant DevOps backup and recovery of critical Jira data with a 14-day trial 🚀
[CUSTOM DEMO] Let’s talk about how backup & DR software for Jira can help you mitigate the risks



