


Git Clone Explained – How to Clone a Git Repository?
Git is the most popular version control system nowadays. It is a completely free open-source tool that allows you to e.g. work together on the development of source code. Linus Torvalds developed Git during the development of the Linux kernel, and its first version was released in 2005 and has been gaining popularity ever since. According to Stack Overflow’s 2023 survey, as many as 93% of programmers use Git version control system. The survey for 2020, for example, did not have such a question. Although, there was a question about “Collaboration Tools” and as many as 82.8% indicated GitHub, which is only one of several popular services using Git, so overall popularity is even higher.
I would like to add that many popular open-source projects use Git. It is enough to mention popular raster graphics editor GIMP, programming languages such as Perl, Ruby on Rails or the jQuery framework. Each of us can collaborate on this project using the Git VCS.
What is a Git clone?
In order to be able to work with Git, whether in open-source, commercial, or our own projects, we need to have a cloned repository (local or remote repositories) on our computer. Once the repository is cloned, you have offline access to the entire codebase, which allows you to work on the project without an internet connection. This local copy acts as the foundation for contributing to a project, enabling you to make and test changes on your machine before pushing them to the remote repository.
Also, cloning local or remote repos can make it easy to fix merge conflicts, manage files (add or remove them), and push larger commits. Cloning pulls down all repository data, including all file versions. Git is a distributed version control system, which means that each clone is an exact copy of the underlying git repo. In an extreme case, e.g. during a failure of the external remote server and the lack of backups, we can restore the entire existing repository on the basis of such a copy.
So what is a git clone? This is literally a clone. It makes a complete copy of the target repository, including all of its files, commit history, branches, and tags. At the same time, git clone is also the name of a specific function in Git. It allows us to make this copy (simply type git clone in a command line). Importantly, performing this operation is ‘one-time’, which means that after the first launch, we no longer need this function during further work.
We already know that git clone makes a local copy of the entire repository. Though, there still needs to be some external syncpoint done. This is the place where everyone connects their changes and downloads changes made by others from there. Thanks to this configuration, regardless of the number of people working on one project at the same time, each local copy is connected to this one, the so-called remote repository, and doesn’t need to know anything about the others. The clone function automatically connects our existing local repository with the remote one, which is also called origin. You can read more about Git clone here.
How to Clone a Git Repository (Step-by-Step)
Basic Git Clone
Before jumping into advanced Git clone options, here are the necessary steps on how to perform a standard clone:
- Find the repository URL: Go to the repository on GitHub, GitLab, Bitbucket, or another Git hosting service, and copy the clone URL (usually HTTPS or SSH).
- Open your terminal or command line: Navigate to the folder where you want the cloned project to reside.
- Run the clone command: Use the following command:
git clone https://github.com/user/repo.gitIn this case, you can create a local copy of the entire repository with all its history.
As an option, you can rename the local folder by adding a second parameter:
git clone https://github.com/user/repo.git my-folder-nameAdvanced Git Clone Options
1. Clone with filters
You can add filters to skip unnecessary data (e.g., tags or large blobs):
git clone <repo_address> <directory> --no-tags --filter=blob:noneWith it, you can save time and disk space on large projects.
2. Shallow clone
To avoid downloading the full commit history, use a shallow clone:
git clone --depth 1 <repo_address>With this option, you will download only the most recent snapshot of the repo.
3. Clone using HTTPS
If you’re cloning from a remote platform like GitHub, you can use:
git clone https://github.com/user/repo.gitVisual learner? Then, don’t read but watch our GitProtect Academy video to find out how to clone a repository (Psst, don’t forget to subscribe!)
How to Git clone a specific branch?
One of the parameters for the git clone function is –branch (or -b). By default, clone takes all branches and performs a checkout only on the main git branch. The above-mentioned parameter allows us to change it and perform a checkout for a particular remote branch that we specified. However, it won’t change the fact that Git will fetch all branches anyway. This is not what we would like to achieve in this case.
Imagine a repository that has three branches, the master being the main one. Clone operation with the –branch develop parameter will allow us to pull and checkout the developed specific branch, but what will happen to the other two? Check out the pictures below:

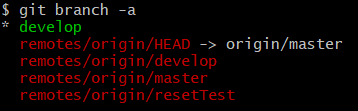
As you can see, all the branches were downloaded anyway. Let’s try to modify our git clone command in such a way as to clone a single branch only. Since Git 1.7.10 (and we currently have version 2.32.0 – released on the 6th of June, 2021) the clone operation in a git clone command has the –single-branch parameter. What does the documentation tell us about it?
“git clone” learned “–single-branch” option to limit cloning to a single branch (surprise!);
tags that do not point into the history of the branch are not fetched.”
So let’s check the operation in practice. We will copy the operation from the previous example, but this time we will add another parameter. Let’s see its effect…
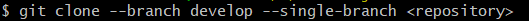
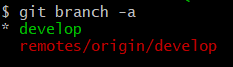
Done! This time we managed to clone a single branch only. Why do we need this? Sometimes the repository we are working on can be very extensive and we don’t need to download all branches. Both for reasons of saving memory and keeping order and avoiding chaos, such instruction can be useful and helpful for us.
Conclusion on how to clone a repository and how to clone a specific branch
Today we learned how to clone any local or remote repository and how to clone a specific branch in Git. Cloning a repository allows us to have more control over what we do, but it also has its consequences. In the beginning, I mentioned that a local copy of the existing git repository, in extreme cases, allows you to restore the project. So, each local clone works a bit like a backup of the base repository.
The problem appears when this copy contains only a single branch, then of course we do not have the entire remote repository and we must be aware of it. Proper backup is important and should never rely on local reproductions. Why? Because the parameters of the git clone function allow you to filter many items and we can never be sure of the differences between our and an external repo. I recommend using dedicated backup solutions like GitProtect.io to avoid surprises.
Next step, how to clone using HTTPS in git
[FREE TRIAL] Ensure compliant DevOps backup and recovery with a 14-day trial 🚀
[CUSTOM DEMO] Let’s talk about how backup & DR software for DevOps can help you mitigate the risks



