Git HEAD – Git HEAD reset and Git HEAD overwrite – what to do?
There is a great variety of DevOps tools that serve different purposes and uses. We benefit from them in a number of situations, but sometimes they still can cause some problems. Do you agree with this suggestion, don’t you?
After all, a tool only has certain characteristics and functionalities, but we are the ones who use it in some way or another. We are the ones who decide for which purposes to use a hammer – to break a window or put a nail into the wall. Let’s not blame the tools, but rather look at ourselves to see if we are using them correctly!
In the IT world, we use a variety of tools for our daily work, so let’s take this lesson to ourselves. It’s not the tool that can spoil the results of our work, but we are, when we use them in a wrong way. And that’s what this material is about – how managing Git commands we can get rid of the results of our work by carelessly using something called a HEAD.
Let’s dive into Git HEAD
Let’s first briefly discuss what a branch is in Git. How does it work? The ability to branch a project is crucial to modern Version Control Systems. Among other things, Git has gained immense popularity because it allows users to switch between different versions of a project very easily and quickly. This is a vital thing in modern projects.
The solution to this problem in Git deserves applause. The branch in Git does not track the entire version of the project, but only individual changes. If we change only one file in the project then the others are not saved again. Instead, Git tracks a reference to the previous version. To be even more precise, it is not the branch that holds such information, but the commits. The commits are the ones that contain any new, deleted, or edited files. They are permanent and immutable. Moreover, they create a linear history of the project, so we can roll back to any version of the file from the past.
And what does a branch have to do with it? This is where the cleverness of this solution reveals itself. Why? Because a branch simply points to a specific commit, for example, the latest commit on the main branch. Thus, the branch itself is just a simple little file, containing the SHA code of a particular commit. Changing of this pointer is very fast, because it doesn’t reload our entire project, but only jumps to another commit. This allows us to add or remove branches according to our desire. We can even have several branches pointing to the same commit! Why not? By the way, it’s quite common.
Git HEAD
And what is the HEAD itself? It’s a special indicator that shows the current master branch by default. The one you are currently on and what version of the project you see on the screen. Though, remember that there is only one HEAD indicator in the whole project!
So, a Git branch is a pointer to a commit, and HEAD is a pointer to a branch, that’s how we can think of it.
Displaying HEAD information
Well, let’s go further and explain how to check what HEAD is pointing to in our project. We can do it in many ways, for example, modern IDEs always mark a branch in a graphical way, in the CLI we can display our Git status and also graphically see where this special indicator is. But there is another way, which does not require our observation skills. We can simply look in the .git directory in our project and find the file named HEAD there. Or execute a simple command that will show us its contents:
cat .git/HEAD or
git rev-parse HEADThere we will find one line that can tell us which branch (or commit) the HEAD is currently pointing to, for example something like this:
ref: refs/heads/developGit reset HEAD
Well, we have already cleared out what a branch is, how it works, and what a HEAD is. And what does it give us? Let’s further explain the state we call “detached HEAD”. In short, it is a state in which our HEAD does not point to any existing branch, but directly to a given commit. This is not a wrong action, sometimes it is expected and we intentionally take such a step. However, we must remember that this leads to a high risk of losing a previous commit or some of them.
Let’s imagine a situation where, after executing one or more commits, we find that we want to roll back to the previous version and continue working from a new starting point. We can use the Git reset command for this:
git reset HEAD^or
git reset <commit hash>The above command rolls us back one commit backward (HEAD^) or to any indicated commit. This means that our HEAD points to the new location. There are several dangers associated with the Git reset command. The first is that this command allows us to change history, which is not allowed in Git. If we “delete” a commit already existing in an external git repository, we will not be able to perform a push operation, because of the inconsistency. Never modify an already existing commit history!
Though, it’s worth remembering that we must be careful with this command. Git reset command can work in 3 different ways: git reset –soft, git reset –mixed, and git reset –hard commands. Using one or another we can delete (or keep) changes from the working directory or staging area.
Git reset –soft HEAD
The purpose of the –soft reset command is to update the reference to a certain commit in the HEAD, where the most recent commit is located on your local system. For example, if you notice that some file to a commit is missing (maybe you forgot to add it), you can use the –soft command:
git reset --soft HEAD~nThis soft reset command will allow you to move back to the specific commit. Under n, we mean specific reference. For example, if you want to get back to the last commit, you can use git reset –soft HEAD~1.
git reset --soft <commit ID>With the following command, you can move back to the HEAD with the <commit ID>.
Git reset –mixed
Being a default argument for git reset, git reset –mixed can have two impacts. They are:
- uncommitting all the changes,
- unstaging all the changes.
You can use this command, for example, if you accidentally added a file and you need to remove it.
Git rest –hard
You should remember that git reset –hard is a potentially dangerous command. If you use this command on a certain commit, it forces the HEAD to go back to that specific commit. Moreover, it deletes everything after that commit and permanently discards uncommitted changes, and updates the working directory, index, and HEAD.
In contrast, ‘git checkout’ only updates the HEAD pointer without altering the current branch, making it a safer option for switching branches. To understand it more I recommend reading the article How to undo a commit in Git.
Git HEAD overwrite
But modifying the history (and all the implications of that) is just one part of the story. Let’s assume we’re only doing this on local changes, intentionally, and we know we’re not messing anything up, in terms of the commit history. Is there any other risk then? Of course. Though I must admit that this is a rather unusual situation, it is not completely rare.
If we use the Git reset command to roll back to a specific commit (to which no branch is pointing) then we will have the situation described earlier – the so-called “detached HEAD”. To reset the HEAD pointer to a specific commit, you can use the git reset HEAD command. From here, of course, we can make further changes and save them in new commits. At first glance, everything works normally, the changes have been added, the commit saved, we can even use the git log command and trace our new history.
However, there may be a problem when we need to switch to a certain branch for some reason. For example, we want to add the current version from develop to what we’ve just coded. We switch to the develop branch, download the new changes, if any, and… we don’t know how to get back to our just-written code, because we didn’t add any branch there. Well, we just lost some part of our work.
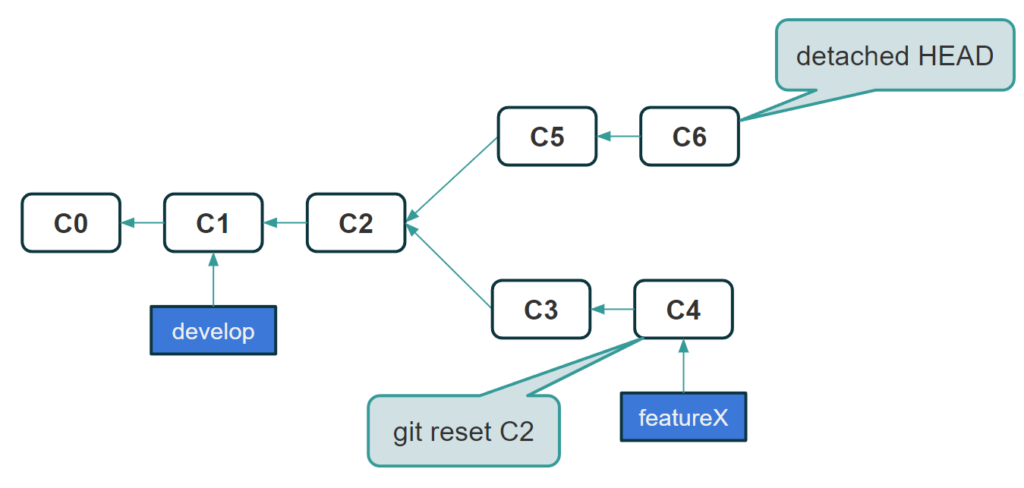
We can see it in the image below. Starting with the develop branch, we created a new branch – featureX, and then added 3 commits. However, we found that some changes needed to be rolled back and another solution is expected. The “git reset C2” operation rolled back our HEAD to commit C2, at the same time transitioning to a “detached HEAD” state. At this point, we made further changes but still remained in this state. When we switch to the develop branch, it is almost impossible to recover the changes contained in commits C5 and C6.
The importance of a backup
Overwriting can be a serious issue. There are a few more methods at your disposal – starting with the git revert command and so on. However, if you are interested in a more automatic approach – try a backup. A dedicated DevOps backup is a good option especially if you need comprehensive code protection – automatic backup/backup on demand, unlimited retention, disaster recovery, etc. Check our guide to find out more about the git backup best practices. And if you have only a handful repos to secure? Well, PRO solutions have also free tiers – with GitProtect you can backup up to 15 git repositories for free. Grab our app in the Marketplace and check it out yourself.
As I mentioned, this is a rather rare situation, mostly due to the programmer’s lack of attention. But after all, so-called human error is one of the main causes of our problems, so we should try to minimize it wherever possible. Maybe such a situation will not cause a catastrophe in our project, but let’s act here according to one of the lean principles – the pursuit of perfection. The company should find ways to get a little better all the time. So let’s implement it. Let’s take care of proper and regular backups to be prepared even for these rather rare situations, leading to data loss.
For this reason, you can organize your backup by yourself – delegate some developer of your team to write scripts, perform those backups, check their performance, and if it’s needed write a recovery script to restore the data. Though, from one side it’s time-consuming, and, from the other, ineffective, as it will distract your DevOps from their core duties.
On the other hand, you can build a backup strategy using third-party backup tools, like GitProtect.io. Will it benefit your development process? Let’s see, backup software can bring automation into your coding – all your data will be backed up according to your custom settings automatically, saving your DevOps time. Moreover, a comprehensive backup solution will guarantee your data to be accessible and recoverable from any point in time, which eliminates data losses in case of human errors or other events of failure.
[FREE TRIAL] Ensure compliant DevOps backup and recovery with a 14-day trial🚀
[CUSTOM DEMO] Let’s talk about how backup & DR software for DevOps stack can help you mitigate the risks