


Turning Data Disaster into Strategy: Lessons to Learn from Malware Attacks
Malware, as one of many cyber threats, is not some random annoyance. Yet, there is nothing polite about it. It bypasses your firewall and establishes itself in your system. Then, escalated privileges are granted, and processes are killed. If you are particularly unlucky, malware encrypts your core and sticks around like a parasite in the CI/CD. So, it’s not about chaos but orchestration. That means you’re forgetting about something.
Organizations don’t fall to zero-day wizardry. They bleed out from misconfiguration, neglected credentials, as well as assumptions about what’s “good enough.” To those responsible for continuity, the most urgent shift isn’t only technological but also psychological, informed by business impact analysis for key stakeholders. After all, security is about preparing for the moment when a data breach response is needed.
The aerospace data breach. When your CI/CD turns against you
In 2024, during the Spring months, a European aerospace company faced significant delays when launching two critical satellite components. The process was quietly postponed. Officially, the problem was described as “supply chain friction.”
But the story was quite different. Behind the problem was a sophisticated malware intrusion. Codename: HellCat.
| Aspect | Details |
| Name | HellCat |
| Type | Ransomware-as-a-Service (RaaS) |
| First detected | 2024 |
| Primary affiliates | “Rey”, “Hikkl-Chan”, “APTS”, and others (distributed affiliate network) |
| Target sectors | Aerospace, Energy, Government, Education, Automotive, Telecommunications |
| Attack motive | Double extortion (data theft + encryption) and sabotage |
| Initial access vectors | – Spear-phishing (PowerShell) – Vulnerable services (Jira, PAN-OS, Jenkins) – Credential stuffing from infostealers (e.g., Raccoon) |
| Persistence mechanism | Registry Run keys (HKCU) and memory-resident implants |
| Payload type | Memory-resident reflective loader + AES/RSA encryptor |
| Primary languages | PowerShell (staging), GoLang (C2), C++ (core encryptor) |
| Encryption algorithm | AES-CBC file encryption with RSA-4096 key wrapping |
| File extensions | Preserved – files remain named as original (no added suffix) |
| Code obfuscation | – Encoded PowerShell – AMSI patching – Reflective loading using VirtualAlloc, NtQueueApcThread |
| Command and control (C2) | – HTTPS with ECDHE – Onion services (e.g., hellcakbsz…35.onion) – Backup: DNS-over-HTTPS fallback |
| Data exfiltration | Before encryption, via HTTPS POST (40+ GB in some cases) |
The attack started with a detail small enough to ignore – an old Jenkins credential. It belonged to a contractor who’d been gone for months. The account, however, hadn’t been decommissioned adequately due to a botched offboarding policy.
Worse, it had (remote) access to a GitLab runner exposed behind a misconfigured internal proxy. Service accounts, as usual, were exempt from MFA. “No one uses them anyway,” someone once said, and also ignored the importance of monitoring network traffic.
In other words, HellCat didn’t need brute force. It walked in, bypassing access management and data security.
From there, it went to work. Pipelines were quietly modified. PowerShell loaders crept into YAML configs. Lateral movement across the built infrastructure took mere minutes, made easier by identical root SSH keys. Within 12 minutes, backup agents were down. And storage volumes? Unmounted and soon after, wiped or overwritten.
The attackers didn’t just hit infrastructure. They knew it and moved like insiders, leveraging the DevOps workflow itself to do the damage. It wasn’t a smash-and-grab, but a rebuild in reverse. In other words, what made the breach devastating wasn’t just the encryption of build artifacts or the exfiltration of sensitive data. It was the attacker’s understanding of DevOps tooling. So, instead of breaking the operating system(s), they used the affected system(s).
| Aspect | Details |
| Backup targeting | Scans for .bak, .vhdx, .vmdk, and mapped NAS; deletes or overwrites snapshots |
| Persistence duration | Stealthy implants—dwell time ranges from minutes to multiple weeks (esp. in DevOps environments) |
| Ransom notes | Vary by affiliate; often include taunts (e.g., $125,000 “in baguettes”) |
| Affiliated tools | – SliverC2 (custom encrypted implants) – Netscan – Netcat – PsExec – Modified Mimikatz |
| Infrastructure reuse | 92% code overlap with the “Morpheus” ransomware family |
| Notable CVEs exploited | CVE‑2024‑0012 (Jira RCE), CVE‑2024‑9474 (PAN‑OS pre-auth RCE), various GitLab misconfigurations |
| Forensic fingerprint | Reflective code load chains, AMSI patch detection, base64 payload stages, and shellcode in stager.woff |
| SIEM detection patterns | Sigma rules for AMSI bypass, virtual memory allocation, abnormal registry keys, and encrypted C2 over uncommon ports |
Restoration wasn’t an option. Mirrored Git repos were overwritten with corrupted payloads. “Offline backups” had been kept hot and were already infected. And disaster recovery strategy, immutable backup data policies? Still in draft form. Planned but not deployed or tested.
The damage tallied over €12 million, but that was just the financial loss related to operational technology. The engineering team, the architects, and the ops crew – they all knew the bigger hit was philosophical. They had trusted the system would hold during normal business operations. It didn’t, so “technical shame” ran deeper.
| Aspect | Details |
| Behavioral evasion | – Delayed execution to avoid the sandbox – Anti-debug via timing/sleep detection |
| Notable victims | Schneider Electric, Jaguar Land Rover, Telefónica, Israel Knesset, Orange Romania, Tanzania CBE, unnamed US university |
| Recovery difficulty | High – due to backup tampering, CI/CD logic corruption, credential poisoning |
| Defensive recommendations | – Patch exposed services – Least privilege enforcement for pipelines – Immutable, off-network backup – Memory-level EDR logging |
| (Possible) backup countermeasure | GitProtect: The system provides immutable, metadata-rich, cross-platform backup with point-in-time restores and automated DR |
🎓 Lesson 1.
When automation lacks access boundaries, it becomes the fastest way to destroy yourself. CI/CD must be treated as an attack vector – not a sacred cow.
Fintech’s slow death. Pipelines as parasites – no malware recovery
Later, in 2024, cloud services became a target. HellCat evolved, yet the change was subtle. A promising fintech startup discovered it not through a breach notice related to cloud security, but a code audit prompted by a weird staging bug.
For several weeks, an elusive attacker was quietly slipping delicate modifications into deploy.yml files scattered across various GitHub repositories. These changes were tiny, thus easily overlooked. It was one small tweak in one place and a slight adjustment to a variable in another.
The malware acted as if it were “curious” (not your typical ransomware). HellCat changed (rewrote) specific if conditions in YAML files across 13 repositories. Each edit covertly directed towards an AWS-hosted binary. On the surface, the binary appeared harmless: a routine Golang metrics collector verified by its cryptographic hash. Yet, it targeted sensitive data. As always, appearances can be deceiving.
Beneath the surface, the binary concealed a sophisticated modular shell loader. It extracted sensitive information by camouflaging its encrypted data traffic as benign Prometheus metrics streams. That’s not typical ransomware. HellCat’s objective wasn’t encryption but espionage.
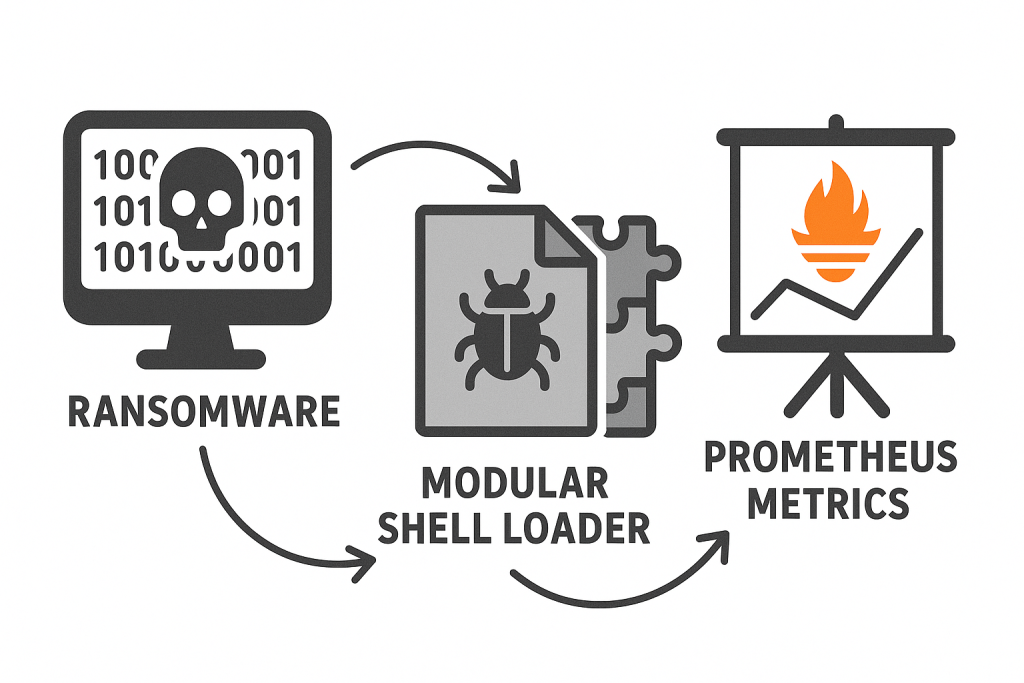
The critical data breach originated from an orphaned Bitbucket credential tied to a long-gone contractor, which had been left carelessly active. It was quiet. After gaining access, the attacker dug deep, embedding persistent backdoors into the Terraform scripts.
Azure tokens were (systematically) extracted. Kubernetes manifests were meticulously edited. The process involved undocumented ports. All these were unnoticed by standard monitoring protocols.
Any cyber incident response when disaster strikes?
When the incident response unit finally became aware of the infiltration, the damage was extensive. The intruder already got access to critical production databases. The data was compromised, encrypted, or not.
Interestingly, the only sign of an attack was that CI jobs took slightly longer. Additionally, test metrics wouldn’t align with production data. Devs blamed GitHub lag. 78 days in HellCat had full credentials to every environment.
The impact exceeded IT infrastructure – trust crumbled overnight. Two major clients withdrew their agreements. Then they distanced themselves from the unfolding crisis. Additionally, a prominent investor has cancelled the Series C financing indefinitely.
The company insisted on an exhaustive security evaluation and recovery costs assessment (e.g., by managed security service providers) before moving forward.
Losses were estimated at over $4.2 million. It took nearly 20 weeks of engineering (organizational) resources redirected solely towards containment and recovery.
A taste of ransomware
After HellCat stole 40GB of sensitive data from Schneider Electric (a French energy company) critical system, it demanded a part of the ransom – $125,00 to be paid in… baguettes!
Now, that’s what you call good taste. After all, more than one law enforcement agency is associated with donuts. Business losses, however, remain harbingers of financial diabetes.
🎓 Lesson 2.
The myth that “slow breaches cause less damage” is just that – a myth. Stealthier malware is not weaker. It’s strategic.
Radiology problem. Stored data with no disaster recovery plan
One seemingly quiet evening in late 2023, a Florida-based medical facility found itself schooled in the harsh realities of cybersecurity. They discovered that redundancy without isolation is a ticking time bomb, much like in natural disasters.
The villain of the night was MedusaLocker. It’s not exactly groundbreaking malware, but dangerously effective when paired with common oversight. The attack began innocuously enough. An unpatched Remote Desktop Protocol (RDP) endpoint on a radiology department workstation was left exposed. As such, it became a soft entry point. MedusaLocker quietly crept in.
Once breached, open Server Message Block (SMB) shares were quickly exploited. The attacker aimed to eliminate local data backups first (recovery point), then disrupt network connections, and then create chaos in the attached storage.
Initial command executed (an example):
vssadmin delete shadows /all /quietIn mere moments, Volume Shadow Copies were erased, stripping the facility of quick rollback capabilities. Next, MedusaLocker targeted critical backup files. Standard targets include .bak, .vhdx,
and .vmdk extensions (an example):
forfiles /p D:\Backups /s /m *.bak /c "cmd /c del @file"
forfiles /p D:\VMs /s /m *.vhdx /c "cmd /c del @file"However, this wasn’t a typical smash-and-grab ransomware attack deployment. Timing, in this scenario, was everything for the integrity of critical systems. The attackers chose theirs strategically.
The ransomware attack triggered at exactly 2:14 AM. It was precisely during the hospital’s scheduled nightly backup process (data protection), which had commenced just 14 minutes earlier. Backup operations were mid-write, snapshotting active patient data and imaging records.
Such tactical timing allowed the malware to inject corruption directly into these partially written data backups. Every single night from that week became unusable, corrupted at the byte-level, undermining restoration and cyber incident response attempts completely.
Compounding the problem, the NAS – Network-Attached Storage (network devices) holding these compromised backups were directly mapped to the production environment. In a classic but catastrophic error, these critical devices featured:
- no encryption
- no write-once-read-many (WORM) immutability
- no air-gapped isolation.
Furthermore, the facility had never run simulations to test its backup strategy against ransomware-induced Input/Output (I/O) anomalies.
Business impact analysis. Business continuity damage
The result was predictable (in a bad way). Radiology services plummeted into operational darkness, remaining offline for nearly six grueling days. Patients requiring critical imaging were diverted. Surgeries relying on timely radiological assessments were postponed indefinitely.
In short, patient care outcomes deteriorated rapidly (affecting all health and human services).

The financial aftermath was equally punishing. Regulatory bodies, particularly the Health Insurance Portability and Accountability Act (HIPAA) oversight committee, imposed steep fines exceeding $1.5 million.
What’s more, the hospital became entangled in multiple patient-driven lawsuits alleging negligence, resulting in significant reputational damage (including no proper disaster recovery procedures).
Within three months, the hospital’s administrative ranks felt the aftershock. The senior executives tendered their resignations, acknowledging the oversight and accountability failures that had set the stage for MedusaLocker’s devastating strike.
The case highlighted a simple yet often overlooked truth. Backups are not enough. If the latter lacks segmentation – immutable snapshots, encryption, and rigorous anomaly testing – redundancy quickly transforms from a safety net to a liability.
| Failure point | Consequence | GitProtect capability |
| Unpatched RDP endpoint; no MFA | Initial breach via weak perimeter | GitProtect is agentless – no endpoint exposure; supports integration with SSO/MFAbrai |
| Open SMB shares; no (restrict) access control | Rapid lateral movement; backup access compromised | Role-based access control (RBAC) and scoped access policies (privileged access management) |
| No snapshot immutability (no WORM protection) | Backups overwritten or deleted by an attacker | Immutable, WORM-compliant backup storage support |
| Backups corrupted mid-write (no I/O anomaly detection) | All backups during the attack window are unusable | Smart scheduling with backup validation and ransomware-resistant architecture |
| No air-gapped or isolated storage (NAS mapped directly to production) | Ransomware reached and destroyed backups | Air-gapped backups via cloud destinations with object lock and cross-region redundancy |
| No encryption (data at rest and in transit is vulnerable) | Patient data exposed; HIPAA fines and lawsuits | End-to-end encryption (AES-256), zero-trust security model |
| No disaster recovery procedures testing (no simulations run) | Six days of downtime; halted surgeries and care | Disaster Recovery as a Service (DRaaS) with scheduled testing and one-click restore |
| Administrative failure; no accountability or escalation plan | Executive resignations; reputational collapse | Automated backup reporting, compliance-ready logs, and an alerting system |
🎓 Lesson 3.
If your backups are on the same blast radius as your production system, you’re not planning recovery – you’re rehearsing failure.
The broader pattern. A liability in the disaster recovery process
Considering that DevOps now defines operational DNA, infrastructure is no longer just code. It’s a liability surface. Especially, when:
- repos contain deployment keys
- pipelines hide tokens
- metadata carries IP.
Workflows run with more privileges than any user would ever be allowed. And yet, most backup strategies still treat source code like static text. This blind spot is systemic, and organizations need to limit access to prevent exploitation.
For sure, GitHub repositories are versioned. But what about GitHub Actions? Going further, what about automation rules, configurations, and user mapping?
The fact is that GitHub Actions often run with broader permissions than any user would typically have. Secrets aren’t versioned, and branch protections are lost upon reset. Unfortunately, most backup systems treat repositories like static ZIP files. And that’s the blind spot.
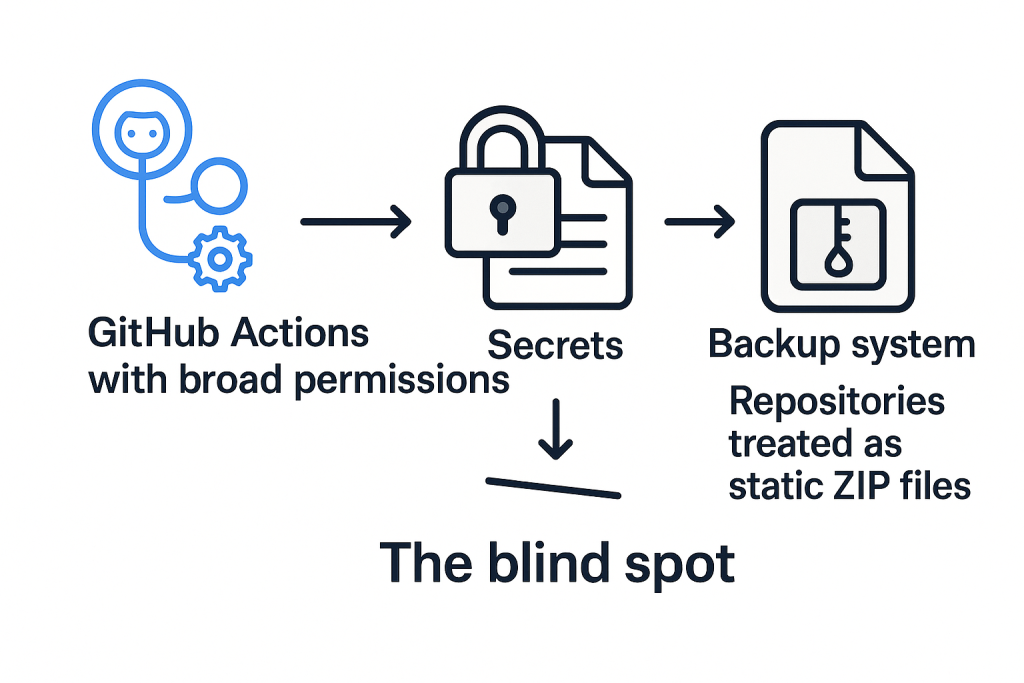
Such solutions ignore the need to address critical vulnerabilities:
- Actions
- webhooks
- secrets (including strict access controls, access privileges, authorized users, network segmentation with virtual private networks)
- audit logs.
All of these are part of the logic and identity fabric of CI/CD structures. And it gets worse with Jira or Azure DevOps. Examining automation rules, pipeline configurations, service connections, and user mappings reveals that deleting any of these elements can cause workflows to collapse (with no rollback).
That shapes modern DevOps’ need for stateful and logic-aware backups, rather than snapshots of code. Otherwise, it’s like restoring a skeleton with no brain, nerves, and thus, memory.
🎓 Lesson 4.
Malware authors already understand this structure, often bypassing relevant contact information. It’s time recovery architects did too and properly notified affected individuals.
From postmortem to playbook. Resilience in practice
IBM’s 2024 Cost of a Data Breach Report showed that the difference between a recovery and a disaster is rehearsal. Companies without a tested incident response plan(s) and a solid disaster recovery strategy incurred an average of $1.76 million more in costs. Those who treated backup as a security control walked away faster, with fewer scars.
However, the hard truth is that most so-called backup strategies are not strategies at all. They’re storage routines – schedulers with a retention script. If so, then what defines a modern backup strategy? It’s not about a trivial approach, meaning:
- number of copies made
- where the copies reside
- short-time retention rules.
A well-thought-out and properly designed strategy provides many more crucial elements.
| Immutable backups | These are not just for files, but for the entire logical state of the system. That includes:metadataworkflowssecretspoliciesautomations and more.If the company’s CI/CD pipeline logic is gone, then restoring code is meaningless. |
| Ransomware-aware anomaly detection | A pattern-matching behavior against known breach signatures, file entropy shifts, or sudden deletion events is vital for data security and safety. |
| Decoupled infrastructure | No co-hosting of backup agents on production nodes. If the breach hits the environment (and its file system), backups must live outside its blast radius. |
| Cross-platform orchestration | GitHub, GitLab, Azure DevOps, Bitbucket, as well as Jira are all part of the company’s production logic. Backups must span these silos, not ignore them. |
| Automated disaster recovery (DR) validation | Restores are not hope-based. Business provides it daily, in a sandbox. There is no backup plan if recovery isn’t tested under live conditions. It’s only a false sense of security. |
A simple conclusion is: storage is just the vessel. The real strategy is how fast you can rebuild logic, reclaim access, and ensure data recovery – under fire. Anything less is barely an illusion of safety.
GitProtect. When data backups aren’t a feature but architecture
In every case discussed so far, the common thread wasn’t a lack of backups. It was ineffective backups. The kinds that look good in a dashboard but collapse under malware logic. This is where GitProtect may provide a few solutions. Not as a mere “backup tool,” but as an infrastructure fail-safe. It doesn’t just save data. It saves orchestration.
GitProtect delivers:
- full backup of GitHub, GitLab, Bitbucket, Azure DevOps, and Jira. That includes metadata, permissions, automations, logic, and other elements
- immutable and encrypted cross-region storage with zero-trust key handling
- instant restore validation in isolated environments
- alerting and logging integrated with SIEM/SOAR pipelines
- compliance-ready frameworks aligned with ISO 27001, NIS2, SOC 2, GDPR, and others.
When CI/CD, IaC, and ITSM fail, GitProtect restores not just data, but also business continuity. And that’s the difference between companies that write press releases and companies that issue invoices.

🎓 Lesson 5.
A real data backup doesn’t ask “What files do you need?” but rather “What critical assets must be prioritized?” and “How fast do you want your company back?”
Disaster recovery strategy. Audit what’s left after a data breach
After every disaster strike (data breach), someone flips open the compliance binder and mutters, “We passed this six months ago.” But HellCat doesn’t care. It’s not looking for failed audits. It’s looking for operational blind spots:
- exposed service accounts
- unmonitored automations
- backups mounted like production shares
- pipelines with root-level access and other critical services.
By the time the alert triggers – if it does – your source control is already poisoned. Your Jira logic is shredded, and the backups are either compromised or untested. The illusion of readiness collapses fast when the only thing left is a recovery plan no one has ever run under pressure.
HellCat succeeds not because it’s novel, but because most environments assume safety by default. It leverages gaps, including old credentials, forgotten staging instances, and CI/CD pipelines granted “god-mode” permissions.
The note left by the HellCat attackers. Source: tripwire.com
When it strikes, your compliance is not the case. The core question is whether your existing systems can be rebuilt quickly, offline, and without guesswork. That also underlines the need for security awareness training during normal operations. At least for the sake of the recovery point objective (RPO) and recovery time objective (RTO).
This is why the topic related to “are we covered” concerns should focus on what survived, rather than green dashboards or policy binders. Equally important is what can be rebuilt. Because if the disaster recovery process and plan can’t survive HellCat or MedusaLocker, it will inevitably attract the scrutiny of a law enforcement agency.
The latter will entail a detailed dive into risk management, internet access, security breaches (and stolen data), as well as ongoing processes, cloud providers, cloud services, and significant risks. They will be aiming to address vulnerabilities and determine their cause.
The question is whether maintaining business continuity and normal business operations will still be possible.
[FREE TRIAL] Ensure compliant backup and recovery of critical DevOps data with a 14-day trial 🚀
[CUSTOM DEMO] Let’s talk about how DevOps backup & DR software can help you mitigate the risks



