


Immutable Storage: The Backbone of Modern DevOps Resilience
Nearly 94% of ransomware attacks initially targeted backups. Mainly to encrypt them. That means, for SaaS and DevOps platforms, backup alone no longer solves the problem of data protection. A copy of backup data is worthless if it can be altered (corrupted) or blocked when you need it most. Besides, integrity has to be provable and data recovery certain. That’s why immutable storage is a baseline requirement for resilience in modern IT architectures.
As a reminder, immutable storage typically adheres to the write-once, read-many (WORM) principle. Data is stored, but it can’t be edited or erased until the retention clock expires. Crucially, such a safeguard isn’t just a checkbox inside the backup software. It sits at the storage layer itself. Even a superuser can’t bypass access control without breaking compliance controls and setting off immutable lock violation alerts.
For Jira admins and IT decision-makers, immutability marks the line between a service disruption (that can be recovered from) and disaster scenarios that render the system unusable (service outage). For CISOs, it plays a different role. It’s the evidence that the organization can withstand deliberate sabotage on data security or a tailored ransomware (cyber threats in general), without losing control of its critical data (access controls or access management).
Immutability. The technical reality in data security
SaaS runs on the Shared Responsibility Model (SRM). And it may be surprising that many IT professionals still aren’t aware of that technology fact. Under SRM, the service provider keeps the lights on and offers basic redundancy. However, the actual data protection falls to the customer once the retention window closes.
Picture a Jira automation rule gone rogue, wiping out 50,000 issues in minutes. Or a stolen API token spreading malicious edits across files and projects. The vendor might step in, but they won’t guarantee the state you expect. And even if they try, recovery is often partial at best.
Immutable storage eliminates one of the biggest failure multipliers: backup compromise. Advanced ransomware doesn’t just affect production but can also result in unauthorized changes. It hunts the backup first. Attackers use stolen privileged accounts to walk through cloud object storage, replacing clean snapshots with encrypted junk.
That way, every recovery point is poisoned before the real strike begins. Immutability breaks that chain. Once written, data is locked. The storage layer itself refuses any write or delete command that doesn’t belong to the original creation.
Let’s say it again:
Nearly 94% of ransomware attacks went after backups first.
2024 Sophos State of Ransomware Report.
Where immutability is absent, recovery drags on. Organizations that don’t utilize immutability experience 2.8 times longer mean time to recovery (MTTR). At the same time, delays and incident costs rise proportionally.
Resilience You Can Trust: Cybersecurity and Data Integrity
Looking at immutability from behind the curtain. Here, the main idea is to predict the probability of unrecoverable loss. To be more specific, it’s a joint probability that both production and backup fail in the same period.
Pu = Pc × Pb
Pc represents the probability that production data is compromised in a given year (time period). As for Pb, it pertains to the probability that backups are also compromised during the same period. In other words, the chance of losing everything depends on both elements. For example, without immutability, Pb is greater than zero, which instantly affects the unrecoverable loss (Pu).
Following this simple formula, it’s immediately clear that when immutability is enforced, backups can no longer be overwritten or deleted, and Pb trends towards zero. That also drives the probability of catastrophic data loss (Pu) close to zero as well.
And it isn’t just theoretical. Available incident reports repeatedly show that WORM-protected backups are often the only intact recovery source after a ransomware strike.
For instance, assume that production data has a 15% annual risk of compromise (Pc=0.15). If backups (in the absence of immutability) carry a 20% risk of being corrupted too (Pb=0.20), then the overall probability of unrecoverable loss equals 0.03.
Pu = 0.15 × 0.20 = 0.03
That’s a 3% chance every year of losing all recoverability. Over five years, the compounded probability climbs to 14%. And that’s not a rounding error but a business-ending event waiting to happen. However, the introduction of immutability shifts the numbers drastically. If Pb falls to 0.001 (0.1%), then Pu equals 0.00015 (0.015%).
Pu = 0.15 × 0.001 = 0.00015
In practice, that’s roughly a 200 times reduction in risk. From a CISO’s perspective, that’s the difference between explaining a short outage in a board meeting and explaining why the company no longer exists.
Statistics show that after a significant data loss, 60% of businesses will shut down within 3 to 5 years. For smaller businesses, it’s 6 months.
WORM Compliance: Strengthening Governance and Data Protection
Following all the information so far, it’s time to state the trivial. WORM-compliant storage isn’t just a user data security “nice-to-have.” Obviously, it’s embedded directly into law and regulations.
For instance, financial services usually fall under SEC Rule 17a-4(f). It requires certain records to be kept in a non-rewritable, non-erasable format. Besides, FINRA Rule 4511 imposes similar demands. It mandates immutable retention for customer and transaction records.
In healthcare, the HIPAA Security Rule requires organizations to maintain the integrity of ePHI, a standard that immutability fulfills by ensuring data cannot be altered once it is written.
Going further, even the privacy frameworks, such as the GDPR’s Article 32, point to the same principle. The requirements here are both integrity and availability as part of risk management.
On the other hand, cloud vendors have translated these mandates into concrete features, for example:
- AWS S3 Object Lock
- Azure Blob Storage Immutability Policy
- Google Cloud Object Lock
When activated, these locks enforce WORM behavior at the storage layer itself. That entails no write, no overwrite, no delete rules. Not until the retention period runs out, whether that’s 30 days or several years.
Considering Jira administrators, this translates into practical resilience. Even if a schema in Jira Service Management is accidentally purged, or a bulk issue transition mangles thousands of records, the historical dataset remains untouched and verifiable.
The same applies to major Git-based solutions, including Azure DevOps, as per their own architecture and technical specifications.
Looking from the CISO perspective, WORM-compliant storage is a proof of custody (not just a safeguard). It demonstrates to regulators and auditors that once a backup was written, it remained unchanged. No insider could tamper with it. No SaaS vendor could quietly adjust it. Not even the storage provider itself could alter a single byte.
The multi-cloud factor. Data integrity and data availability
Immutability addresses data integrity but not data availability. A backup object may be locked in a WORM state. And yet, if it resides in a single provider, it inherits that provider’s entire failure domain. That includes:
- outages
- API regressions
- control plane bugs
- jurisdictional exposure.
That being said, immutability prevents corruption, but it doesn’t remove dependency. Multi-cloud replication closes that by introducing independence at the storage layer. That entails two forms of diversification (both may occur).
Operational independence
Think of a provider-specific incident, like an S3 region-wide outage, a misplaced IAM policy update, or transient API throttling. It’s contained within that provider’s failure domain. Replication across independent clouds provides domain separation. So, what fails in one doesn’t automatically contaminate the other, assuming they are air gapped. The latter works assuming replication is asynchronous and integrity-verified. e.g.:
- SHA-256 object hashing
- Merkle tree audits
- version consistency checks.
The key here is that fault isolation reduces the “blast radius.” Failures in one control plane cannot propagate into a secondary provider’s stack. Of course, the mentioned failures can be, for instance:
- access misconfigurations
- API throttling policies
- degraded metadata services.
However, the described separation isn’t absolute – correlated failure modes still exist.
Global DNS misconfiguration
If a replication relies on a single DNS namespace (e.g., Route53), a poisoned DNS entry could redirect or block replication traffic across providers. Mitigation here requires dual independent DNS resolvers and mutual TLS verification.
BGP hijacking
A routing attack can intercept replication flows at the network layer. Prevention entails signed route validation (RPKI) and provider-side transport encryption.
Federated identity compromise
If both clouds use the same IdP for authentication (e.g., Azure AD, Okta), an identity compromise could grant attackers access to both replicas at the same time. To avoid that, admins need to:
- enforce identity separation
- distinct IAM policies
- establish hardware-rooted MFA (Multi-Factor Authentication) at each provider.
Cross-provider API supply chain attack
In a situation where replication tooling itself is compromised (e.g., CI/CD pipeline injection), both replicas can be poisoned simultaneously. A proper and secure countermeasure should include:
- signed binaries
- attestation frameworks
- pipeline isolation.
The architecture goal is not to eliminate every correlated failure. That’s not possible. Instead, the design reduces probability mass in shared failure domains until the residual risk is smaller than the enterprise’s acceptable loss threshold. In probabilistic terms, the conditional independence assumption holds for most events:
Pdual failure ≈ P(A) × P(B)
That is, except in cases of correlated global risks (DNS, IdP, supply chain). These must be modeled separately. By introducing asynchrony and provider diversity, multi-cloud immutable replication transforms catastrophic, system-wide failure modes into isolated, low-probability edge cases.
In the baseline model above, the assumed independence (Pmulti) involves probabilities – P(A) and P(B) – of provider-specific failures, such as outage, data corruption, or misconfiguration. That gives the clean “near-zero” probabilities.
However, correlated risks break independence. Consider federated identity compromise as an example. If both providers are tied to the same IdP, a successful compromise could grant access to both environments. For instance:
| Probability of production compromise in a given year: Pc = 0.15 (15%) | Probability of provider-specific backup compromise(independent failure):Pb = 0.005 (0.5%) | Probability of correlated IdP compromise affecting both providers:Pid = 0.002 (0.2%) |
Without considering correlated risk, the probability of unrecoverable loss in a multi-cloud setup would be:
Pu = Pc × (Pb)2 = 0.15 × (0.005)2 = 3.75 × 10-6 (0.000375%)
And that’s definitely a small number. But when the correlated IdP risk is added, the total probability of unrecoverable loss in a multi-cloud setup becomes:
Pu(total) = Pu + (Pc × Pid) = 3.75 × 10-6 + (0.15 × 0.002) ≈ 0.00030375 (0.0305%)
Therefore, a correlated risk with just a 0.2% probability significantly outperforms the “independent” model. That is roughly 80 times higher outcome: from almost 0.0004% to over 0.03%.
A pinch of interpretation
For architects and CISOs, this changes the calculations. Independent multi-cloud replication gives them a near-zero probability of catastrophic loss. However, if correlated risks (such as federated identity) aren’t addressed, they dominate the residual probability mass.
The mitigation process isn’t just theoretical here. It demands:
- identity isolation per provider
- hardware-rooted MFA
- distinct IAM policies.
These should ensure that one credential system cannot simultaneously access both clouds. Once the correlation is broken, the model reverts to the near-zero risk level.

Jurisdictional independence
Legal derivatives, such as subpoenas, seizure warrants, or compliance mandates, are subject to jurisdictional bounds. A U.S. subpoena can compel AWS in Virginia to produce or freeze data, but it has no legal reach into an immutable replica held by Azure in Frankfurt (Germany). Similarly, GDPR Article 48 can restrict transfers of EU personal data but cannot force the deletion of a backup stored in Google Cloud’s U.S. regions.
Such a segmentation is measurable (e.g., for CISOs). Suppose the probability of a regulatory enforcement event that could freeze access to data stored in a single jurisdiction is Pr=0.02 (2%) annually. Now, assume the probability of operational disruption (outage or control-plane fault) at a major provider is Po=0.005 (0.5%).
If backups are kept only within one (single) cloud, the combined probability of data inaccessibility is roughly:
Psingle = Pr + Po = 0.025 (2.5%)
Replicating to a second, legally and operationally independent provider transforms the calculation. The probability of simultaneous legal and operational failure across two distinct providers becomes:
Pmulti = (Pr × Pr) + (Po × Po) ≈ 0.000425 (0.0425%)
In total, that’s nearly a 60 times reduction in annualized (yearly) exposure.
It can translate into expected loss. When the business impact of unrecoverable data inaccessibility (lost revenue, fines, remediation) is modeled at $10 million, then:
Single-cloud exposure: $10M x 0.025 = $250,000 expected loss (annualized)
Multi-cloud exposure: $10M x 0.000425 = $4,250 expected loss (annualized)
The $245,000 in annualized risk avoided becomes the governance-level justification for multi-cloud immutable storage. It’s not only a technical safeguard but a means to recover and a quantifiable reduction in enterprise risk that can be presented in compliance reports and defended in board-level discussions.
Resilience variable as a part of an immutable backup
As was elaborated so far, multi-cloud immutable storage diversifies both operational (outages, service degradations) and legal (jurisdictional differences) risks. That allows IT decision-makers to express resilience as:
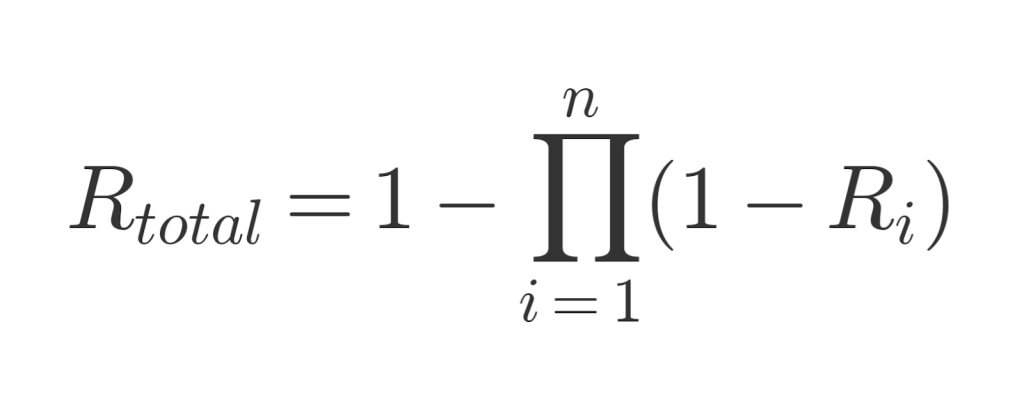
For instance, if each provider guarantees 99.95% object durability (Ri = 0.9995) and replication is to two independent clouds, then:
Rtotal = 1 – (1 – 0.0005)^2 ≈ 0.99999975
Such outcome approaches “six nines” durability, which is the standard of archival-grade storage.
For DevOps pipelines built on SaaS platforms like Jira Cloud, such mathematical resilience matters. It’s an assurance that even if a hyperscaler outage aligns with a ransomware event, recovery remains possible from the alternate immutable replica. At runtime, recovery procedures can simply recreate from the unaffected provider’s object store, bypassing the compromised one.
Such an architecture turns what would otherwise be a catastrophic single point of failure into a statistically negligible risk.
Measuring effectiveness. KPIs that matter
No doubt, CISOs and IT decision-makers need more hard numbers to prove immutability is doing its job and meeting the expected goals. They are helpful for the following KPIs, enabling the transformation of an architectural choice into measurable assurance.
Verified Restore Success Rate (VSRR)
This one counts the number of successful restore drills against the total number of attempts. In other words, it measures the proportion of restore drills that are completed successfully out of the total executed:
VSRR = (Successful restores / Total restore tests) x 100%
When immutability is in place, corruption is no longer a limiting factor. If so, then targets above 98% are achievable. If VSRR falls short, the failure signal typically points to process gaps, rather than the storage layer (integrity). The gaps may be:
- incomplete runbooks
- misconfigured IAM permissions
- (or) tooling that hasn’t been validated under load.
Immutable Retention SLA Adherence (IRSA)
Every backup should remain locked for the entire policy window. The expected value of this KPI is 100%. Any deviation constitutes a policy breach and may result in a compliance failure.
IRSA = (Backups under active immutable lock / Total backups in policy window) x 100%
To put it simply, IRSA measures whether backups remain locked throughout their defined retention period. Values other than 100% indicate either a misplaced policy or an administrative override that should not exist.
Cross-Cloud Integrity Divergence Rate (CIDR)
In a multi-cloud replication, identical objects should hash the same across providers. Target divergence is effectively zero (<0.0001%). That means even a single mismatch deserves forensic investigation.
CIDR = (Replica hash mismatches / Total replicated objects) x 100%
The CIDR is about evaluating whether replicas stored in different clouds remain identical. Any non-zero result signals replication corruption, API-level tampering, or underdetected bit-rot.
RPO Stability Index (RPOSI)
This KPI checks how closely actual recovery points align with the declared Recovery Point Objective (RPO). Immutability stabilizes the index by removing silent bit-rot and unnoticed tampering. The only drift comes from scheduling variance.
RPOSI = 1 – (|Actual RPO – Declared RPO| / Declared RPO)
Paraphrasing, it’s an assessment of the variance between scheduled RPO targets and actual practice.
ALE (Annualized Loss Expectancy) Delta
The goal here is to compare ALE before and after an immutable multi-cloud adoption. It quantifies direct financial impact.
ALE = ALEbefore- ALEafter
Clearly, a positive delta represents the monetary value of risk that has been avoided. For instance, from a CISO’s perspective, this is the bridge formula that translates architectural resilience into direct, board-level financial terms.
All presented KPIs turn immutability from an architectural claim into measurable proof. Each indicator provides CISOs and IT leaders with the evidence that resilience is not assumed, but verified.
Why your CISO cares beyond compliance (or should)
Finding the answer can be based on a simple observation. For a Jira admin, immutability is operational insurance. CISO views it as strategic risk compression.
Imutability redefines incident severity curves. Without it, specific attack vectors (such as backup overwrite, deepfake restore injection, and API-driven corruption) can escalate a breach from a recoverable event to an existential outage. With immutability, those same incidents degrade to operational disruptions.
The next thing is, it (immutability) improves the organization’s standing with cyber insurers. Underwriters increasingly require evidence of immutable backup retention and testing before offering favorable premiums.

Ultimately, it serves as a bridge for business continuity. If the SaaS vendor suffers a catastrophic outage or a legal seizure of its infrastructure, immutable (and multi-cloud) backups enable the recreation of an independent environment. Even if the vendor cannot or won’t cooperate.
GitProtect – the tool that matches SaaS and DevOps data resilience
Concepts like WORM storage and multi-cloud replication sound abstract, but they are deeply anchored in practice. For example, with GitProtect.io backup and Disaster Recovery software for the DevOps stack, organizations can meet all the necessary requirements regarding data protection, including keeping their data in an immutable storage. By default, companies can use GitProtect.io’s storage, an immutable one, to keep their backup copies there, ensuring data cannot be altered or deleted, safeguarding it against ransomware.
Moreover, GitProtect.io is a multi-storage system, so you can assign as many storage instances as your compliance or security requires. If you want to assign your own storage – cloud – any S3-compatible – or local, you can do it. Such an ability removes the single-provider bottleneck and meets resilience requirements that auditors increasingly demand.
Instead of treating backups as monolithic blobs, GitProtect allows you to granularly restore your critical data, like repository issue, project, etc.. That means shortened mean time to recovery (MTTR) – you don’t have to roll back an entire dataset when only a subset is needed.

For Jira administrators, this means day-to-day recoverability. A bulk issue deletion caused by an automation script doesn’t cause days of downtime. For CISOs, it creates an auditable trail of immutable, cross-cloud backups that withstand ransomware scenarios and align with compliance requirements.
The results are measurable. Organizations adopting immutable and multi-cloud backup with GitProtect can notice:
- improved verified restore success rates in quarterly drills
- zero failures of immutable retention adherence during audit checks
- RPOs holding steady within policy thresholds, even during vendor outages.
What matters most is that these outcomes are not theoretical. They can be verified with test restores, audit logs, and SLA reports. For instance, CISOs can take these to a board meeting or a regulator without resorting to assurances.
Takeaway
Considering all the above information, it’s easy to see that immutable storage isn’t a simple checkbox option in a backup platform’s settings. This is an intrinsic property of the storage medium, enforced at the hardware layer or object-storage API, that blocks alteration attempts at their root.
By ensuring that once data is written (and cannot be changed or erased) on data storage, it mathematically reduces the probability of unrecoverable loss to zero. When paired with multi-cloud replication, immutability extends beyond vendor claims. That means it becomes a measurable, auditable control aligned with compliance mandates and resilience engineering.
GitProtect is a solution that makes all immutable storage principles tangible. It applies WORM-compliant storage and distributes data across multiple providers. The system is verifying restores down to individual issues or assets. This way, it makes resilience a capability that can be demonstrated, audited, and relied upon when a SaaS or a DevOps system fails (full data recovery).
Before you go:
📚 Learn more about immutable backups and why they are essential for data security in DevOps
🔎 Find out the best practices to build backup for your critical DevOps and project management data
🛡️ Try GitProtect backup to make sure that your source code and metadata are protected
📅 Let’s talk about how backup & Disaster Recovery software for DevOps can help you mitigate the risks



