


Disaster Recovery Testing For DevOps
Editor’s note: This post is part of the GitProtect’s Master of Disaster series
Once we say Disaster Recovery, we imagine that if something goes wrong – unexpected deletion or other human error, ransomware attack, outage – we can restore our data immediately. But is it so in practice? Only if you have a reliable backup for your DevOps stack and a tested DR plan for every critical scenario.
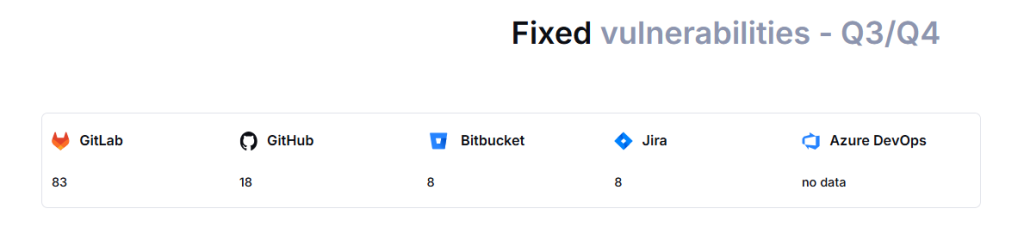
According to Backblaze’s report, only 42% of organizations that experienced data loss managed to restore all their data. How many threats are there for your critical DevOps, PM, or SaaS data? The 2024 DevOps Threats Unwrapped states that only in the second half of 2024, GitHub, GitLab, and Atlassian patched around 115 vulnerabilities of different severity, which might potentially lead to data loss.
Well, what do fast data recovery and resilience depend on? A few key factors:
🔹 A reliable and successful backup strategy, which includes regular, automated, and versioned backups that ensure that the data can be restored after a failure
🔹 Storage redundancy, for example, the possibility to replicate your backed-up data.
🔹 A well-documented and tested Disaster Recovery plan, which ensures a quick response and minimal downtime in case of an incident.
🔹 Security measures, including encryption, different levels of access controls, etc.
🔹 Testing and monitoring, as frequent recovery tests and continuous monitoring ensure that backups and disaster recovery strategies work as intended.
🔹 Compliance and governance, which includes adherence to industry regulations and ensures proper data handling and recovery policies.
Today, our focus is on Disaster Recovery testing. We will cover how often DevOps and project managers should have their Disaster Recovery tests done, what role backup plays there, and if there is a way to simplify the process of DR testing…
Disaster Recovery testing and Compliance Standards
No matter what industry your organization operates in, regulatory compliance is non-negotiable. Each sector, whether it’s healthcare, technology, finance, etc., comes with its own set of security compliance standards.
Most compliance frameworks, like SOC 2, ISO 27001, HIPAA, PCI DSS, GDPR, and NIS2, commonly require strong security and data protection strategies, including secure access controls, audit logging, backup and disaster recovery (including testing of backups and Disaster Recovery!), documented security policies, and incident response plans to ensure data protection and operational resilience.
Here are just some of the examples:
| Industry | Compliance Standard | Quote from documentation |
| All industries (cross-sectoral); especially IT, finance, manufacturing, and government | ISO/IEC 27001 | “The company performs daily backups and tests recovery periodically,” — Source: Annex A.12.3.1 (Backup) ISO/IEC 27001 |
| Healthcare and health-related service providers (e.g., hospitals, insurers, cloud services handling PHI) | HIPAA | “Consider conducting tests of the incident response plan.” “Implement procedures for the periodic testing and revision of contingency plans.” — Source: HIPAA |
| Financial services, e-commerce, retail, any business processing credit/debit card payments | PCI DSS | “The test of the incident response plan can include simulated incidents and the corresponding responses in the form of a “table-top exercise”, that includes participation by relevant personnel. A review of the incident and the quality of the response can provide entities with the assurance that all required elements are included in the plan.” — Source: PCI DSS |
| Critical infrastructure sectors (energy, healthcare, transport, finance, water, digital infrastructure, and IT service providers) within the EU | NIS 2 Directive | “Each Member State shall adopt a national cybersecurity strategy that provides for the strategic objectives, the resources required to achieve those objectives, and appropriate policy and regulatory measures, with a view to achieving and maintaining a high level of cybersecurity. The national cybersecurity strategy shall include: …e) an identification of the measures ensuring preparedness for, responsiveness to and recovery from incidents, including cooperation between the public and private sectors; “ …“…The provisions of Regulation (EU) 2022/2554 relating to information and communication technology (ICT) risk management, management of ICT-related incidents and, in particular, major ICT-related incident reporting, as well as on digital operational resilience testing, information-sharing arrangements…” — Source: NIS2 |
Get ready for the worst: Disaster Recovery testing scenarios
To have the power of being an every-disaster-scenario-ready organization, you need to foresee any of the events of failure. Here, we speak not only about understanding what those disasters can be but also about creating a well-developed scenario to address them. Why? Because a DR plan isn’t complete until it’s tested across realistic and high-risk scenarios.
So, what can go wrong?
DR testing scenario # 1 – Accidental deletion
Even with the most professional and well-trained team, human error remains one of the top causes of data loss. A simple delete command, misconfigured automation, or overlooked permissions can lead to repositories, metadata, or project data being wiped out. According to Infosec, human mistakes are responsible for 74% of data breaches.
💡 Thus, your plan for DR plan testing should allow you granular restore capabilities, like recovering individual files, repositories, or projects. In this case, you don’t need to restore your entire organization, but recover only the deleted data.
DR testing scenario # 2 – Service outage
Cloud-based providers like GitHub, GitLab, Jira, or Azure DevOps are highly reliable, though everything can happen. Downtime caused by regional outages, DNS failures, or platform bugs can sometimes paralyze your operations and destroy your workflow.
Let’s just recall the Jira outage in April 2024, 700+ organizations couldn’t access their Jira instances for over 2 weeks. Or more recent ones — the GitHub outage in 2024 that left 1000+ developers locked out of their projects, or the Azure DevOps outage that left its customers across North and Latin America taken down.
💡 In this case, it’s critical that you have the possibility to restore your data to an alternative platform. For example, if you use GitHub as your primary solution, you should test to be able to recover to GitLab, Bitbucket, or Azure DevOps, should GitHub be down.
DR testing scenario # 3 – Infrastructure outage
Due to your organization, security or compliance needs, your company might need to use self-hosted DevOps environments, like GitHub Enterprise, Bitbucket Data Center, or GitLab Ultimate. Thus, a hardware failure, power loss, or network disruption can bring your workflow down. In hybrid models, infrastructure dependencies also affect SaaS reliability.
💡 What restore option should you have? Restore to the cloud infrastructure. Also, it’s worth mentioning that you should have a few backup copies, e.g. keep up with the 3-2-1 backup rule. In this case, you will be able to restore your data from the off-site storage, ensuring business continuity.
DR testing scenario # 4 – Ransomware attack or data corruption
Malicious actors actively target DevOps environments, understanding that organizations house their most critical digital assets there. For example, in 2024, dozens of GitHub repositories were compromised by a Gitlocker ransomware attack. In its malicious scheme, the threat actor stole its victim’s GitHub data and demanded a ransom to give the critical data back.
💡 In such a scenario, your organization should have immutable and encrypted backups with ransomware protection. For example, your backup should offer WORM-compliant storage technology, as with it, each file is written once and can be read many times. It helps to prevent data from being modified or deleted.
Moreover, you should have the possibility to restore your data from any point in time. Thus, if your data was corrupted, you can restore it from the copy before the corruption took place.
DR testing scenario # 5 – Insider threat and access compromise
A compromised account or a disgruntled insider can wreak havoc, from code deletion to leaking sensitive data. Especially in environments where integrations and scripts have elevated permissions.
Need an example? In late 2022, Okta, a leading identity and access management (IAM) provider, disclosed that threat actors had gained unauthorized access to its private GitHub repositories. During the breach, attackers managed to copy Okta’s source code. While the company confirmed that no customer data or services were affected, such incidents highlight the real risks to any Git-based repository. In similar attacks, threat actors may not only exfiltrate source code but also attempt to modify or delete it, leading to potential data loss, supply chain threats, and operational disruptions.
💡 It’s important to test your restore abilities after any unauthorized changes. Here, point-in-time restore can be of help, as it allows rolling back to the moment before unauthorized changes happen. Also, it’s critical to have role-based access controls and audit logging.
Best practices for Disaster Recovery testing
We’ve already mentioned that an organization’s Disaster Recovery plan that hasn’t been tested is a plan that doesn’t exist. We should always keep in mind that disaster recovery planning isn’t about “if” there is a failure; it’s more about having proof that your organization can bounce back once the event of disaster occurs.
Let’s come to the key best practices that make your disaster recovery testing effective, efficient, and aligned with the strictest compliance requirements and your business goals:
Tip 1: Have regular Disaster Recovery testing
It’s not a secret that annual DR tests are no longer enough. Cloud environments change rapidly, and so should your testing. Make sure to schedule DR drills at least quarterly. However, if there is a major infrastructure, tooling, or configuration change, it’s worth doing a DR plan test right after it. Such consistency may help your organization uncover vulnerabilities before an event of disaster happens.
Tip 2: Simulate real-world disaster scenarios
There are no two incidents that are exactly the same; unfortunately, real-world threats don’t follow a template. So, don’t just “check the box” with common case tests. Try to run simulations based on actual threats, like ransomware attacks, accidental deletions, cloud outages, or other threats. In this case, your team will learn not only how to restore data but also how to respond to real-world threat scenarios.
Tip 3: Validate your RPOs and RTOs
The average cost of downtime can soar as high as $9K per minute. That’s why validating your RPOs and RTOs (Recovery Point Objective and Recovery Time Objective) is a critical part of every DR test, as fast recovery can save your organization a fortune.
During each test, ask yourself: “Is our recovery fast enough?” and “Are we losing more data than our business can tolerate?”. Answering those questions will help you to fine-tune your DR strategy and ensure your objectives align with business SLAs and compliance requirements.
Tip 4: Involve cross-functional teams in DR testing
When disaster strikes, it affects not only your organization’s infrastructure but also impacts business continuity, customer experience, and compliance. Thus, it’s important to include representatives from security, DevOps, legal, and leadership in Disaster Recovery drills.
This cross-functional approach will help you ensure that technical recovery aligns with broader business priorities, legal obligations, and customer communication strategies.
Tip 5: Document, debrief, and improve your Disaster Recovery plan
Make sure that every Disaster Recovery testing ends with a debrief, when you analyze the outcome of the operations you performed.
It may include the answer to such questions as:
- What did we do during the Disaster Recovery testing?
- What worked?
- Where did delays, confusion, or gaps occur?
Using these insights will help you update your DR documentation, adjust your Recovery Time Objective and Recovery Point Objective if needed, and enhance training or tooling. Let’s not forget, continuous improvement is key to resilience.
Top methods to test your Disaster Recovery strategy
We’ve already covered the Disaster Recovery testing best practices; however, there are some methods that can help you test your Disaster Recovery strategy:
| Method | What it is | Why it matters |
| Tabletop exercises | A discussion-based session where your team walks through a simulated disaster scenario | It can help to review roles, responsibilities, and communication workflows without disrupting business operations. Here you can find some gaps in cross-department communication and understanding. |
| Walkthrough testing | A step-by-step review of Disaster Recovery procedures with your technical team | It can help you verify if the documentation is up to date. Moreover, it helps your teams to familiarize themselves with the recovery process before an actual incident strikes. |
| Simulation testing | A full or partial simulation of a disaster (e.g. ransomware attack, service outage, accidental deletion) | With it, you can validate if RTO and RPO are met, stress-test your infrastructure, and see how your team coordinates under pressure. |
| Parallel testing | A run of recovery systems alongside production without impacting day-to-day operations | It can allow you to test restore processes on standby systems, ensuring they work without disrupting live environments. |
| Full interruption testing | A controlled shutdown of production systems to test complete failover and recovery | This is the most comprehensive (and risky) method. It’s best suited for mature, highly resilient environments where full-scale validation is critical. |
How GitProtect helps to meet compliance and DR testing requirements
Backup is the foundation of every effective Disaster Recovery plan. With GitProtect.io, a compliance-ready backup and Disaster Recovery solution tailored for DevOps and project management environments, organizations can align with both security best practices and regulatory expectations.
“As the Founder of Legal Aspirations, which is an e-commerce business, it was important for me to ensure that my data is secure and recoverable in the event of any data loss. “ — that’s what Li-Yen Poon, Founder of Legal Aspirations said, choosing GitProtect backup and Disaster Recovery solution to ptotect their GitHub environemnt.
📌 You can read the full case study here — Legal Aspirations adopted GitProtect backups to ensure cyber resilience
With its wide range of security and data protection features, GitProtect empowers organizations to build a robust, compliance-aligned DR strategy by offering:
- automated, scheduled backups, with customizable frequency to meet your business continuity needs,
- near real-time protection with minimal gaps between backups to support strict RPOs and RTOs,
- unlimited retention policies to meet long-term compliance obligations (e.g., SOC 2, ISO 27001, HIPAA, etc.),
- multi-storage support — local, hybrid, BYO cloud (e.g., AWS S3), or free GitProtect Cloud,
- centralized monitoring and reporting to track backup performance and validate test outcomes,
- immutable and encrypted backups, including customer-owned keys, to support ransomware protection,
- every-scenario-ready Disaster Recovery technology that allows full recovery or granular restore, point-in-time restore, the widest range of restore destinations — restore to your local device, to the same or a new account, cross-restore between platforms (GitHub, Bitbucket, GitLab, Azure DevOps) and deployments (cloud and on-prem).
With such flexible disaster recovery capabilities, your organization can confidently restore data after any possible disaster scenario, including accidental deletions, service outage, your infrastructure downtime, or ransomware attack.
Moreover, GitProtect makes Disaster Recovery testing fast and simple, enabling teams to simulate various scenarios and validate recovery workflows in just a few clicks.
“Performing test restores is easy and we can send them to different providers. Huge improvement”
Mark Pace, CTO, Red5
📌 Read the full story on how Red5 adopted GitProtect backups for GitHub and Jira to meet its compliance
Use Case — How to test Disaster Recovery with GitProtect
Testing your Disaster Recovery plan with GitProtect is straightforward and efficient. Let’s walk through a DR test scenario using GitLab as the source platform.
Log in to your GitProtect dashboard and select the environment you want to restore. In this case, we will go with GitLab:
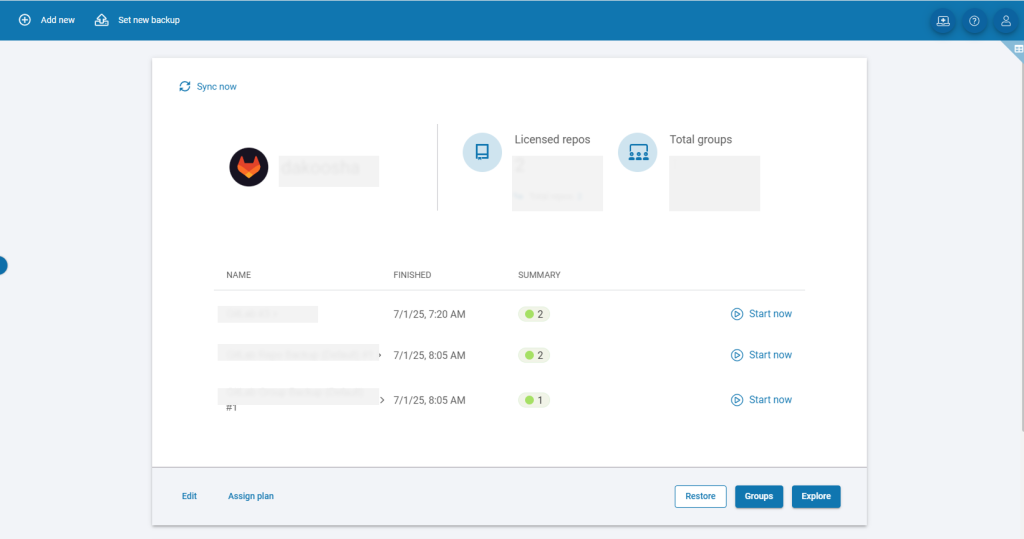
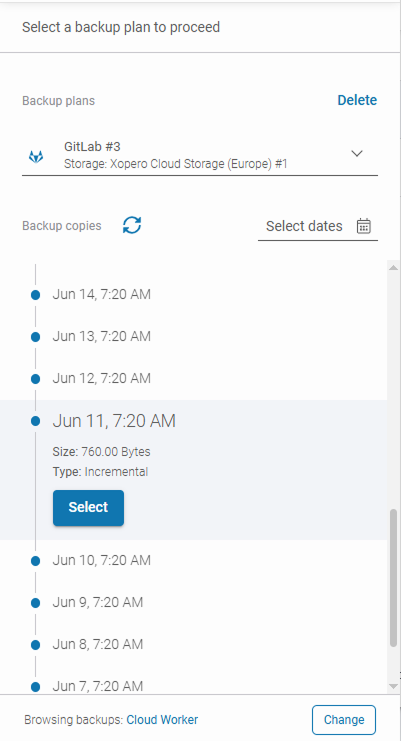
Then, click the “Restore” button, and choose the backup plan you need to restore and the point in time to restore your data from. For example, in the event of a ransomware attack, restoring from an earlier backup (before the compromise took place) is often safer than using the most recent one.
In our use case, we decided to restore an earlier backup copy:
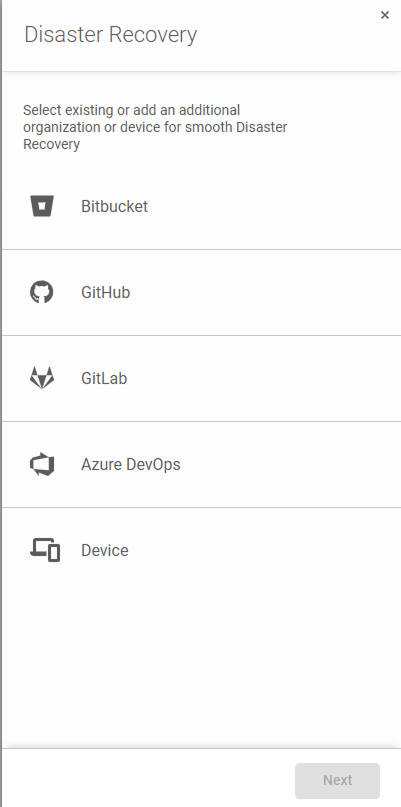
Then, select where you want to restore your data:
- For a service outage, you can restore to a different Git hosting provider (e.g., GitLab to GitHub, Bitbucket, or Azure DevOps).
- For accidental deletions, you might restore to the same platform.
In our use case test, we’ll restore to the same GitLab instance:
Then, you will need to choose the data you want to restore during your Disaster Recovery testing. GitProtect allows you to restore your entire environment or perform granular recovery, choosing specific repositories or metadata. For this scenario, we’re running a full GitLab recovery:
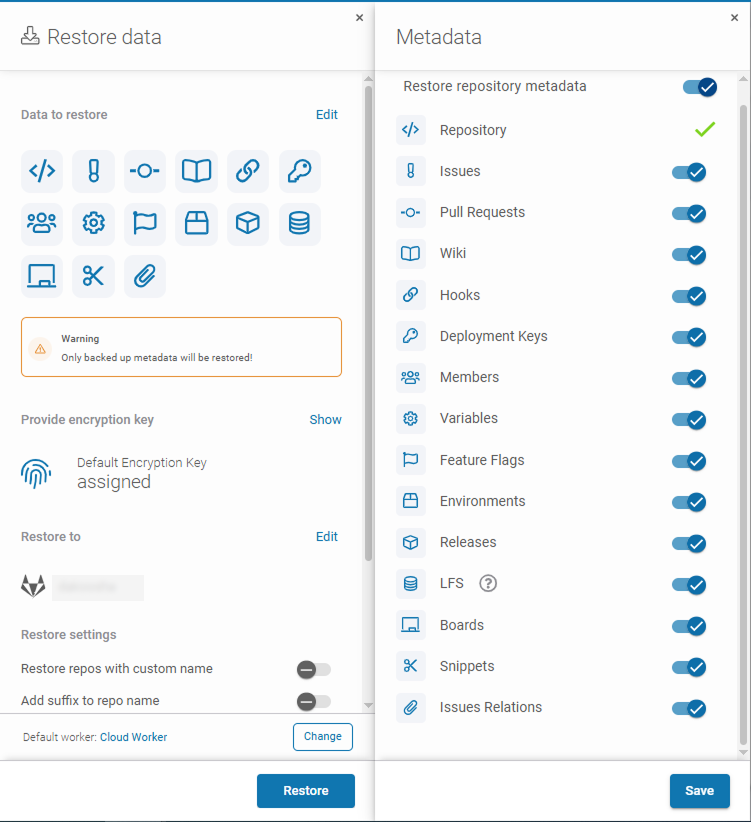
And, finally, after clicking the “Restore” button, your backup will be restored to the destination you pointed out. As we did the test restore, we need to check the restore operation process — if it’s finished well, with warnings ot with errors. In our case, the test restore was completed successfully:

We restored our GitLab data to the same GitLab instance, so we can check our GitLab and see the restored data:

Simple, as it said. In just a few clicks, we can test our Disaster Recovery process in different scenarios:
- accidental deletion – you can use granular restore and recover your data to the same or a new GitHub/Bitbucket/GitLab/Azure DevOps account.
- compromised data – you can use point-in-time restore to recover your critical data to the same or a new account.
- service outage – you can use cross-over restore and recover your DevOps data to another git hosting service.
- Infrastructure outage – GitProtect allows you to back up to multiple locations (to follow the 3-2-1 backup rule), so you can restore your data from any point in time from another storage, even if your infrastructure is down.
Learn more about best practices to build your Disaster Recovery strategy:
📌 GitHub Disaster Recovery and GitHub restore – scenarios & use cases
📌 Bitbucket Disaster Recovery best practices
📌 Azure DevOps restore and Disaster Recovery
📌 GitLab restore and Disaster Recovery — how to eliminate data loss
📌 Jira restore and DR: scenarios and use cases
Takeaway
A Disaster Recovery plan that hasn’t been tested is a plan that doesn’t exist. Relying on outdated recovery assumptions can cost the organization thousands per minute, or even worse, compliance violations and lost trust. That’s why regular disaster scenario-based testing is essential.
With GitProtect, testing can become simple and aligned with both business continuity and regulatory demands. The real resilience is built before a disaster, not after.
[FREE TRIAL] Ensure compliant DevOps backup and recovery with a 14-day trial 🚀
[CUSTOM DEMO] Let’s talk about how backup & DR software for DevOps can help you mitigate the risks



